写在前面
前端开发,图片两端对齐,是十分常见的,也是十分痛苦的,我试过好多方法,通过整理,认为下面还是比较靠谱的,在实践中大家可以试试,欢迎一起学习,一起进步
HTML代码
HTML代码非常简单,用的是DIV,里面用的是SPAN标签。没有采用Ul li 标签,是因为在实践应用中总是出现好多坑,无论怎么调试都解决不了,也许是我学艺不精吧。但是方法总比困难多,绕开他。使用css的display:inline-block,text-align:justify;下面简单介绍一下这两个:
display 属性规定元素应该生成的框的类型。inline-block是display中的一个属性值,表示将对象呈递为内联对象,对象的内容作为块对象呈递。旁边的内联对象会被呈递在同一行内,允许空格。这一性质正好满足我们图片同行显示的要求。
text-align 属性规定元素中的文本的水平对齐方式。justify是text-align的一个属性值,表示两端对齐。
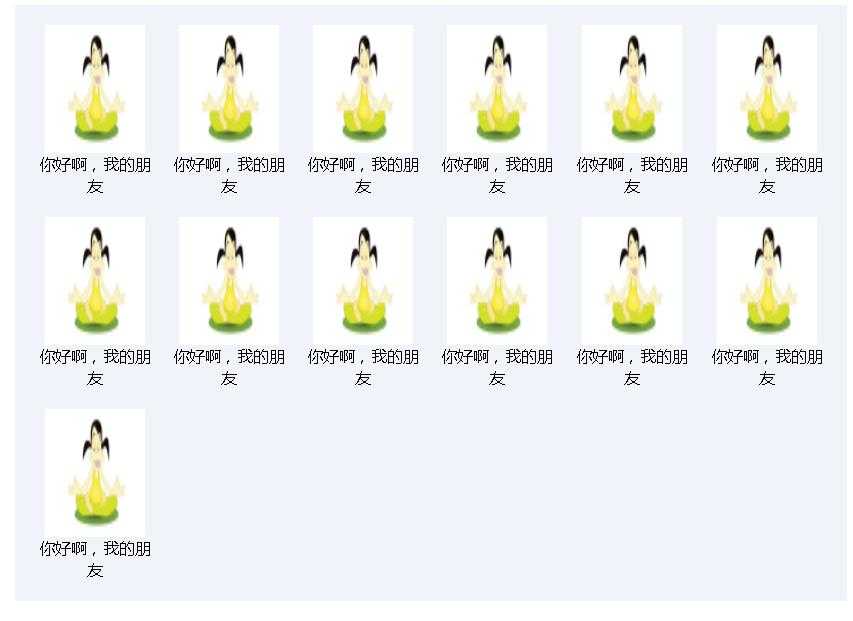
<div class="box"> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友~~</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> <span class="list"><img src="http://agoodlife.cn/PicBox/201811/Infomaiton_200_180_Infomaiton_201811041101000.jpg" /><br />你好啊,我的朋友</span> </div>
CSS代码
.box{width:50%; line-height:0; padding:20px 20px 0; margin:20px auto; background-color:#f0f3f9; text-align:justify;} .list{width:120px; display:inline-block; line-height:1.4; padding-bottom:20px; text-align:center; vertical-align:top;} .list img{width: 100px; height: 128px;}
上面的CSS代码非常简单,我简单解释一下,box是个容器,添加了text-align:justify;目的是,使里面的文字两单对齐,里面的SPAN标签可以继承文字属性,为了使图片一行显示添加CSS样式 display:inline-block;这样就可以使两端对齐,可以直接调整图片大小,每行的图片显示个数自动适应,最终效果如下图:
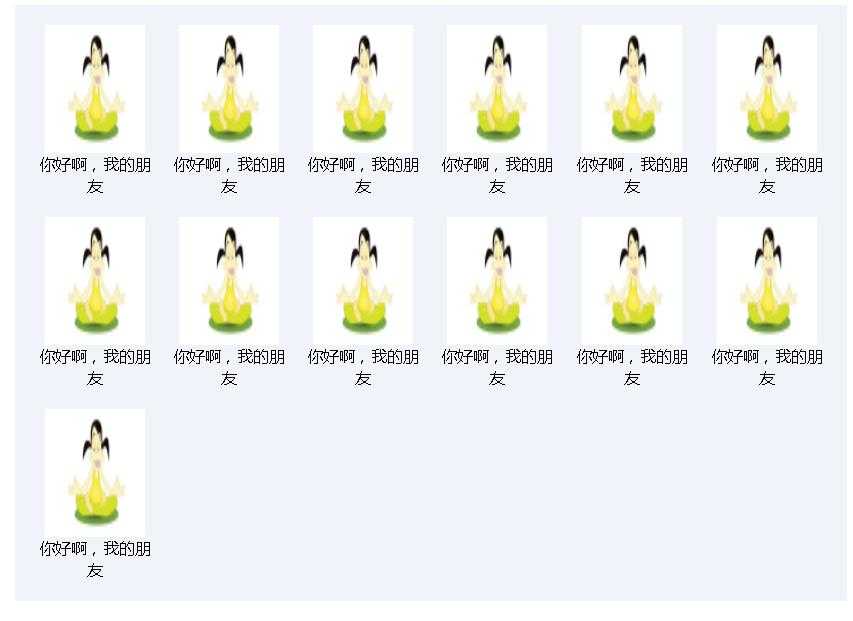
作为收藏笔记,希望大家不断完善,谢谢!!!!!!!!!!!!!