代理模式(Proxy Pattern) :
给某一个对象提供一个代 理,并由代理对象控制对原对象的引用。代理模式的英 文叫做Proxy或Surrogate,它是一种对象结构型模式
模式动机:
在某些情况下,一个客户不想或者不能直接引用一个对 象,此时可以通过一个称之为“代理”的第三者来实现 间接引用。代理对象可以在客户端和目标对象之间起到 中介的作用,并且可以通过代理对象去掉客户不能看到 的内容和服务或者添加客户需要的额外服务。
通过引入一个新的对象(如小图片和远程代理对象)来实现对真实对象的操作或者将新的对 象作为真实对象的一个替身,这种实现机制即 为代理模式,通过引入代理对象来间接访问一 个对象,这就是代理模式的模式动机。
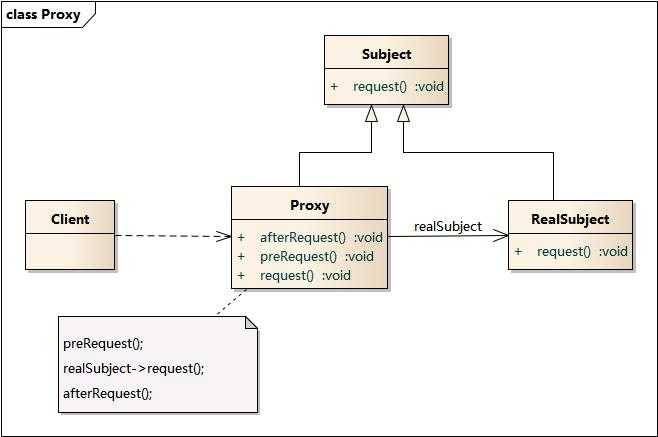
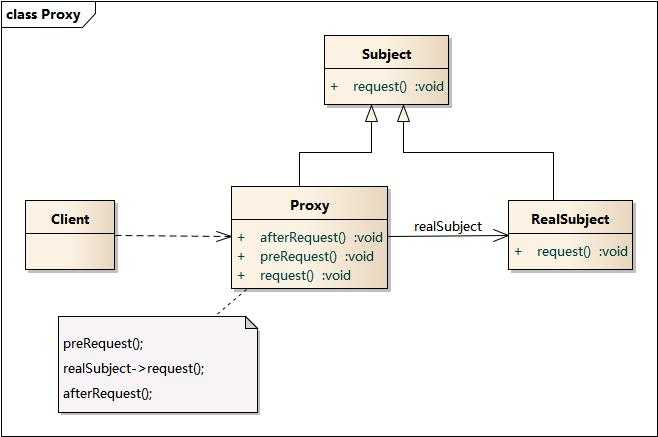
代理模式包含如下角色:
抽象主题角色(Subject):定义了RealSubject和Proxy公用接口,这样就在任何使用RealSubject的地方都可以使用Proxy。
真正主题角色(RealSubject):定义了Proxy所代表的真实实体。
代理对象(Proxy):保存一个引用使得代理可以访问实体,并提供一个与RealSubject接口相同的接口,这样代理可以用来代替实体(RealSubject)。
<?php header("Content-type:text/html;Charset=utf-8"); //定义RealSubject和Proxy共同具备的东西 interface Subject{ function say(); function run(); } class RealSubject implements Subject{ private $name; function __construct($name){ $this->name = $name; } function say(){ echo $this->name."在吃饭<br>"; } function run(){ echo $this->name."在跑步<br>"; } } class Proxy implements Subject{ private $realSubject = null; function __construct(RealSubject $realSubject = null){ if(empty($realSubject)){ $this->realSubject = new RealSubject(); }else{ $this->realSubject = $realSubject; } } function say(){ $this->realSubject->say(); } function run(){ $this->realSubject->run(); } } //测试 $subject = new RealSubject("张三"); $proxy = new Proxy($subject); $proxy->say(); $proxy->run(); /* 张三在吃饭 张三在跑步 */ ?>
优点:
代理模式能够协调调用者和被调用者,在一定程度上降低了系 统的耦合度。
远程代理使得客户端可以访问在远程机器上的对象,远程机器 可能具有更好的计算性能与处理速度,可以快速响应并处理客户端请求。
