原文:
SQL Server 查找统计信息的采样时间与采样比例
有时候我们会遇到,由于统计信息不准确导致优化器生成了一个错误的执行计划(或者这样表达:一个较差的执行计划),从而引起了系统性能问题。那么如果我们怀疑这个错误的执行计划是由于统计信息不准确引起的。那么我们如何判断统计信息不准确呢?当然首先得去查看实际执行计划中,统计信息的相关数据是否与实际情况有较大的出入,下面我们抛开这个大命题,仅仅从统计信息层面去查看统计信息的更新时间,统计信息的采样行数、采样比例等情况。
1:首先,我们要查查统计信息是什么时候更新的。
2:其次,我们查看统计信息的采样的百分比以及采样信息:采样选取的行数、自上次更新统计信息以来前导统计信息列(构建直方图的列)的总修改次数。。。
查看统计信息的最后更新时间。
方法1:
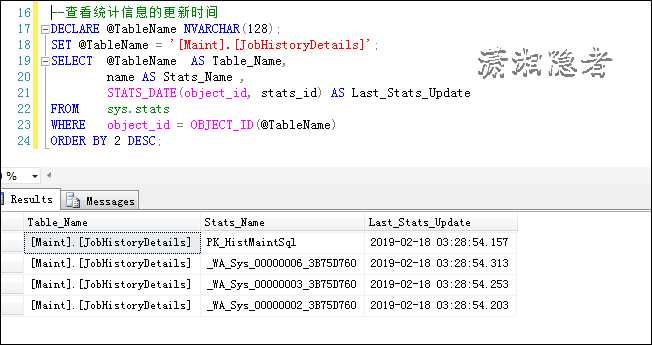
--查看统计信息的更新时间
DECLARE @TableName NVARCHAR(128);
SET @TableName = ‘[Maint].[JobHistoryDetails]‘;
SELECT @TableName AS Table_Name,
name AS Stats_Name ,
STATS_DATE(object_id, stats_id) AS Last_Stats_Update
FROM sys.stats
WHERE object_id = OBJECT_ID(@TableName)
ORDER BY 2 DESC;
如上所示,我们通过这个脚本查看某个表所有的统计信息的最后一次更新时间。如果你需要查看某个具体的统计信息的最后更新时间,那么在这个SQL的基础上修改相关查询条件即可。
方法2:
—查看统计信息的更新时间
EXEC sp_autostats ‘[Maint].[JobHistoryDetails]‘;
方法3:
还有一种方法可以通过 sys.dm_db_stats_properties 返回统计信息的更新时间,不过这个DMF只有SQL Server 2008 R2 SP2这个版本之后的才有。
|
列名 |
数据类型 |
Description |
|
object_id |
int |
要返回统计信息对象属性的对象(表或索引视图)的 ID。 |
|
stats_id |
int |
统计信息对象的 ID。 在表或索引视图中是唯一的。 有关详细信息,请参阅 sys.stats (Transact-SQL)。 |
|
last_updated |
datetime2 |
上次更新统计信息对象的日期和时间。 有关详细信息,请参阅此页中的备注部分。 |
|
rows |
bigint |
上次更新统计信息时表或索引视图中的总行数。 如果筛选统计信息或者统计信息与筛选索引对应,该行数可能小于表中的行数。 |
|
rows_sampled |
bigint |
用于统计信息计算的抽样总行数。 |
|
Step |
int |
直方图中的值范围数(步长)(Number of steps in the histogram)。 有关详细信息,请参阅 DBCC SHOW_STATISTICS (Transact-SQL)。 |
|
unfiltered_rows |
bigint |
应用筛选表达式(用于筛选的统计信息)之前表中的总行数。 如果未筛选统计信息,则 unfiltered_rows 等于行列中返回的值。 |
|
modification_counter |
bigint |
自上次更新统计信息以来前导统计信息列(构建直方图的列)的总修改次数。 内存优化表: 正在启动SQL Server 2016 (13.x)并在Azure SQL Database此列包含: 修改因为最后一个时间统计信息已更新或重新启动数据库的表的总次数。 |
|
persisted_sample_percent |
float |
持久样本百分比用于未显式指定采样百分比的统计信息更新。 如果值为零,则不为此统计信息设置持久样本百分比。 适用范围:SQL Server 2016 (13.x) SP1 CU4 |
SELECT sch.name + ‘.‘ + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.rows_sampled*1.0/ds.rows *100 AS sample_rate
, ds.steps
, ds.unfiltered_rows
--, ds.persisted_sample_percent
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.is_ms_shipped = 0
AND so.object_id NOT IN (
SELECT major_id
FROM sys.extended_properties (NOLOCK)
WHERE name = N‘microsoft_database_tools_support‘ );
查看统计信息采样的百分比
SELECT sch.name + ‘.‘ + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.steps
, ds.unfiltered_rows
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.name = N‘pbCutClothCost‘
AND LEFT(ss.name, 4) != ‘_WA_‘;
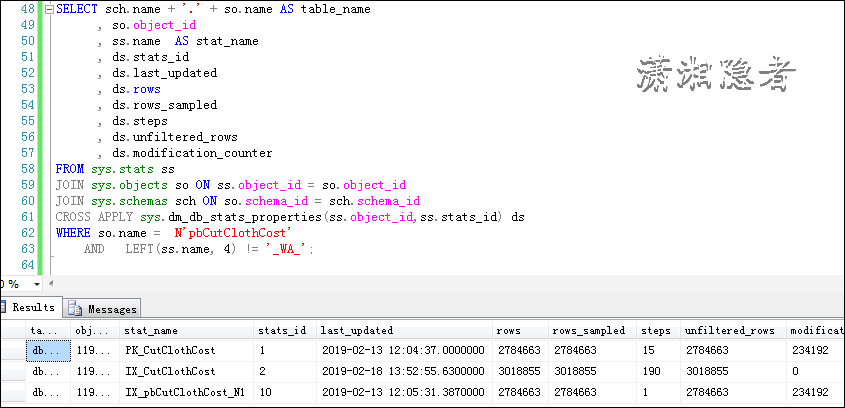
如上截图,索引IX_CutClothCost的统计信息有更新,是因为在执行上面脚本前,我更新了这个统计信息。通过rows与实际记录数对比、 modification_counter信息,我们从而有个大概的判断,这些统计信息是否过时。是否采样的比例太小。如果查看统计信息的采样百分比,那么可以使用下面脚本。
