背景:公司产品是用electron做的pc端。底层基于Chromium 和 node.js。 公司的产品有一个运用场景是进行某些操作。需要后台向前端推送一些消息。
因此我们采用websockets来保持服务器和前端的通信。
问题点:sockets在连接一段时间后会自动断开。后台向前端推送的消息前端无法接收到。
初步排查判断是因为自动重连失效。但是本身websockets就是基于tcp的。本身socket就有保持连接的能力。 我们通过wireshark的查看tcp的日志发现sockets是有在做重连。
后台也确实保持着状态。 我们前端加入循环判断。只要断开就自动重连。但是通过日志我们发现有个很奇怪的现象断开时间都是8分钟。排查后才发现每隔一段时间断开是因为
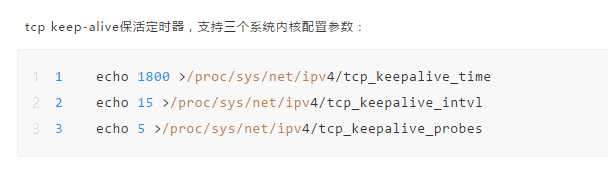
服务器内核设置的问题。
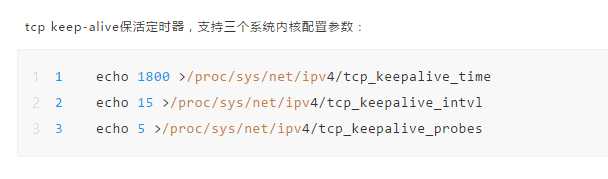
我们修改了内核设置参数。将服务器内核时间调到7200秒也就是两小时。 但是后面在实际业务场景中用户会有把客户端打开两个小时不操作的情况。
再次操作时socket已经断开再也无法连接上。 我们想到一个方案前端每重连10次就重新建立一个新的连接。这个方案我们测试了在服务器上部署跑了72小时没有出现断开了再也连接不上的问题。