
需求:实现轮播图,图片无缝切换,自动播放。
实现效果:


思考一下:在图片列表后面多加一张图片,这张图片是第一张图片(为了确保无缝衔接)。图片就是平铺放在一个pic里面的,每次移动就是改变的pic的left值。
来撸代码~~。所有的代码放在最后面,这里只讲一些重要的方法:
为防止懵逼:先贴出封装函数move()的代码供参考
function move(ele, attr, speed, target, callback){
//获取当前的位置
//从左往右进行移动 --- current<target speed
//从右往左进行移动 --- current>target -speed
var current = parseInt(getStyle(ele, attr));
// 810 > 800
if(current>target){
speed = -speed;
}
//定时器累加问题 --- 先清除再开启
clearInterval(ele.timer);
ele.timer = setInterval(function(){
//获取元素的现在位置
var begin = parseInt(getStyle(ele, attr));
//步长
var step = begin + speed;
//判断当step>800, 让step = 800
//从左往右进行移动 --- speed>0 正值
//从右往左进行移动 --- speed<0 负值
// -10 0 10 超过800直接变成 800
if(speed<0 && step<target || speed>0 && step>target){
step = target;
}
//赋值元素
ele.style[attr] = step + "px";
//让元素到达目标值时停止 800px
if(step == target){
clearInterval(ele.timer);
//当move函数执行完毕后, 就执行它了
//当条件都满足时才执行callback回调函数
callback && callback();
}
},30)//步长是30
}
第一步:我们先来实现那个圆形按钮的点击事件。 //说明一下,setBtn();是设置按钮的背景跟随。 像这样。
像这样。
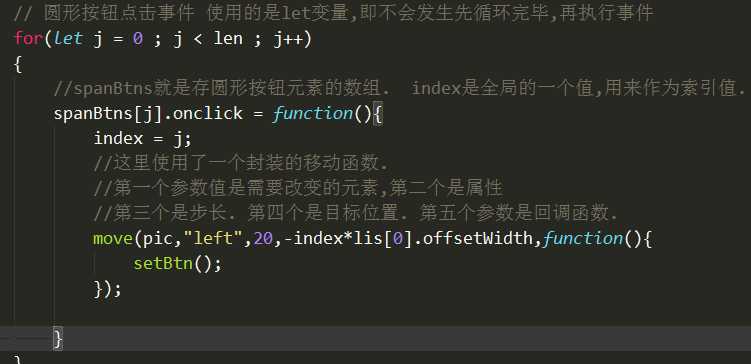
第二步:实现左右两个按钮的点击事件
先做右边的点击事件,实现
//onNext function Next(){ index ++;
//len 指的是图片的数组的个数 - 2 因为span按钮只有5个,索引从0到4 if(index > len) { index = 0; } // - 移动单张图片的宽度 * index 回调函数 move(pic,"left",20,-index * lis[0].offsetWidth,setBtn); }
做左边的点击事件,实现
function Pre(){ //全局的索引值 减1 index --; if(index < 0 ) { index = len - 1; pic.style.left = -len * lis[0].offsetWidth + "px"; } //没有使用回调函数 是为了做一个返回去的效果. move(pic,"left",20,-index * lis[0].offsetWidth); //按钮背景跟随 setBtn(); }
自动轮播,实现:
//自动轮播 function autoPlay(){ timer = setInterval(function(){ Next(); },3000); }
所有代码实现:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<style type="text/css">
*{
margin: 0;
padding: 0;
}
.slider{
width: 500px;
height: 300px;
border: 1px solid;
margin: 50px auto;
position: relative;
/* overflow: hidden; */
}
.slider .pic{
/* width: 500px; */
/* width: calc(500px*6); */
height: 300px;
position: absolute;
left: 0;
}
.slider .pic li{
width: 500px;
height: 300px;
list-style: none;
float: left;
}
.slider .pic li img{
width: 100%;
height: 100%;
}
.slider .btn{
width: 150px;
height: 20px;
position: relative;
margin: 0 auto;
top: 260px;
}
.slider .btn span{
float: left;
width: 20px;
height: 20px;
background-color: #000000;
color: #fff;
border-radius:50%;
font-size: 12px;
text-align: center;
line-height: 20px;
margin: 0 5px;
cursor: pointer;
}
.bigBtn{
width: 100%;
height: 50px;
position: absolute;
top: 50%;
margin-top: -25px;
}
.bigBtn div{
width: 50px;
height: 50px;
background-color: #000000;
color: #fff;
font-size: 30px;
text-align: center;
line-height: 50px;
cursor: pointer;
}
.bigBtn div:nth-child(1){
float: left;
}
.bigBtn div:nth-child(2){
float: right;
}
.bg{
background-color: greenyellow !important;
