前端
windos
微信
数据库
移动开发
技术杂谈
评论
webpack5
# 前端
2024-05-05 04:43
0
108
来源:
云博客
webpack5安装: cnpm i webpack@next webpack-cli –D
webpack4 和 webpack5的区别:
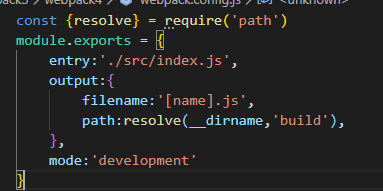
webpack4:
webpack5 省略了默认的配置
打包的体积变小的
webpack4:
webpack5:
webpack5打包使用了,匿名自调用函数 和 严格语法
webpack5重点关注一下内容:
1. 需要手动添加 引入 node模块
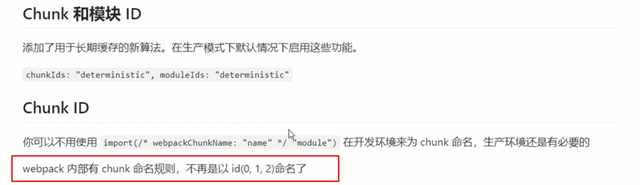
2. webpack内部命名规则 ,
3.
*Tree Shaking(树摇)
4. Output, 指定输出版本
设置代码分割, 文件超过30kb, 就分割成多个文件
5. 长久缓存 ,让第二次打包性能更加高效
6. 监视输出的文件
7.默认值:
网址:
https://github.com/webpack/changelog-v5
0
相关文章
36.VUE — 认识 Webpack 和 安装
nginx + http + svn
kubernets kube-proxy的代理 iptables和ipvs
基于Docker搭建 Php-fpm + Nginx 环境
.net 5+ 知新:【1】 .Net 5 基本概念和开发环境搭建
Three.js中显示坐标轴、平面、球体、四方体
云博小周宇
投稿者
96804 篇文章
0 条评论
最近文章
数据格式转换 (三)Office文档转HTML
【转】Node.js到底是用来做什么的
20164317《网络对抗技术》Exp9 Web安全基础
linux web站点常用压力测试工具httperf
JSOI2016 最佳团体
Node.js 事件触发器详细总结
仿 MVC 三大特性
如何搭建一个简易的Web框架
js 原型里面写方法
css里的BFC用法
html之input
Apache开启GZIP压缩功能方法
Node.js 命令行工具的编写
前端性能优化成神之路-HTTP压缩开启gzip
How to use NetSuite SDF to download bundles/components
前端 HTML文档 详解
webstorm 支持vue element-ui 语法高亮属性自动补全
从零开始搭建服务器部署web项目
node.js密码加密实践
四: 使用vue搭建网站前端页面