SELECT sch.name + ‘.‘ + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.rows_sampled*1.0/ds.rows *100 AS sample_rate
, ds.steps
, ds.unfiltered_rows
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.name = N‘pbCutClothCost‘
AND LEFT(ss.name, 4) != ‘_WA_‘;
查看整个数据库的所有用户表的采样比例,可以使用下面脚本
--适应于SQL Server 2016 (13.x) SP1 CU4之前的版本
SELECT sch.name + ‘.‘ + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.rows_sampled*1.0/ds.rows *100 AS sample_rate
, ds.steps
, ds.unfiltered_rows
--, ds.persisted_sample_percent
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.is_ms_shipped = 0
AND so.object_id NOT IN (
SELECT major_id
FROM sys.extended_properties (NOLOCK)
WHERE name = N‘microsoft_database_tools_support‘ );
当然也可以使用DBCC SHOW_STATISTICS来查看统计信息的详细信息。
DBCC SHOW_STATISTICS (‘dbo.pbCutClothCost‘, IX_pbCutClothCost_N1)
查看统计信息是否需要更新
判断统计信息是否过时的一个维度:统计信息最后更新的时间,通过时间维度(最后一次统计信息更新距今的时间)。这个对于下面的维度(修改的数据数量)而言,往往不是特别准确,但是也有参考意义。
SELECT
sch.name + ‘.‘ + so.name AS "Table",
ss.name AS"Statistic",
CASE
WHEN ss.auto_Created = 0 AND ss.user_created = 0 THEN ‘Index Statistic‘
WHEN ss.auto_created = 0 AND ss.user_created = 1 THEN ‘USER Created‘
WHEN ss.auto_created = 1 AND ss.user_created = 0 THEN ‘Auto Created‘
WHEN ss.AUTO_created = 1 AND ss.user_created = 1 THEN ‘Not Possible‘
END AS
"Statistic Type",
CASE
WHEN ss.has_filter = 1 THEN ‘Filtered INDEX‘
WHEN ss.has_filter = 0 THEN ‘No Filter‘
END AS "Filtered",
CASE
WHEN ss.filter_definition IS NULL THEN ‘‘
WHEN ss.filter_definition IS NOT NULL THEN ss.filter_definition
END AS "Filter Definition",
sp.last_updated AS "Stats Last Updated",
sp.rows AS "Rows",
sp.rows_sampled AS "Rows Sampled",
sp.unfiltered_rows AS "Unfiltered Rows",
sp.modification_counter AS "Row Modifications",
sp.steps AS "Histogram Steps"
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
OUTER APPLY sys.dm_db_stats_properties(so.object_id, ss.stats_id) AS sp
WHERE so.TYPE = ‘U‘
AND sp.last_updated < GETDATE() - 7
ORDER BY sp.last_updated DESC;
以前收集过一个查询过时的统计信息(忘记出自哪里了),自己对脚本做过调整、修改,这个是通过自上次统计信息更新以来,变化的行数超过某个阀值来判断统计信息是否过时。如下所示
Max(ApproximateRows) > 500 AND Max(RowModCtr) > (Max(ApproximateRows)*0.2 + 500 )
1:如果是SQL Server 2008 R2 SP2以上的版本,使用sys.dm_db_stats_properties的modification_counter字段值:自上次更新统计信息以来前导统计信息列(构建直方图的列)的总修改次数
2:如果是SQL Server 2008 R2 SP2之前的版本,使用sysindexes的rowmodctr字段值:对自上次更新表的统计信息后插入、删除或更新行的总数进行计数。
SET TRAN ISOLATION LEVEL READ UNCOMMITTED;
DECLARE @product_version NVARCHAR(128),
@db_version NVARCHAR(32) ,
@edition INT,
