


- Windows 7 Ultimate, 64-bit 6.1.7601, Service Pack 1(实体机,虚拟机VMware的宿主机)
- VMware® Workstation 7.1.4 build-385536
- Fedora 16 x86_64(Git服务器,是上学时候安装的虚拟机,已经整整8年了,老了唉)
- Windows 10 v1511 x64(实体机,测试外网连接git服务器)
- Git(自行编译/下载)
- Apache(自行编译/下载)
- gitweb(自行编译/下载)
有兴趣的同学可以去研究下《HTTP权威指南》,这本书不算薄(手动滑稽)。
其实不单是HTTP协议,所有网络协议都可以被概括为
“为了传送指定的数据,网络中发送数据的一端要和接受数据的一端约定一个相同的数据格式,这个数据格式就是所谓的协议”。
从广义上来讲,所有人都可以制定协议,只是市面上大家一起用的就那么几个而已,所以HTTP也同样没那么神秘。
”超文本传输??协议(HTTP)是用于传输诸如HTML的超媒体文档的应用层协议。它被设计用于Web浏览器和Web服务器之间的通信,但它也可以用于其他目的。 HTTP遵循经典的客户端-服务端模型,客户端打开一个连接以发出请求,然后等待它收到服务器端响应。 HTTP是无状态协议,意味着服务器不会在两个请求之间保留任何数据(状态)。虽然通常基于TCP / IP层,但可以在任何可靠的传输层上使用; 也就是说,一个不会静默丢失消息的协议,如UDP。“
HTTP在大部分人眼里的用途就是在Web浏览器中输入一个URL(网站地址),然后Web浏览器中就会呈现出一个五彩缤纷的世界(网页),所以很大一部分就出现了思维定势,认为HTTP就是用来做网站的协议,然而这种认知是非常错误的,事实上HTML只是搭载HTTP服务器传输给客户机的一种文档而已,HTML可以由类似php、python、perl等语言动态生成,当然也可以是提前编辑好的HTML文档,HTML传输到客户机之后,大量的工作都是由Web浏览器去做,Web浏览器会去解析HTML文档,然后以图形、文字或视频的形式在浏览器中经行渲染输出,丰富信息,以达到友好的人机交互。
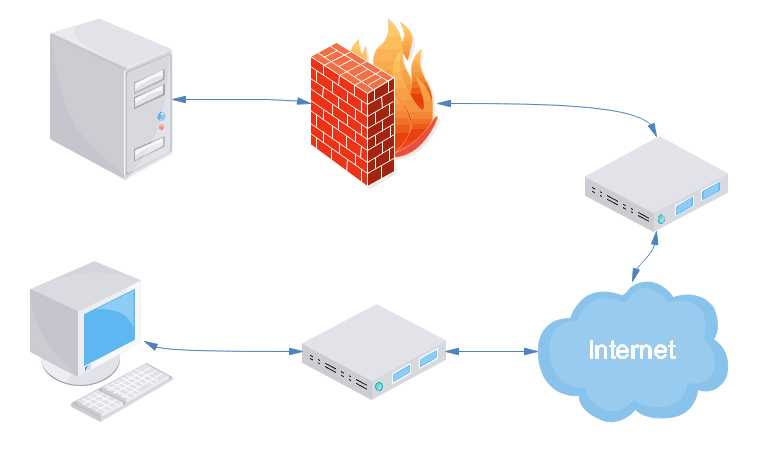
然而事实上,你可以用HTTP可以去传送任何你想要的数据,只要发送/接收端有能力处理这些数据的方法(程序),这就是为什么sample.git明明是git建立的一个文件夹,却可以包含到URL中(http://www.web-site.com/sample.git),git客户端可以将此URL设为远程库,从而在此库上进行一系列的git操作(clone、commit等),因为git服务端有cgi脚本,通过perl-cgi解析sample.git目录中的git信息,将git信息解释为HTML文档,最后再把HTML文档发送给客户端,就可以通过Web浏览器去查看或管理git库,而客户端的git程序会将URL解析为一个类似本地路径(虽然不是,但是意思一样),路径里包含了所有git信息,要什么数据客户端都会向git服务端请求,然后git服务端将所需要代码等一并传输到git客户端(即下载),所以git客户端就可以依据URL进行git的克隆、提交等操作。
git自身也提供网页化服务功能,依赖轻型http服务程序,管理员就可以轻松做出一个git的web站点,只是如果作为web形式长期访问的话,用apache或者nginx搭建一个比较好。
git的SSH服务器搭建比较简单,就不再赘述,搭建过程中只需要注意两点:确保SSH服务正常运行,防火墙将SSH(端口一般为22)设为信任,剩下的就按照官方文档配置就行。
- 配置监听端口
[root@Fedora ~]# vim /etc/httpd/conf/httpd.conf
找到“Listen”块,配置
Listen 8080
因为我的80端口被nginx占用了,所以用了8080,注意tomcat可能将8080占用,这时候你的机器上就要配置一个未被占用的端口为apache监听端口。
- 模块及扩展脚本配置
