
pytorch实战 猫狗大战Kaggle 迁移学习ResNet50模型微调
猫狗大战数据集
-
这是kaggle上一个非常经典的二分类图像数据集,训练集包括25000张猫和狗的图片及其标签,测试集则是12500张未标签图片,数据下载地址https://www.kaggle.com/c/dogs-vs-cats/data。不过这个网址比较远古,无法提交自己训练的答案,可以到新的(虽然也不新了)比赛链接提交https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/overview
-
将训练数据按类别分开整理成如下结构
|-- train |-- cat |-- 1.jpg |-- 2.jpg |-- ... |-- dog |-- 1.jpg |-- 2.jpg |-- ...
数据加载及处理
-
整理好数据后,我们可以直接使用ImageFolder读取并使用random_split()划分数据集验证集
all_data = torchvision.datasets.ImageFolder( root=train_root, transform=train_transform ) train_data , vaild_data= torch.utils.data.random_split(all_data,[int(0.8*len(all_data)),len(all_data)-int(0.8*len(all_data))) -
复杂的也可以继承datasets类,简单示例
class MyDataset(Dataset): def __init__(self, root, size=229, ): """ Initialize the data producer """ self._root = root self._size = size self._num_image = len(os.listdir(root)) self._img_name = os.listdir(root) def __len__(self): return self._num_image def __getitem__(self, index): img = Image.open(os.path.join(self._root, self._img_name[index])) # PIF image: H × W × C # torch image: C × H × W img = np.array(img, dtype-np.float32).transpose((2, 0, 1)) return img -
为防止过拟合,可以对数据进行翻转,亮度,对比度等数据增广
train_transform = transforms.Compose([ transforms.Resize(224), transforms.RandomResizedCrop(224,scale=(0.6,1.0),ratio=(0.8,1.0)), transforms.RandomHorizontalFlip(), torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0), torchvision.transforms.ColorJitter(brightness=0, contrast=0.5, saturation=0, hue=0), transforms.ToTensor(), transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) ]) -
加载为pytorch读取的数据集
train_set = torch.utils.data.DataLoader( train_data, batch_size=BTACH_SIZE, shuffle=True ) test_set = torch.utils.data.DataLoader( vaild_data, batch_size=BTACH_SIZE, shuffle=False )
迁移学习 ResNet50微调
- 此前自己写过浅层的CNN,验证集准确率只能达到七十多,深了不会写估计训练也很难,于是采用迁移学习的思想,torchvision提供了很多现成的模型和预训练好的参数:
- Alexnet
- VGG
- ResNet
- SqueezeNet
- DenseNet
- Inception v3
-
这里我们使用残差网络 ResNet50 并且加上全连接层和softmax输出二分类
model = torchvision.models.resnet50(pretrained=True) model.fc = nn.Sequential( nn.Linear(2048,2), nn.softmax() ) -
这里我用0.01的学习率训练了5次就能达到九十多的准确率了,实际上还可以对输出层使用较高的学习率而对其他层使用较低的学习率来达到更好的微调效果
Kaggle提交
- 直接提交看看,貌似一般般,在排行榜里算中等

- kaggle这里的评估是使用logloss
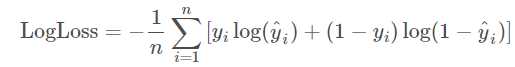
- 我们看看标签分别是0和1的时候这个loss是怎样的
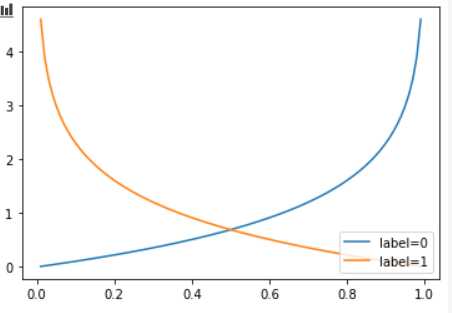
- 这时候就可以有一些奇淫技巧,面向评估函数编程,把预测狗的统一改成0.95,猫的改成0.05,再提交一下

- 仅供娱乐
代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import os
import matplotlib.pyplot as plt
from tqdm import tqdm
#超参
DEVICE = torch.device('cuda')
LR = 0.001
EPOCH = 50
BTACH_SIZE = 32
train_root = './train'
#数据加载及处理
train_transform = transforms.Compose([
transforms.Resize(224),
transforms.RandomResizedCrop(224,scale=(0.6,1.0),ratio=(0.8,1.0)),
transforms.RandomHorizontalFlip(),
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0),
torchvision.transforms.ColorJitter(brightness=0, contrast=0.5, saturation=0, hue=0),
transforms.ToTensor(),
transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])
])
all_data = torchvision.datasets.ImageFolder(
root=train_root,
transform=train_transform
)
train_data , vaild_data= torch.utils.data.random_split(all_data,[int(0.8*len(all_data)),len(all_data)-int(0.8*len(all_data)))
train_set = torch.utils.data.DataLoader(
train_data,
batch_size=BTACH_SIZE,
shuffle=True
)
test_set = torch.utils.data.DataLoader(
vaild_data,
batch_size=BTACH_SIZE,
shuffle=False
)
#训练和验证
cirterion = nn.CrossEntropyLoss()
def train(model,device,dataset,optimizer,epoch):
model.train()
correct = 0
for i,(x,y) in tqdm(enumerate(dataset)):
x , y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
loss = cirterion(output,y)
LOSS.append(loss)
loss.backward()
optimizer.step()
print("Epoch {} Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(epoch,loss,correct,len(dataset),100*correct/len(dataset)))
def vaild(model,device,dataset):
model.eval()
correct = 0
with torch.no_grad():
for i,(x,y) in tqdm(enumerate(dataset)):
x,y = x.to(device) ,y.to(device)
output = model(x)
loss = nn.CrossEntropyLoss(output,y)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
print("Test Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(loss,correct,len(dataset),100.*correct/len(dataset)))
model = torchvision.models.resnet50(pretrained=True)
model.fc = nn.Sequential(
nn.Linear(2048,2),
nn.Softmax()
)
model.to(DEVICE)
optimizer = optim.SGD(model.parameters(), lr = LR, momentum = 0.09)
for epoch in range(1,EPOCH+1):
train(model,DEVICE,train_set,optimizer,epoch)
vaild(model,DEVICE,test_set)