@small_edition INT,
@sql_script_index INT;
SET @product_version = CAST(SERVERPROPERTY(‘ProductVersion‘) AS NVARCHAR(128));
--版本为10.50.4000或高于这个版本使用sys.dm_db_stats_properties这个DMV,否则使用sysindexes中的rowmodctr字段
SELECT @db_version=
CASE
WHEN @product_version like ‘8%‘ THEN ‘SQL2000‘
WHEN @product_version like ‘9%‘ THEN ‘SQL2005‘
WHEN @product_version like ‘10.0%‘ THEN ‘SQL2008‘
WHEN @product_version like ‘10.5%‘ THEN ‘SQL2008 R2‘
WHEN @product_version like ‘11%‘ THEN ‘SQL2012‘
WHEN @product_version like ‘12%‘ THEN ‘SQL2014‘
WHEN @product_version like ‘13%‘ THEN ‘SQL2016‘
WHEN @product_version like ‘14%‘ THEN ‘SQL2017‘
ELSE ‘unknown‘
END
SET @edition= SUBSTRING(@db_version, 4, 4)
IF @edition <=2005
SET @sql_script_index=0;
ELSE IF @edition = 2008
IF @db_version =‘SQL2008 R2‘AND CAST(SUBSTRING(@product_version,7, 4) AS INT) >= 4000
SET @sql_script_index =1;
ELSE
SET @sql_script_index =0;
ELSE
SET @sql_script_index=1;
IF @sql_script_index = 0
BEGIN
PRINT ‘0‘
EXEC sp_executesql N‘;WITH StatTables AS(
SELECT obj.schema_id AS ‘‘schema_id‘‘
,obj.name AS ‘‘table_name‘‘
,obj.object_id AS ‘‘object_id‘‘
,CASE INDEXPROPERTY(obj.object_id, dmv.name, ‘‘IsStatistics‘‘)
WHEN 0 THEN dmv.rows
ELSE (SELECT TOP 1 row_count FROM sys.dm_db_partition_stats ps (NOLOCK) WHERE ps.object_id=obj.object_id AND ps.index_id in (1,0))
END AS ‘‘approximate_rows‘‘
,dmv.rowmodctr AS ‘‘row_mod_ctr‘‘
FROM sys.objects obj (NOLOCK)
INNER JOIN sysindexes dmv (NOLOCK) ON obj.object_id = dmv.id
LEFT JOIN sys.indexes ind (NOLOCK) ON obj.object_id = ind.object_id AND obj.type in (‘‘U‘‘,‘‘V‘‘) AND ind.index_id = dmv.indid
WHERE obj.is_ms_shipped = 0 --object is not created by an internal sql server component
AND dmv.indid<>0
AND obj.object_id NOT IN (SELECT major_id FROM sys.extended_properties (NOLOCK) WHERE name = N‘‘microsoft_database_tools_support‘‘)
),
StatTableGrouped AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY table_name) AS seq1
,ROW_NUMBER() OVER(ORDER BY table_name DESC) AS seq2
,table_name AS table_name
,CAST(MAX(approximate_rows) AS BIGINT) AS approximate_rows
,CAST(MAX(row_mod_ctr) AS BIGINT) AS row_mod_ctr
,schema_id
,object_id
FROM StatTables st
GROUP BY schema_id,object_id,table_name
HAVING (MAX(approximate_rows) > 500
AND MAX(row_mod_ctr) > (MAX(approximate_rows)*0.2 + 500 ))
)
SELECT
@@SERVERNAME AS instance_name
,seq1 + seq2 - 1 AS occurences_num
,SCHEMA_NAME(stg.schema_id) AS ‘‘schema_name‘‘
,stg.table_name
,CASE OBJECTPROPERTY(stg.object_id, ‘‘TableHasClustIndex‘‘)
WHEN 1 THEN ‘‘Clustered‘‘
WHEN 0 THEN ‘‘Heap‘‘