虚拟代理通过使用一个小对象来代表一个大对象,可以减少系 统资源的消耗,对系统进行优化并提高运行速度。
保护代理可以控制对真实对象的使用权限。
缺点:
由于在客户端和真实主题之间增加了代理对象,因此 有些类型的代理模式可能会造成请求的处理速度变慢。
实现代理模式需要额外的工作,有些代理模式的实现 非常复杂。
适用场景:
根据代理模式的使用目的,常见的代理模式有以下几种类型:
1、远程(Remote)代理:为一个位于不同的地址空间的对象提供一个本地 的代理对象,这个不同的地址空间可以是在同一台主机中,也可是在 另一台主机中,远程代理又叫做大使(Ambassador)。
2、虚拟(Virtual)代理:如果需要创建一个资源消耗较大的对象,先创建一个消耗相对较小的对象来表示,真实对象只在需要时才会被真正创建。
3、Copy-on-Write代理:它是虚拟代理的一种,把复制(克隆)操作延迟 到只有在客户端真正需要时才执行。一般来说,对象的深克隆是一个 开销较大的操作,Copy-on-Write代理可以让这个操作延迟,只有对象被用到的时候才被克隆。
4、保护(Protect or Access)代理:控制对一个对象的访问,可以给不同的用户提供不同级别的使用权限。
5、缓冲(Cache)代理:为某一个目标操作的结果提供临时的存储空间,以便多个客户端可以共享这些结果。
6、防火墙(Firewall)代理:保护目标不让恶意用户接近。
7、同步化(Synchronization)代理:使几个用户能够同时使用一个对象而没有冲突。
8、智能引用(Smart Reference)代理:当一个对象被引用时,提供一些额外的操作,如将此对象被调用的次数记录下来等。
几种常用的代理模式:
1、图片代理:一个很常见的代理模式的应用实例就是对大图浏览的控制。
用户通过浏览器访问网页时先不加载真实的大图,而是通过代理对象的方法来进行处理,在代理对象的方法中,先使用一个线程向客户端浏览器加载一个小图片,然后在后台使用另一个线程来调用大图片的加载方法将大图片加载到客户端。当需要浏览大图片时,再将大图片在新网页中显示。如果用户在浏览大图时加载工作还没有完成,可以再启动一个线程来显示相应的提示信息。通过代理技术结合多线程编程将真实图片的加载放到后台来操作,不影响前台图片的浏览。
2、远程代理:远程代理可以将网络的细节隐藏起来,使得客户端不必考虑网络的存在。客户完全可以认为被代理的远程业务对象是局域的而不是远程的,而远程代理对象承担了大部分的网络通信工作。
3、虚拟代理:当一个对象的加载十分耗费资源的时候,虚拟代理的优势就非常明显地体现出来了。虚拟代理模式是一种内存节省技术,那些占用大量内存或处理复杂的对象将推迟到使用它的时候才创建。
在应用程序启动的时候,可以用代理对象代替真实对象初始化,节省了内存的占用,并大大加速了系统的启动时间。
4、动态代理:动态代理是一种较为高级的代理模式,它的典型应用就是Spring AOP。
在传统的代理模式中,客户端通过Proxy调用RealSubject类的request()方法,同时还在代理类中封装了其他方法(如preRequest()和postRequest()),可以处理一些其他问题。
如果按照这种方法使用代理模式,那么真实主题角色必须是事先已经存在的,并将其作为代理对象的内部成员属性。如果一个真实主题角色必须对应一个代理主题角色,这将导致系统中的类个数急剧增加,因此需要想办法减少系统中类的个数,此外,如何在事先不知道真实主题角色的情况下使用代理主题角色,这都是动态代理需要解决的问题。
代码实现