
ASP.NET中JSONP的两种实现以及其他跨域解决方案的简单实现
jQuery中JSONP的两种实现方式:
都很简单,所以直接上代码!
前台代码如下:

<script type="text/javascript">
$(function () {
alert("start...");
// 第一种方式
$.ajax({
type: "get",
url: "http://localhost:9524/Home/ProcessCallback", // 这个就是不同于当前域的一个URL地址,这里单纯演示,所以同域
dataType: "jsonp",
jsonp: "jsonpcallback", // 指定回调函数,这里名字可以为其他任意你喜欢的,比如callback,不过必须与下一行的GET参数一致
data: "name=jxq&email=feichexia@yahoo.com.cn&jsonpcallback=?", // jsonpcallback与上面的jsonp值一致
success: function (json) {
alert(json.Name);
alert(json.Email);
}
});
// 第二种方式
$.getJSON("http://localhost:9524/Home/ProcessCallback?name=xiaoqiang&email=jxqlovejava@gmail.com&jsonpcallback=?",
function(json) {
alert(json.Name);
alert(json.Email);
}
);
alert("end...");
});
</script>
后台Action代码如下:
public string ProcessCallback(string name, string email)
{
if (Request.QueryString != null)
{
string jsonpCallback = Request.QueryString["jsonpcallback"];
var user = new User
{
Name = name,
Email = email
};
return jsonpCallback + "(" + new JavaScriptSerializer().Serialize(user) + ")";
}
return "error";
}
运行后就可以看到结果了。我追踪了下后台ProcessCallback代码,如下图:
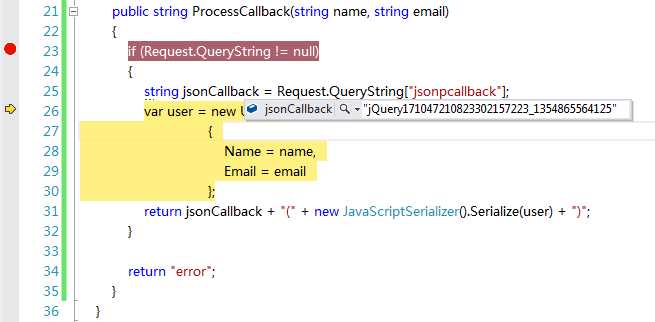
可以看到jsonCallback的值为”jQuery17104721….”,它是前端传给远程服务器后台Action的。这里jQuery171..表示的是jQuery的版本,可以简单地将这个理解为JSONP类型请求回调函数,jQuery在我们每次指定Ajax请求方式为JSONP时都会生成这么一个JSONP回调函数。虽然jQuery会自动帮我们生成一个回调函数,但是我们也可以通过设置jsonpCallback参数为jsonp请求定制一个我们自己的回调函数。
第一种方式下面这三行代码设定了JSONP请求方式:
dataType: "jsonp", jsonp: "jsonpcallback", // 指定回调函数,这里名字可以为其他任意你喜欢的,比如callback,不过必须与下一行的GET参数一致 data: "name=jxq&email=feichexia@yahoo.com.cn&jsonpcallback=?", // jsonpcallback与上面的jsonp值一致
第二种方式则直接在GET参数后面带上jsonpcallback=?来标识。
我们可以推断这么做以后,jQuery内部机制就帮我们绕过了浏览器的跨域访问限制,然后就可以像正常请求同域Action一样请求跨域Action了。
最后返回的是一个函数表达式:
return jsonCallback + "(" + new JavaScriptSerializer().Serialize(user) + ")";
这样返回给前端的就是类似这种jQuery17104721….(‘{Name:”jxq”, Email:”feichexia@yahoo.com.cn”}‘),它一返回到前端就会执行,得到的是一个JavaScript对象,对象有两个属性:Name和Email,所以我们可以直接调用json.Name和json.Email。
上面return时千万别忘了圆括号,原因不多说,看看下面的例子就明白了:
var response = "{‘foo‘ : ‘bar‘}";
var json = eval(response); // Invalid label
var json = eval("(" + response + ")"); // OK
此外也可以通过动态创建Script、内嵌iframe方式实现跨域。动态创建script的简单代码如下:
$(function() {
var script = document.createElement("script");
script.type = "text/javascript";
script.src = "http://otherdomain/script.js";
// 异步加载脚本
script.onload = script.onreadystatechange = function(){
if(!script.readyState || script.readyState == ‘loaded‘) { // 加载完毕
add(1, 99); // 直接调用跨域js中的函数
}
};
document.getElementsByTagName(‘head‘)[0].appendChild(script);
// add(1, 99); // 这样会出错,因为脚本还没加载完毕
});
// script.js代码如下
function add(a, b) {
alert("Add: " + a + "+" + b + "=" + (a+b));
}
当然还可以通过jQuery的getScript方法来跨域请求一个js文件或者包含js代码的文本文件(比如test.js.txt),直接贴代码:
$.getScript("http://otherdomain/test.js", function(){
alert("Script loaded and executed."); // 脚本加载完毕后会直接执行
});
这种方式加载完成后,就能和使用同域JS一样使用跨域JS中的函数或变量了。