在使用git管理代码,或者使用github,国内的码云(gitee)的时候,有两种方式可以使用,分别是https和ssh,以下均使用gitee为例。
-
ssh方式
配置ssh,如果不配置ssh的话,clone项目的时候会报错,原因是没有配置公钥。
1 Permission denied (publickey) 2 Could not read from remote repository.
首先,进入用户目录,查看本地是否已经存在公钥文件。
1 cd ~/.ssh 2 ls
如果显示文件夹不存在,则本地还没有生成密钥文件,则使用git提供的密钥生成工具进行生成。
1 ssh-keygen -t rsa -C "xxxxx@xxxxx.com"
注意,回车后有几次需要回车,第二部需要你设置密码,如果不设置直接回车,则以后在使用ssh方式拉取提交代码的时候不需要再输入密码。
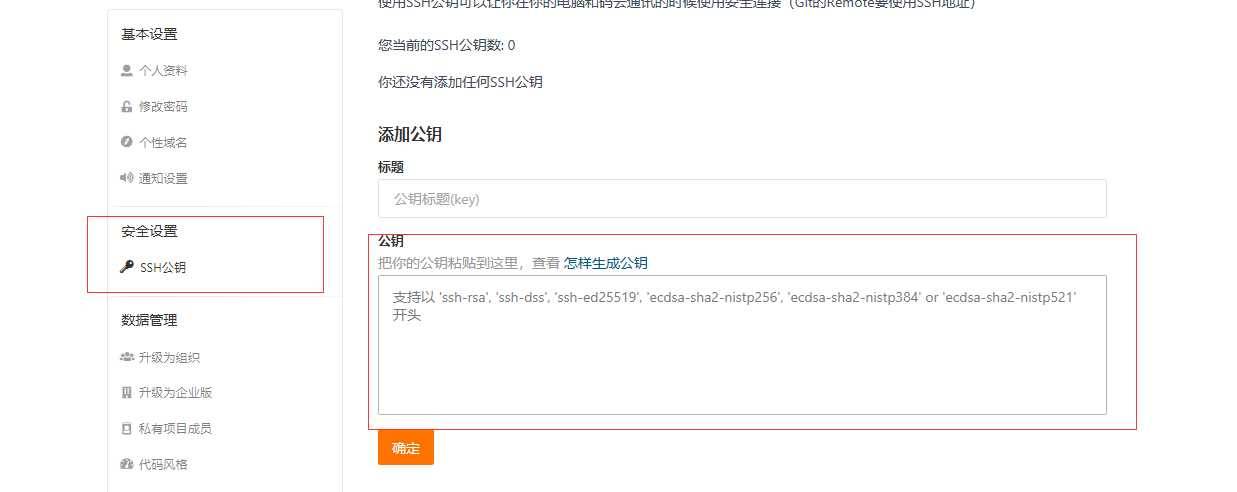
完成后,用户文件夹下多出了一个.ssh文件夹,里面有两个文件,一个id_rsa 和id_rsa.pub文件,使用命令打开id_rsa.pub文件,复制内容
1 cat ~/.ssh/id_rsa.pub然后粘贴到github或gitee上的公钥中,可以给项目添加公钥,也可以给自己的账号添加公钥,二者的区别官方的解释是:
项目的 sshkey 只针对项目,且我们仅对项目提供了部署公钥,即
项目下的公钥仅能拉取项目,这通常用于生产服务器拉取仓库的代码。 而用户的 key 则是针对用户的,用户添加了 key 就对用户名下的项目和用户参加了的项目具有权限,一般而言, 用户的key具有推送和拉取的权限,而项目的 key 则只具有拉取权限。
输入命令进行测试:
1 ssh -T git@gitee.com如果返回 ”Hi gitee用户名xxxxxx……“ 说明配置成功了。
设置好了之后,然后拉取代码,第一次拉取的时候,会询问是否信任连接,yes就行了,就可以正常拉取,提交代码了,也不需要设置每次都输入账号和密码了。
注意,信任完gitee的连接后,.ssh文件夹里多出了一个known_hosts文件,这里就记录了gitee的相关连接信息。这里会有一个小问题,那假如我有多个git账号,比如:1,gitee账号,用于自己个人 2,gihub账号,用于公司开发,那么怎么配置多个密钥呢?
解决办法:1,生成多个密钥文件
1 ssh-keygen -t rsa -C ‘xxxxx@company.com‘ -f ~/.ssh/gitee_id_rsa 2 ssh-keygen -t rsa -C ‘xxxxx@qq.com‘ -f ~/.ssh/github_id_rsa
2,在 ~/.ssh 目录下新建一个config文件,添加如下内容(其中Host和HostName填写git服务器的域名,IdentityFile指定私钥的路径)
1 # gitee 2 Host gitee.com 3 HostName gitee.com 4 PreferredAuthentications publickey 5 IdentityFile ~/.ssh/gitee_id_rsa 6 # github 7 Host github.com 8 HostName github.com 9 PreferredAuthentications publickey 10 IdentityFile ~/.ssh/github_id_rsa
3,用ssh命令分别测试
1 $ ssh -T git@gitee.com 2 $ ssh -T git@github.com
-
https方式
配置credential.helper,首先简单介绍一下credential.helper这个配置项的含义:这个配置项允许用户自行指定git所使用的凭据管理工具。SSH协议并不采用这里讨论的凭证存储。
首先,检查credential.helper配置,输入命令
1 git config -l|grep credential.helper没有配置的话,显示为空,windows安装如果安装的是GitGUI的时候,默认是勾选manager的,credential.helper=manager,如果没有配置的话,每次拉取,提交都需要密码。使用以下命令配置:
1 git config credential.helper manager再次尝试pull代码的时候会弹出窗口要求输入用户名密码(只需要输入这一次就ok了),以后就不需要再输入密码了,windows而言,这个凭据放在windows的凭据管理器中
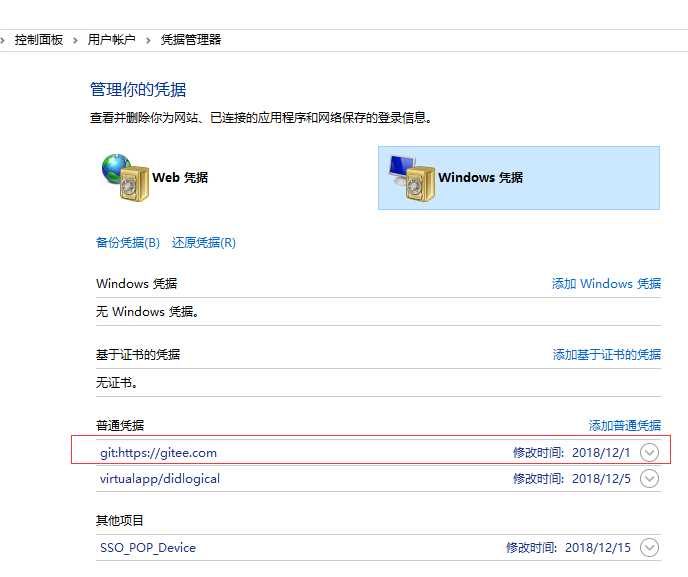
整个过程可以这样描述:当配置credential.helper后,git在需要用户名密码时会首先向指定的凭据管理器查找凭据,如果凭据不存在(对应第一次pull),则弹窗提示用户输入用户名密码,然后凭据管理器会记录这个凭据;如果凭据存在(对应第二次pull),则直接使用该凭据进行对应的git操作。
注意:当你需要在同一台机器上使用多个git账号这么搞就不行了,因为2个账号必定使用的不同的凭据。