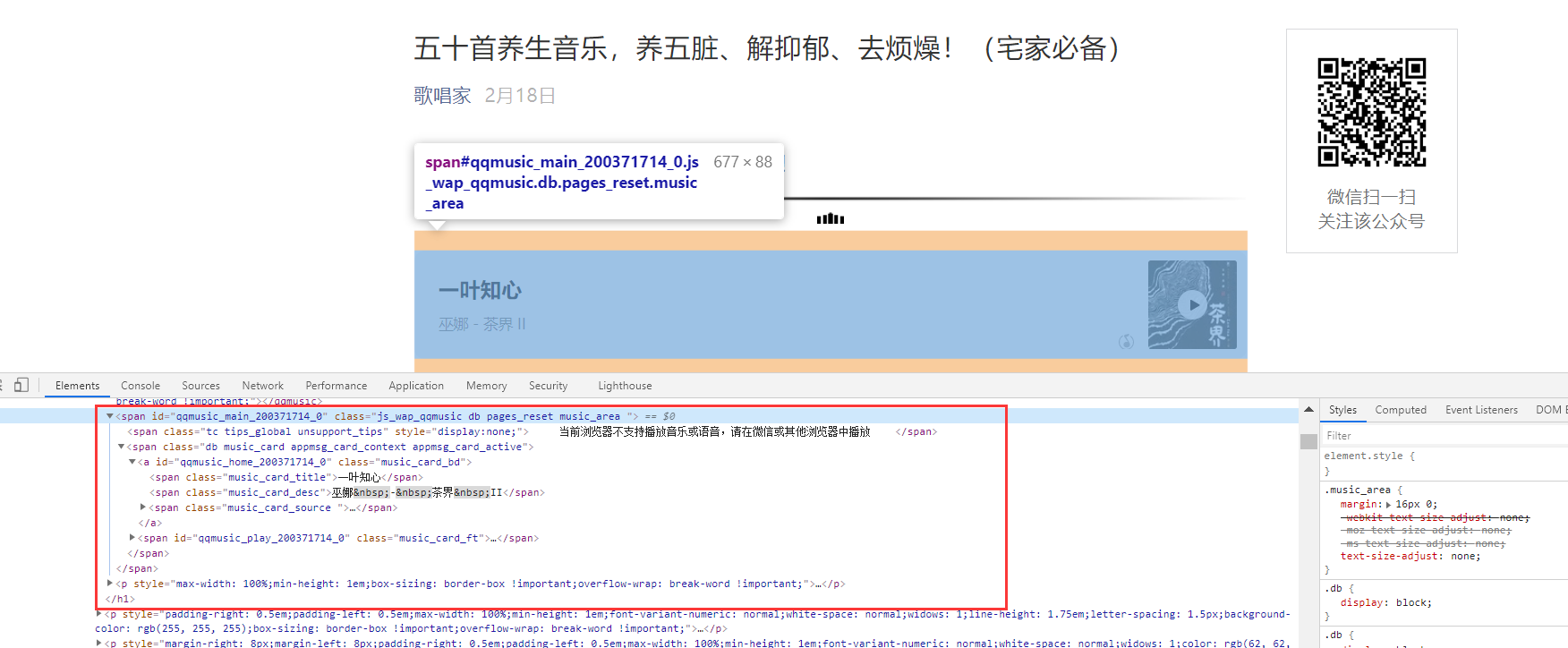
序言
一般微信公众号文章里面的音乐是没有下载按钮的,如果我们需要下载该怎么办呢?
