1.题目:
 源码:
源码:
import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession import org.apache.spark.sql.DataFrameReader object TestMySQL { def main(args: Array[String]) { val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate() import spark.implicits._ val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" ")) val schema = StructType(List(StructField("id", IntegerType,true),StructField("name", StringType, true),StructField("gender", StringType,true),StructField("age", IntegerType, true))) val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).trim,p(3).toInt)) val employeeDF = spark.createDataFrame(rowRDD, schema) val prop = new Properties() prop.put("user", "root") prop.put("password", "hadoop") prop.put("driver","com.mysql.jdbc.Driver") employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest","sparktest.employee", prop) val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "hadoop").load() jdbcDF.agg("age" -> "max", "age" -> "sum").show() print("ok") } }
数据库数据: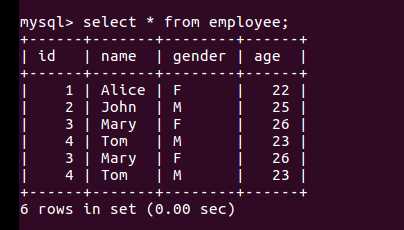
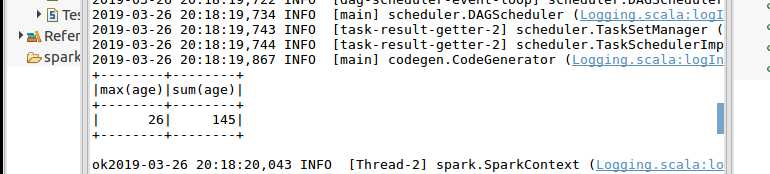
结果:
2.编程实现将 RDD 转换为 DataFrame

官网给出两种方法,这里给出一种(使用编程接口,构造一个 schema 并将其应用在已知的 RDD 上。):
源码:
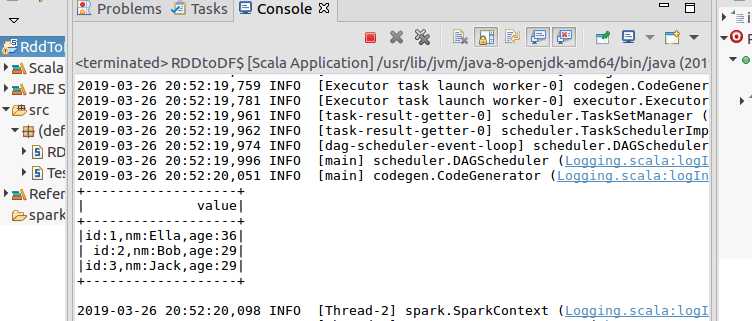
import org.apache.spark.sql.types._ import org.apache.spark.sql.Encoder import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession object RDDtoDF { def main(args: Array[String]) { val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate() import spark.implicits._ val employeeRDD =spark.sparkContext.textFile("file:///usr/local/spark/employee.txt") val schemaString = "id name age" val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) val schema = StructType(fields) val rowRDD = employeeRDD.map(_.split(",")).map(attributes => Row(attributes(0).trim, attributes(1), attributes(2).trim)) val employeeDF = spark.createDataFrame(rowRDD, schema) employeeDF.createOrReplaceTempView("employee") val results = spark.sql("SELECT id,name,age FROM employee") results.map(t => "id:"+t(0)+","+"name:"+t(1)+","+"age:"+t(2)).show() } }
结果: