一、简介 主要参考博客:纵览轻量化卷积神经网络
https://zhuanlan.zhihu.com/p/32746221 1, SqueezeNet: SqueezeNet对比AlexNet能够减少50倍的网络参数,但是却拥有相近的性能。SqueezeNet主要强调用1×1的卷积核进行feature map个数的压缩,从而达到大量减少网络参数的目的。在构造网络的时候,采用VGG的堆叠思想。 2, moblieNet: MobileNet采用depth-wise convolution的卷积方式,能够减少参数数量和提升运算速度(运算速度主要靠创新性的计算方式达到)。MobileNet将传统的卷积分为两步:Depth-wise convolution,逐通道的卷积,一个卷积负责一个通道,一个通道只被一个卷积核卷积;Pointwise convolution,将上一步得到的feature map串联起来,使得输出的每一个feature map包含输入层所有feature map的信息。这种卷积方式,普遍能够比传统卷积方式减少8-9倍的计算量。虽然都是参数是在同一个量级上,但是运算量却能少GoogleNet一个量级。在构造网络的时候,采用VGG的堆叠思想。 3, shuffleNet: ShuffleNet第一部分的卷积方式和MobileNet一致,第二部分的卷积不同。ShffleNet进行了channel shuffle,将各部分的feature map的channel进行有序的打乱,构成新的feature map,以解决group convolution带来的“信息流通不畅”的问题。在构造网络的时候,采用ResNet的残差网络思想,并在旁路增加均值池化,与另一路的feature map进行串联而非相加,这样有效降低分辨率,却能够弥补分辨率减少而带来的信息损失。 4, Xception: Xception也可以看成是google inception的进化版,也是对depth-wise convolution的改进。两个改进:①原版 Depth-wise convolution,先逐通道卷积,再 1*1 卷积; 而 Xception 是反过来,先 1*1 卷积,再逐通道卷积;②原版 Depth-wise convolution 的两个卷积之间是不带激活函数的,而 Xception 在经过 1*1 卷积之后会带上一个 Relu 的非线性激活函数。这样做的好处在于提高了网络效率。与前面3中不同,Xception没有刻意地减少参数的数量,但是结合了depth-wise convolution能够在同等参数的情况下,提高网络的效果。简单理解为,在硬件资源给定的情况下,尽可能地增加网络效率和性能,充分利用硬件资源。 二、网络的发展 2012年——AlexNet 2014年——VGGNet 2014年——GoogleNet 2015年——ResNet 2017年——DenseNet 2017年——seNet 网络的发展围绕三个方向走:1,网络的深度;2,保持或增加性能,减少参数量;3,改变网络的连接方式; 网络主要有两个衡量标准:1, 参数量;2,运算量 三、轻量化模型 轻量化模型主要针对是第二个方向:保持性能并减少参数量。增加CNN的效率,将复杂的实验室模型精简到可以在移动端高校运行的移动端。通常的方法是模型压缩(Model Compression),即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决速度问题。但是轻量化模型从改变网络结构出发,独辟蹊径地设计出更高效的网络计算方式,从而使网络参数减少的同时,不损失网络的性能。