ELSE ‘‘Indexed View‘‘
END AS clustered_or_heap
,CASE OBJECTPROPERTY(stg.object_id, ‘‘TableHasClustIndex‘‘)
WHEN 0 THEN (SELECT COUNT(*) FROM sys.indexes i (NOLOCK) WHERE i.object_id= stg.object_id) - 1
ELSE (SELECT COUNT(*) FROM sys.indexes i (NOLOCK) WHERE i.object_id= stg.object_id)
END AS IndexCount
,(SELECT COUNT(*) FROM sys.columns c (NOLOCK) WHERE c.object_id = stg.object_id ) AS columns_count
,(SELECT COUNT(*) FROM sys.stats s (NOLOCK) WHERE s.object_id = stg.object_id) AS stats_count
,stg.approximate_rows
,stg.row_mod_ctr
,stg.schema_id
,stg.object_id
FROM StatTableGrouped stg‘;
END;
ELSE
BEGIN
EXEC sp_executesql N‘
;WITH StatTables AS(
SELECT obj.schema_id AS schema_id
,obj.name AS table_name
,obj.object_id AS object_id
,ISNULL(sp.rows,0) AS approximate_rows
,ISNULL(sp.modification_counter,0) AS row_mod_ctr
FROM sys.objects obj (NOLOCK)
JOIN sys.stats st (NOLOCK) ON obj.object_id=st.object_id
CROSS APPLY sys.dm_db_stats_properties(obj.object_id, st.stats_id) AS sp
WHERE obj.is_ms_shipped = 0
AND st.stats_id<>0
AND obj.object_id NOT IN (
SELECT major_id FROM sys.extended_properties WITH(NOLOCK)
WHERE name = N‘‘microsoft_database_tools_support‘‘)
),
StatTableGrouped AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY table_name) AS seq1,
ROW_NUMBER() OVER(ORDER BY table_name DESC) AS seq2,
table_name AS table_name,
CAST(MAX(approximate_rows) AS BIGINT) AS approximate_rows,
CAST(MAX(row_mod_ctr) AS BIGINT) AS row_mod_ctr,
COUNT(*) AS stats_count,
schema_id AS schema_id,
object_id AS object_id
FROM StatTables st
GROUP BY schema_id,object_id,table_name
HAVING (MAX(approximate_rows) > 500 AND Max(row_mod_ctr) > (Max(approximate_rows)*0.2 + 500 ))
)
SELECT
@@SERVERNAME AS instance_name
,seq1 + seq2 - 1 AS occurences_num
,SCHEMA_NAME(stg.schema_id) AS schema_name
,stg.table_name
,CASE OBJECTPROPERTY(stg.object_id, ‘‘TableHasClustIndex‘‘)
WHEN 1 THEN ‘‘Clustered‘‘
WHEN 0 THEN ‘‘Heap‘‘
ELSE ‘‘Indexed View‘‘
END AS clustered_or_heap
,CASE OBJECTPROPERTY(stg.object_id, ‘‘TableHasClustIndex‘‘)
WHEN 0 THEN (SELECT COUNT(*) FROM sys.indexes i WITH(NOLOCK) WHERE i.object_id= stg.object_id) - 1
ELSE (SELECT COUNT(*) FROM sys.indexes i WITH(NOLOCK) WHERE i.object_id= stg.object_id)
END AS IndexCount
,(SELECT COUNT(*) FROM sys.columns c (NOLOCK) WHERE c.object_id = stg.object_id ) AS columns_count
,stg.stats_count
,stg.approximate_rows
,stg.row_mod_ctr
,stg.schema_id
,stg.object_id
FROM StatTableGrouped stg‘;
END;
参考资料:
https://www.sqlskills.com/blogs/erin/new-statistics-dmf-in-sql-server-2008r2-sp2/