最近在做的一个项目里传输的json数据比较大,造成了线程间的卡顿,于是想优化一下json数据的体积。
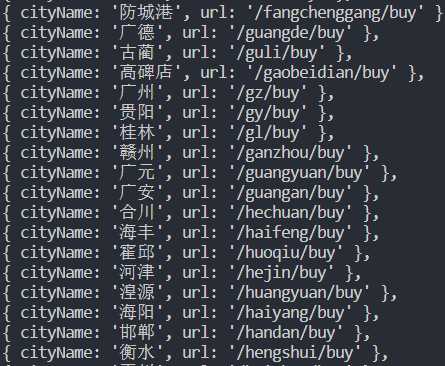
可以看到在json文件里有很多无用的字段,这些字段占据了大量的存储空间。
对数据的结构作一下优化,如下
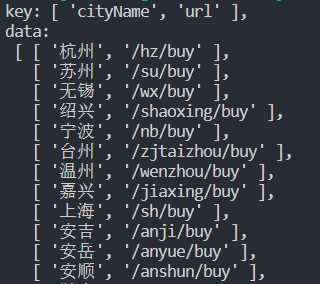
将对象的key值单独存在一个数组里,value值存在另一个数组。
调整数据结构后体积的变化也非常明显,减少了40%的体积。

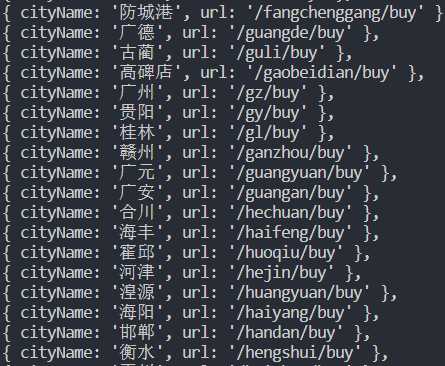
最近在做的一个项目里传输的json数据比较大,造成了线程间的卡顿,于是想优化一下json数据的体积。
可以看到在json文件里有很多无用的字段,这些字段占据了大量的存储空间。
对数据的结构作一下优化,如下
将对象的key值单独存在一个数组里,value值存在另一个数组。
调整数据结构后体积的变化也非常明显,减少了40%的体积。