MYSQL:基础——索引原理及慢查询优化
B-树
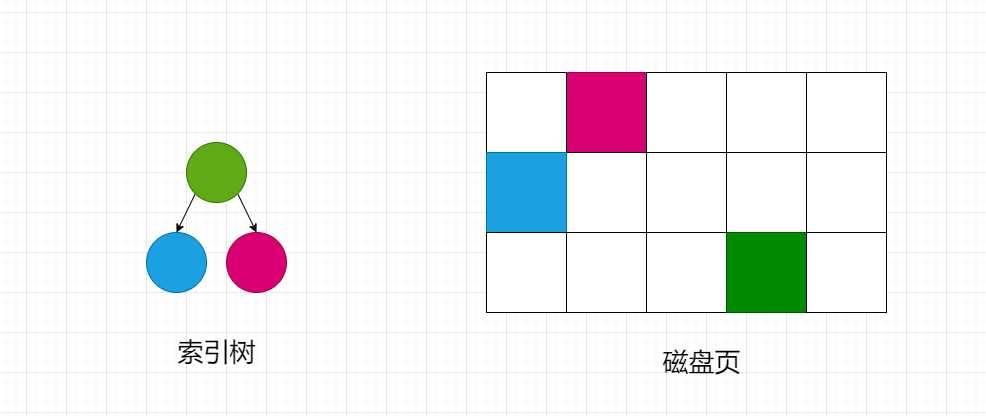
数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小将会达到几个G。当我们利用索引查询的时候,无法把整个索引全部加载到内存中。而是逐一加载每一个磁盘页,这里的磁盘页对应索引树的结点。
B-树,一种平衡多路查找树。适用于查找磁盘中的大量数据。为了减少IO次数,B树最明显的特征是“矮胖的”,即深度较小。初次之外,还有如下特征:
- B树每个节点可以有多个子树,M阶B树表示该数每个节点最多有M个子树。
- 根节点至少有两个子树;中间节点都包含k-1个关键字,和k个子树,其中(M/2<=K<=M)。
- 所有的叶子节点都在同一层。
- 每个节点中的元素从小达到排序,节点当中k-1个关键字正好被k个子树包含的元素的值域分划。
注:B-树(中间的不是减),B是Balance的意思。
3阶B-树
如下图所示是一个3阶的B树。
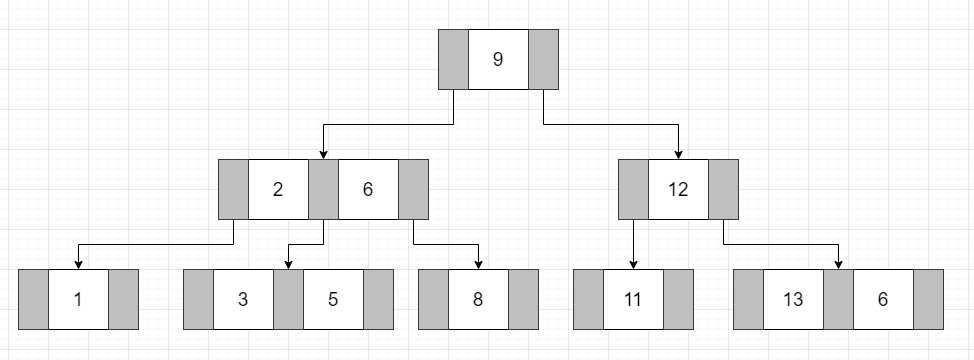
当单一节点中的关键字更多时,查询的比较次数会更多,但是可以减少IO读写次数。在这里我们需要知道的是在内存中的比较耗时机会可以忽略,IO次数足够小,就可以提升查找性能。
B+树
B+树是基于B-树的一种变体,有着比B-树更高的查询性能。B+树具有如下特征:
索引的数据结构
索引的数据结构是B+树。如下图所示,B+树的节点通常被表示为一组有序的数据项和子指针。图中第一个节点包含数据项3和5,包含三个指针,第一个指针指向其数据项均小于3的节点,第二个指针指向其数据项介于3~5的节点,最后一个指针指向其数据项大于等于5的节点。
从上面我们发现一个很重要的特性,每一个父节点的数据项都出现在子节点中,是子节点最大或最小的数据项。这其实也表明了,非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如3,5并不真实存在于数据表中。B+树的叶子结点存储的键值对应data数据的物理地址。
树形结构查找速度快的原因此处不再赘述。
B+树的特性
- 有k个子树的中间节点包含有k个数据项,每个数据项不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有的叶子结点中包含了全部数据项的信息,及指向含这些数据项记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的中间节点数据项都同时存在于子节点,在子节点数据项中是最大(或最小)数据项。
特性的应用
- 索引字段尺寸要尽量小,因为每个节点的空间是有限的,如果索引字段尺寸小的话,可以存储更多的数据项,从而降低树的高度。
- 索引的最左匹配特性。B+树的数据项可以是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
慢查询优化
建索引的原则
- 最左前缀匹配原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 尽量选择区分度高的列作为索引。
- 索引列不能参与计算,保持列“干净”。
慢查询优化实例
如下查询语句
select
count(*)
from
task
where
status=2
and operator_id=20839
and operate_time>1371169729
and operate_time<1371174603
and type=2;
根据最左匹配原则,最开始的sql语句的索引应该是status、operator_id、type、operate_time的联合索引;其中status、operator_id、type的顺序可以颠倒。
但是这只是一种语句,我们其实需要把这个表所有查询都找到,进行综合定夺。