四、SqueezeNet 《SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5MB》 发表于ICLR2017,伯克利&斯坦福 链接:
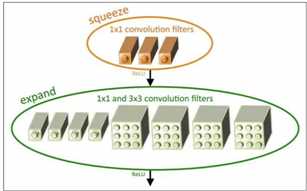
http://www.arxiv.org/abs/1602.07360 4.1 思想:提出fire module,其中包含两个部分:squeeze层和expand层。相当于是1*1卷积+googleNet+VGG 4.2 具体方法: squeeze层就是1*1 卷积,其卷积核数要少于上一层 feature map 数,这个操作从 inception 系列开始就有了,并美其名曰压缩。 expand层分别用 1*1 和 3*3 卷积,然后 concat,这个操作在 inception 系列里面也有。 操作如下图所示:
4.3 squeezeNet网络结构:

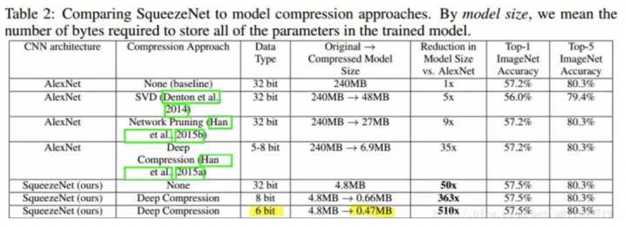
fire module不改变feature size,但是可以随意控制通道的数量,通过堆叠firemodule和控制通道数量,并加上非线性激活层,最后用GAP的形式形成各神经元的输出。(实验室小伙伴问我为什么有的时候用gap得到最后的输出,有时候却用全连接层呢?我的理解是,两者都有自己的好处,全连接层具有全体feature map的感受野,但是参数量非常大,数量级上的差别;GAP的好处在于全卷积操作,参数量少,并相对有效的给出得分,但是也是相对局部的感受野。能够代替全连接层,有一部分的原因也是backbone的发展使得提特征的效果比较好。至于两者怎么选择,需要具体问题具体分析。) 4.4 性能分析
五、MobileNet 《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》 CVPR2017,Google 链接:
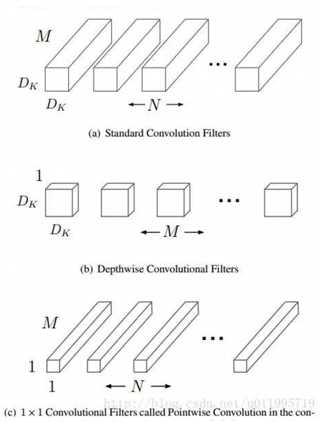
http://www.arxiv.org/abs/1704.04861 5.1 思想:用depth-wise separable convolution卷积方式代替传统卷积方式,能够减少网络参数,提升运行速率。(参数数量和运行速率不一定成正比关系) 5.2 具体方法: 第一步:depth-wise convolution,depth-wise convolution 参考了group convolution,将gc中每一组卷积核负责一组feature map编程每一个卷积核负责一个feature map。 第二步:point-wise convolution,将depth-wise convolution得到的feature map窜起来。 相当于将传统卷积分成两步来做,并模拟传统卷积的行程方式。
5.3 mobileNet结构
