
查询表student中的所有数据:select * from student;
只查询表student中的id和name:select id,name from student;
把重复的行删除,在select后面及字段的前面加distinct:如
条件
- 使用where子句对表中的数据筛选,结果为true的行会出现在结果集中
- 语法如下:
select * from 表名 where 条件;
比较运算符
- 等于=
- 大于>
- 大于等于>=
- 小于<
- 小于等于<=
- 不等于!=或<>
- 查询编号大于3的学生:
select * from student where id>3;
- 查询编号不大于4的科目
select * from subject where id<=4;
- 查询姓名不是“李凤”的学生
select * from student where name!=‘李凤‘;
- 查询没被删除的学生
select * from student where isdelete=0;
逻辑运算符
- and
- or
- not
- 查询编号大于3的女同学
select * from students where id>3 and gender=0;
- 查询编号小于4或没被删除的学生
select * from students where id<4 or isdelete=0;
模糊查询(有时候可能想找个东西但是忘记全名了)
- like
- %表示任意多个任意字符(1个字符,两个字符甚至没有字符或多个字符都可以)
- _表示一个任意字符(只是一个字符)
- 查询姓黄的学生
select * from students where name like ‘黄%‘; - 也可以这样:
 表示名字中间是龙
表示名字中间是龙
- 查询姓黄并且名字是一个字的学生
select * from students where name like ‘黄_‘;
- 查询姓黄或叫靖的学生
select * from students where name like ‘黄%‘ or name like ‘%靖%‘;
范围查询
- in表示在一个非连续的范围内
- 查询编号是1或3或8的学生
select * from students where id in(1,3,8);
- between … and …表示在一个连续的范围内(where后边从做到右执行,如果这时遇到一个between,那么离它最近的and和它相匹配)
- 查询学生是3至8的学生
select * from students where id between 3 and 8;
- 查询学生是3至8的男生
select * from students where id between 3 and 8 and gender=1;
空判断
- 注意:null(这个在内存中压根什么都指向)与‘‘(这个内存中存的就是空字符串)是不同的
- 判空is null
- 查询没有填写地址的学生
select * from students where hometown is null;
- 判非空is not null
- 查询填写了地址的学生
select * from students where hometown is not null;
- 查询填写了地址的女生
select * from students where hometown is not null and gender=0;
优先级
- 小括号,not,比较运算符,逻辑运算符(由高到低,小括号优先级最高)
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
聚合
- 为了快速得到统计数据(聚合:对多行数据进行统计,统计的结果是只能看到最后结果,但是看不到原始的数据集合),提供了5个聚合函数
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
- 查询学生总数
select count(*) from students;
- max(列)表示求此列的最大值
- 查询女生的编号最大值
select max(id) from students where gender=0;
- min(列)表示求此列的最小值
- 查询未删除的学生最小编号
select min(id) from students where isdelete=0;(返回的是1) - 查看未删除的最小编号学生的信息(子查询):
-
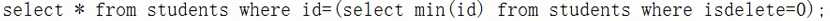
-
执行结果:

- sum(列)表示求此列的和
- 查询男生的编号之和
select sum(id) from students where gender=1;
- avg(列)表示求此列的平均值
- 查询未删除女生的编号平均值
select avg(id) from students where isdelete=0 and gender=0;
分组(目的是为了聚合即统计)
- 按照字段分组,表示此字段相同的数据会被放到一个组中(比如一个班的男生一个组女生一个组)
- 分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中
- 可以对分组后的数据进行统计,做聚合运算
- 语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
- 查询男女生总数:
select gender as 性别,count(*) from students group by gender; 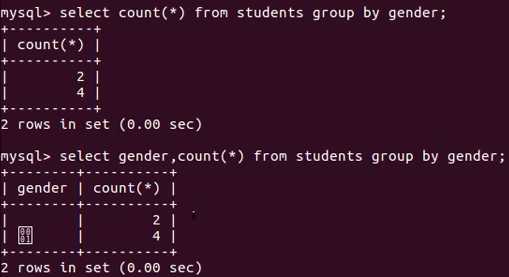
- 表示这个students这个表中有2个女的4个男的
- 查询各城市人数
select hometown as 家乡,count(*) from students group by hometown;
分组后的数据筛选
- 语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3... having 列1,...聚合...
- having后面的条件运算符与where的相同
- 查询男生总人数
方案一
select count(*) from students where gender=1;
-----------------------------------
方案二: select gender as 性别,count(*) from students group by gender having gender=1;



给count(*)起个别名叫rs,having是对分组后的结果集进行筛选,
对比where与having

- where是对from后面指定的表进行数据筛选,属于对原始数据的筛选
- having是对group by的结果进行筛选
排序
- 为了方便查看数据,可以对数据进行排序(比如淘宝对销量由大到小排序)
- 语法:
select * from 表名 order by 列1 asc或desc,列2 asc或desc,...
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列
- asc从小到大排列,即升序
- desc从大到小排序,即降序
- 查询未删除男生学生信息,按学号降序
select * from students where gender=1 and isdelete=0 order by id desc;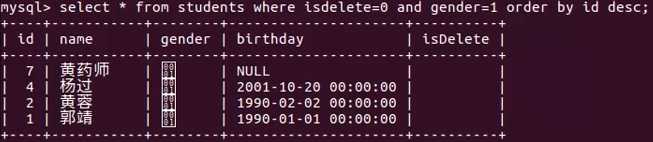
select * from students拿到原始数据,通过where筛选得到一个新的集,order by放在where后是针对新集排序
- 查询未删除科目信息,按名称升序
select * from subjectwhere isdelete=0order by title;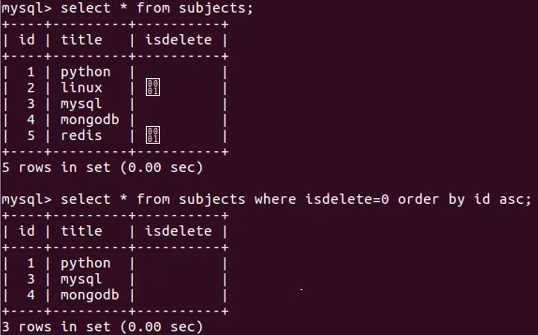
获取部分行
- 当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 语法
select * from 表名 limit start,count
- 从start开始,获取count条数据
- start索引从0开始
示例:分页
- 已知:每页显示m条数据,当前显示第n页
- 求总页数:此段逻辑后面会在python中实现
- 查询总条数p1
- 使用p1除以m得到p2
- 如果整除则p2为总数页
- 如果不整除则p2+1为总页数
- 求第n页的数据
select * from students where isdelete=0 limit (n-1)*m,m