下面是完整的音乐链接和解析下载步骤
微信公众号文章链接:
https://mp.weixin.qq.com/s?__biz=MzA5NTg0MzMyNg==&mid=2652963841&idx=4&sn=08b7304594d8e4d71ec4ec591a50eeaf&chksm=8b6c8290bc1b0b86e1296dfeb28a6d37ff540a41212d76bd83668df1688de547aeb846b4c494&mpshare=1&scene=1&srcid=0823QJsOMp2jpR3nqiVUC8rQ&sharer_sharetime=1598774793330&sharer_shareid=675c834ec13bec5e9591a5db62a513e0&key=90349d069103c403a10b0b41fe9a3ac966e45da72eca596fb474a06f5aef3d72ae4b99e54388e890d209d25aecfbd2c57a25575a0d23d4b7852dde5d1677e59d83b6d8bd4387fad1054be4abe96d284fd2c345752f09b560e202aa9f85fd735fca59771e8be44c696ceffd80078603d498820eb71f2d0f95583f089222a0d356&ascene=1&uin=MTYxMjUyMDM0NA%3D%3D&devicetype=Windows+10+x64&version=62090529&lang=zh_CN&exportkey=A%2BRQAeAggPR%2BShRmH33FEHw%3D&pass_ticket=Oax%2FPUrL2XvZZ10Az1q9BDNyjP%2F%2FF3zf%2FhdkVZ9LL53biy2LYhVBhBIOs1ybuWuz&wx_header=0