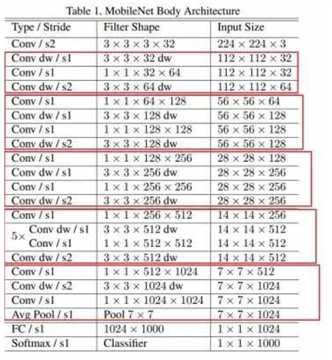
一共28层,采用的是3×3的卷积,并进一步减少运算量,用stride=2的方式代替了pooling进行下采样。 5.4 性能分析
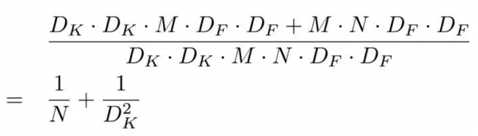
其中 DK 为标准卷积核大小,M 是输入 feature map 通道数,DF 为输入 feature map 大小,N 是输出 feature map 大小。本例中,DK=3,M=2,DF=5,N=3,参数的减少量主要就与卷积核大小 DK 有关。在本文 MobileNet 的卷积核采用 DK=3,则大约减少了 8~9 倍计算量。

性能和googleNet\VGG16相当,参数和GoolgleNet一个量级,但是运算量大大地减少。 六、 ShuffleNet 《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》 CVPR2017, Face++ 论文链接:
http://arxiv.org/abs/1707.01083 6.1 思想 shuffle就是channel shuffle,在进行了group convolution之后,对channel进行有序的打乱,构成新的feature map,这样解决group convolution的「信息流通不畅」问题(例如mobileNet里面的point-wise convolution) 6.2 具体实现 shuffle = group convolution + channel shuffle group convolution:对feature map进行分组,并用相应大小的卷积核来进行卷积。(如AlexNet) channel shuffle: 以一定顺序重组由各group convolution得到的feature map
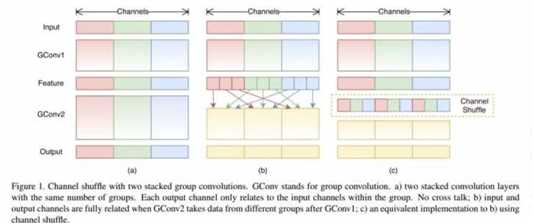
6.3 ShuffleNet 基于resNet的bottleNeck和skip connection,形成shuffleNet 的bottleNeck单元 shuffleNet unit:
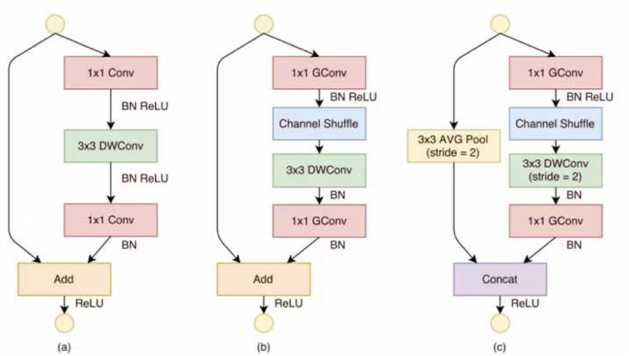
图 (a):是一个带有 depth-wise convolution 的 bottleneck unit;
图 (b):作者在 (a) 的基础上进行变化,对 1*1 conv 换成 1*1 Gconv,并在第一个 1*1 Gconv 之后增加一个 channel shuffle 操作;
图 (c): 在旁路增加了 AVG pool,目的是为了减小 feature map 的分辨率;因为分辨率小了,于是乎最后不采用 Add,而是 concat,从而「弥补」了分辨率减小而带来的信息损失。
形成网络时,用到了resNet的构成方法,而mobileNet和SqueezeNet用的是VGG的模块堆叠思想。
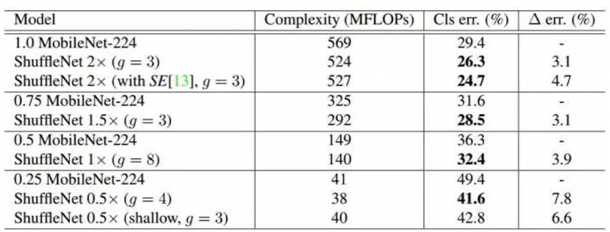
6.4性能分析
七、Xception 《Xception: Deep Learning with Depth-wise Separable Convolutions》 arXiv, 2016年,谷歌 论文链接:
http://arxiv.org/abs/1610.02357 7.1 思想: 两个假设:1. 特征图的跨通道相关性和跨空间的相关性可以相互解耦;2,卷积的时候将通道的卷积和空间的卷积进行分离,可以得到较好的效果(实验证明,没有理论,这也是最近深度学习领域的困难之处,因为影响实验结果的因素实在太多了,很难去保证是因为该元素的影响,当然一定程度上是可以说明问题。) 7.2 具体实现: 基于google的inceptionV3进行改进,提出了Xception,是极限inception的含义。 简化的inceptionV3:
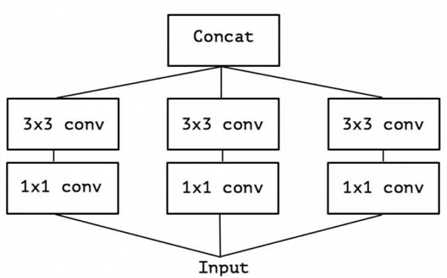
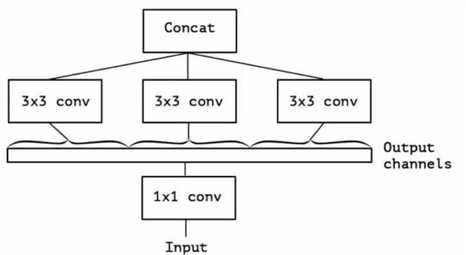
说明:1*1卷积处理通道的链接,然后3*3的卷积处理空间上的卷积。后续进一步假设,将3个1*1的卷积统一成一个。后面分别接3个3*3的分别处理一部分通道
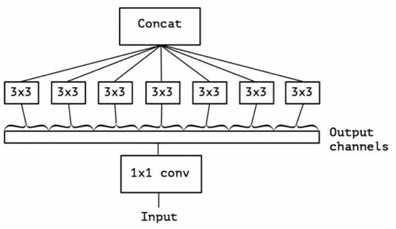
说明: 后续每个1*1的输出特征图都连一个属于他的3*3卷积,形成极限版本的Xcpetion
Xception 与原版的 Depth-wise convolution 有两个不同之处
第一个:原版 Depth-wise convolution,先逐通道卷积,再 1*1 卷积; 而 Xception 是反过来,先 1*1 卷积,再逐通道卷积;
第二个:原版 Depth-wise convolution 的两个卷积之间是不带激活函数的,而 Xception 在经过 1*1 卷积之后会带上一个 Relu 的非线性激活函数;
7.3 Xception具体结构
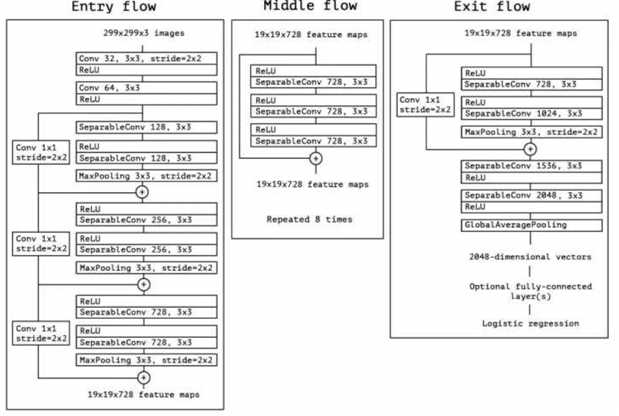
三个版本:Entry flow; Middle flow; Exit flow (发现了一个简化全连接参数的方法,和之前有个同学问的问题结合起来,1,用gap得到完全的得分,直接用来计算loss;2,用gap来聚合信息,后续用全连接再用分类,感觉这样做两者特点都可以比较好的保留,有点seblock的意思) 7.4 性能分析

八、网络轻量化总结:

这么一看就发现,轻量化主要得益于 depth-wise convolution,因此大家可以考虑采用 depth-wise convolution 来设计自己的轻量化网络,但是要注意「信息流通不畅问题」。 解决「信息流通不畅」的问题,MobileNet 采用了 point-wise convolution,ShuffleNet 采用的是 channel shuffle。MobileNet 相较于 ShuffleNet 使用了更多的卷积,计算量和参数量上是劣势,但是增加了非线性层数,理论上特征更抽象,更高级了;ShuffleNet 则省去 point-wise convolution,采用 channel shuffle,简单明了,省去卷积步骤,减少了参数量。 九、待改进 这些轻量化模型都是基于以前的理论符合成果来进行设计的(有些纯粹没有理论基础,纯实验得到的定理)。如果设计出全连接层到卷积层这样的转变,可能才是轻量化模型最终的转变,不过现在的CNN已经足够强大了。