LoadModule dav_module modules/mod_dav.so LoadModule dav_fs_module modules/mod_dav_fs.so LoadModule cgi_module modules/mod_cgi.so
如果上诉三个模块被注释掉的话,就去掉注释,放开模块。
Include /etc/httpd/conf.d/gitweb.conf
在httpd.conf脚本最后加入扩展的配置脚本
- 扩展脚本
[root@Fedora ~]# cd /etc/httpd/conf.d
/etc/httpd/conf.d文件夹中存放的是apache的扩展脚本,如果已经安装git和gitweb,里面应该有一个git.conf脚本,是安装git和gitweb时自动生成的
Alias /git /var/www/git <Directory /var/www/git> Options +ExecCGI AddHandler cgi-script .cgi DirectoryIndex gitweb.cgi </Directory>
但是我们现在要自己搭建一个git服务器,所以就自己自定义一个gitweb.conf脚本,内容如下
Alias /gitweb /home/git/gitweb <Directory /home/git/gitweb> Options +ExecCGI AddHandler cgi-script .cgi DirectoryIndex gitweb.cgi </Directory>
大致和git.conf一样,不一样的地方是HTTP索引变为由/git变为/gitweb,索引指向的目录变为/home/git/gitweb,其中”git”为专门为Git服务端设置的用户名,”gitweb”是存放git库的文件夹,怎么建用户、及git建库,请自行从万能的网络或者书籍获取。
- 重启服务
[root@Fedora ~]# systemctl restart httpd.servic
- 设置cgi脚本
$ cp /var/www/git/gitweb.cgi /home/git/gitweb/gitweb.cgi
$ cp -r /var/www/git/static /home/git/gitweb/static
- Web浏览Git的http服务
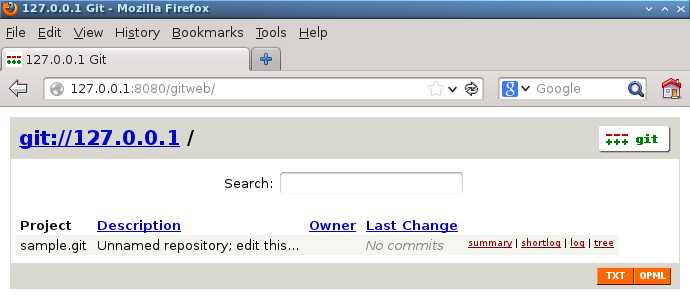
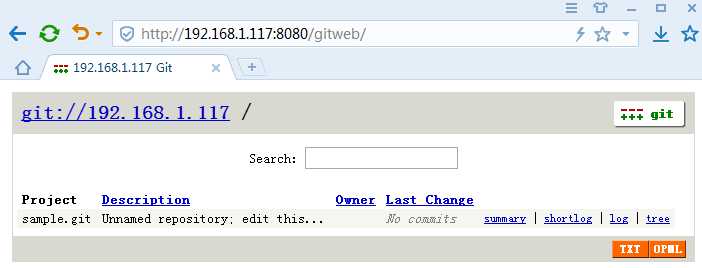
- 服务器本地Web浏览器可以访问HTTP,但是客户机无法访问
[root@Fedora ~]# setup

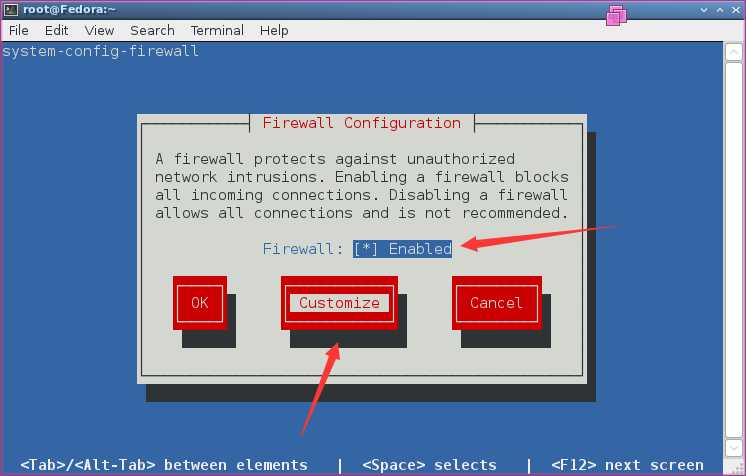
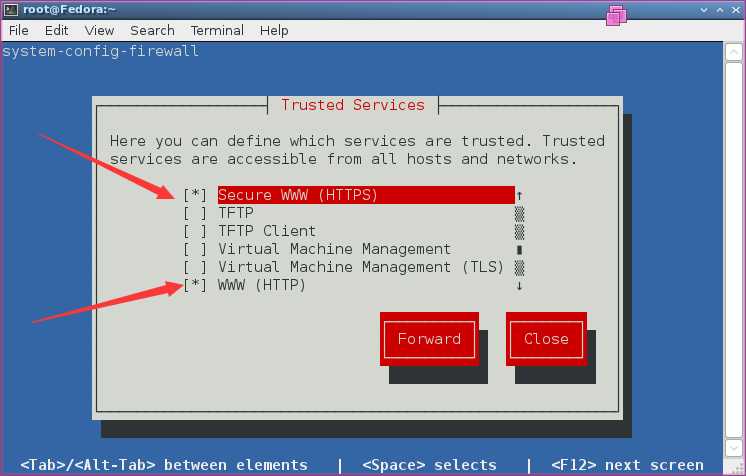
将HTTPS和HTTP设为信任,保存关闭。
然后修改/etc/sysconfig/iptables
[root@Fedora ~]# vim /etc/sysconfig/iptables
将8080端口放开
-A INPUT -m state --state NEW -m tcp -p tcp --dport 8080 -j ACCEPT然后重启防火墙IP端口规则
[root@Fedora ~]# systemctl restart iptables.service
然后http服务就正式对外开放了。
- HTTP可以ping通,但是无访问权限
[root@Fedora ~]# usermod -a -G git apache
确保 apache用户(在httpd.conf中配置的用户)具有访问 gitweb指定代码库的权限,比如, /home/git/gitweb 属于git用户和git组,所以将git添加到apache用户组中,以保证apache对/home/git/gitweb的权限最大化,还是权限不够,那么就直接将git用户的目录权限全部放开(哈哈)
[root@Fedora ~]# chmod 777 /home/git
- 链接