分析
页面分析
首先我们对页面的音乐的代码进行查看和分析,首先我们定位到其中一个音乐的代码进行分析和查看
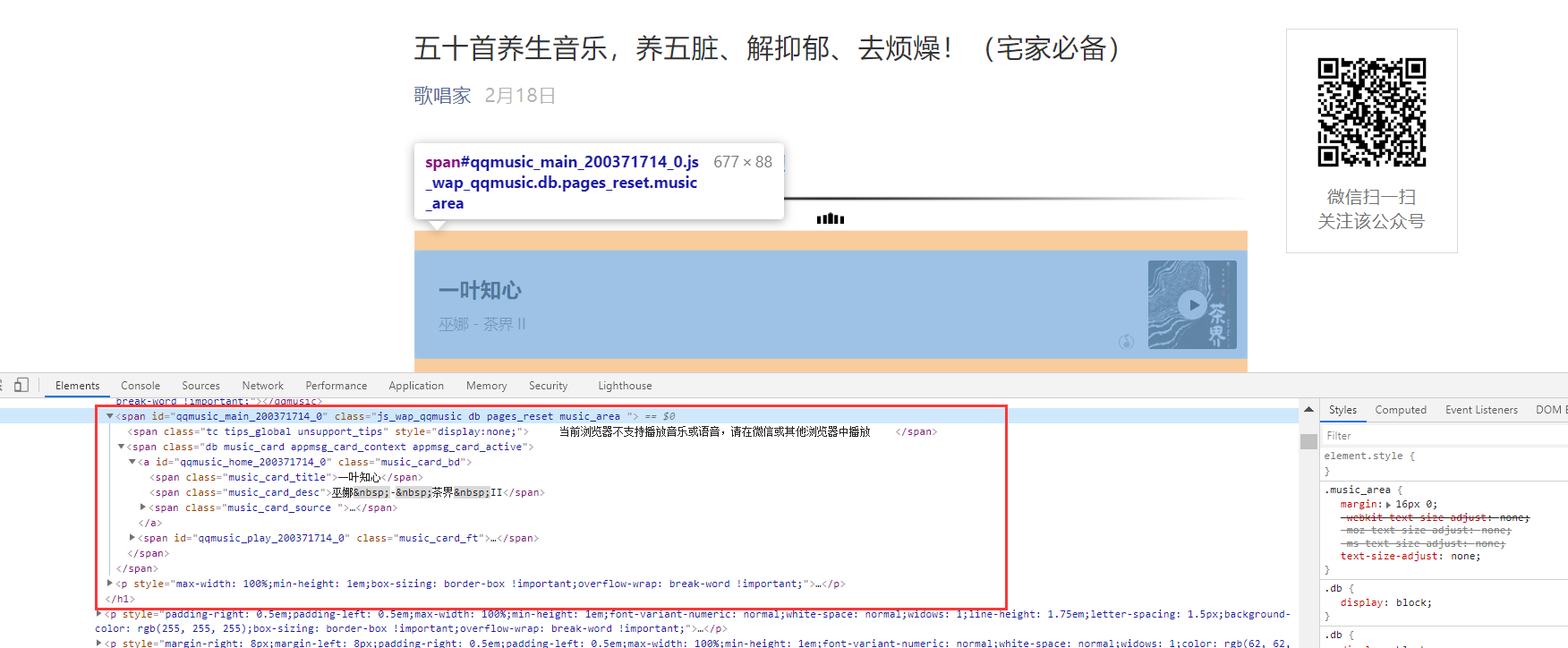
在播放按钮的样式里面,有一条链接,但是直接打开是打不开的
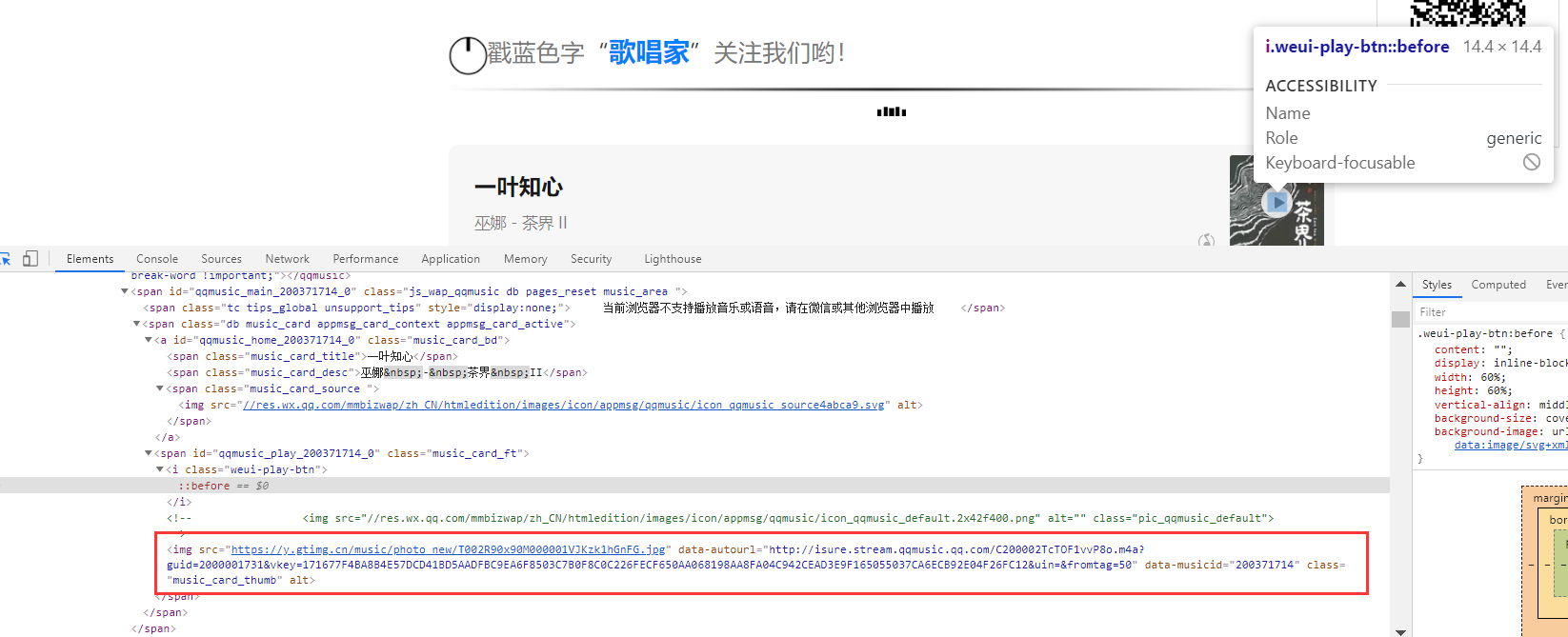
点击播放音乐进行抓包。
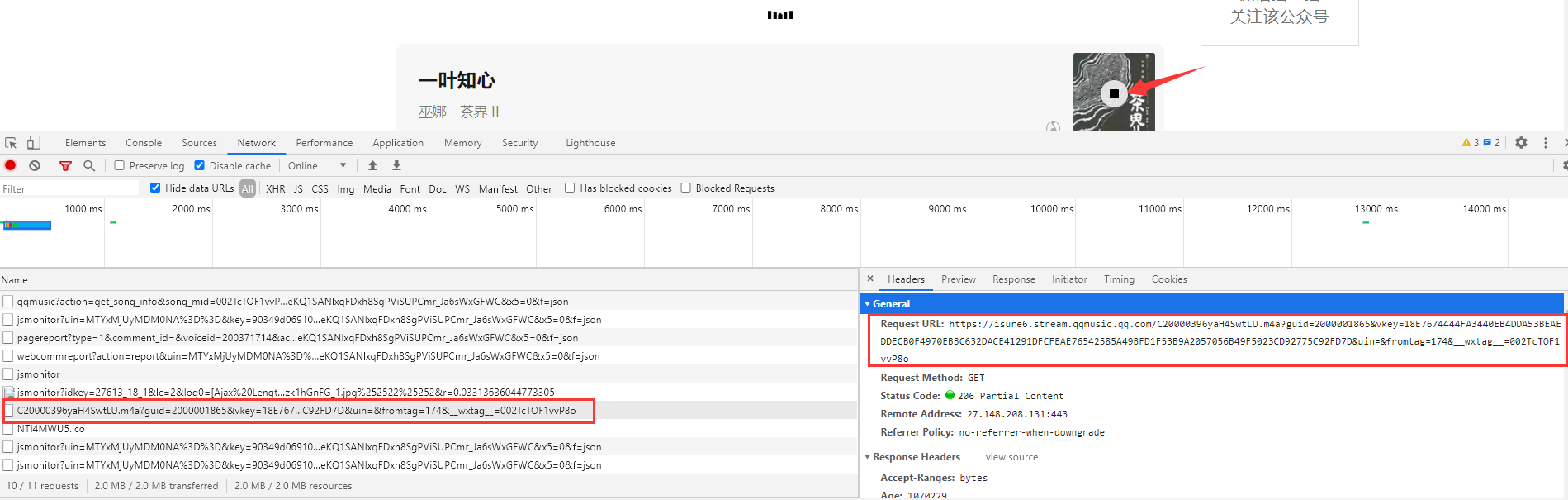
点击播放音乐后通过chrome的抓包工具,可以拿到音乐的链接,打开该链接可以下载音乐,说明音乐是可以下载的,只要
代码
获取音乐列表
获取音乐列表,这里用的是js,直接在页面上点击播放所有的歌曲,然后再获取audio 的列表
getPlaylist.js
let all = document.getElementsByClassName(‘music_card_thumb‘);
for (let i = 0; i < all.length; i++) {
all[i].click();
}
setTimeout(){
let all_music_name = {};
let qq_music = document.getElementsByTagName(‘qqmusic‘);
for(let i=0; i<qq_music.length; i++) {
all_music_name[qq_music[i].getAttribute(‘mid‘)] = qq_music[i].getAttribute(‘music_name‘);
}
let audio_src_wxtag = {};
let audio = document.getElementsByTagName(‘audio‘);
for(let i=0; i<audio.length; i++){
let music_src = audio[i].getAttribute(‘src‘)
let music_wxtag_list=music_src.split("&__wxtag__=")
let music_wxtag=music_wxtag_list[music_wxtag_list.length-1]
audio_src_wxtag[music_wxtag]=music_src
}
let audio_arr = {};
for(let wxtag in audio_src_wxtag) {
if(all_music_name.hasOwnProperty(wxtag)) {
audio_arr[all_music_name[wxtag]] = audio_src_wxtag[wxtag];
}
}
}
let json_data=JSON.stringify(audio_arr)
下载音乐
下载音乐用python进行下载,读取下载列表的链接和歌曲名称,然后以字节的方式进行写入。
这里要添加UserAgent,不然请求会被拒绝。
download.py
import json
with open("./playList.json", "r",encoding="utf-8") as f:
url_list = f.read()
url_list = json.loads(url_list)
import requests
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
for name, url in url_list.items():
print(name,url)
music = requests.get(headers=header, url=url).content
with open("./music/{}.m4a".format(name), "wb+") as f:
f.write(music)