}
#sliderBox{
margin: 0 auto;
width: 500px;
height: 300px;
overflow: hidden;
position: absolute;
top: 0;
left: 0;
}
</style>
</head>
<body>
<div class="slider">
<div id="sliderBox">
<div class="pic">
<ul>
<li><img src="img/pic1.jpg" ></li>
<li><img src="img/pic2.jpg" ></li>
<li><img src="img/pic3.jpg" ></li>
<li><img src="img/pic4.jpg" ></li>
<li><img src="img/pic5.jpg" ></li>
<li><img src="img/pic1.jpg" ></li>
</ul>
</div>
</div>
<div class="btn">
<span>1</span>
<span>2</span>
<span>3</span>
<span>4</span>
<span>5</span>
</div>
<div class="bigBtn">
<div class="previous"><</div>
<div class="next">></div>
</div>
</div>
<script src="js/move.js" type="text/javascript" charset="utf-8"></script>
<script type="text/javascript">
//获取所有元素
let slider = document.querySelector(".slider")
let lis = document.querySelectorAll("li");
let spanBtns = document.querySelectorAll(".btn span");
let previous = document.querySelector(".previous");
let next = document.querySelector(".next");
let pic = document.querySelector(".pic");
//设置元素的索引值 全局索引
var index = 0;
//图片数组的长度 4
let len = lis.length - 1 ;
//设置初始pic长度.
pic.style.width = (len + 2)*parseInt(getStyle(lis[0],"width"))+ "px";
//设置定时器
let timer = null;
// 圆形按钮点击事件 使用的是let变量,即不会发生先循环完毕,再执行事件
for(let j = 0 ; j < len ; j++)
{
//spanBtns就是存圆形按钮元素的数组. index是全局的一个值,用来作为索引值.
spanBtns[j].onclick = function(){
index = j;
//这里使用了一个封装的移动函数.
//第一个参数值是需要改变的元素,第二个是属性
//第三个是步长. 第四个是目标位置. 第五个参数是回调函数.
move(pic,"left",20,-index*lis[0].offsetWidth,function(){
setBtn();
});
}
}
function setBtn(){
if(index >= len)
{
index = 0;
pic.style.left = 0;
}
for(var i = 0 ; i < len ; i++)
{
spanBtns[i].className = "";
}
spanBtns[index].className = "bg";
}
//onNext
function Next(){
index ++;
if(index > len)
{
index = 0;
}
// - 移动单张图片的宽度 * index 回调函数
move(pic,"left",20,-index * lis[0].offsetWidth,setBtn);
}
function Pre(){
//全局的索引值 减1
index --;
if(index < 0 )
{
index = len - 1;
pic.style.left = -len * lis[0].offsetWidth + "px";
}
//没有使用回调函数 是为了做一个返回去的效果.
move(pic,"left",20,-index * lis[0].offsetWidth);
//按钮背景跟随
setBtn();
}
//绑定点击事件
previous.onclick = Pre;
next.onclick = Next;
slider.onmouseover = function(){
clearInterval(timer);
}
slider.onmouseout = function(){
autoPlay();
}
//自动轮播
function autoPlay(){
timer = setInterval(function(){
Next();
},3000);
}
setBtn();
autoPlay();
</script>
</body>
</html>
引用的js文件:
/* 封装move函数 ele 要传递的元素 attr 属性 --- 字符串 speed 速度 正负值 target 目标值(结束位置) callback 回调函数 --- 当这个函数执行完毕后,再去调用它 */ function move(ele, attr, speed, target, callback){ //获取当前的位置 //从左往右进行移动 --- current<target speed //从右往左进行移动 --- current>target -speed var current = parseInt(getStyle(ele, attr)); // 810 > 800 if(current>target){ speed = -speed; } //定时器累加问题 --- 先清除再开启 clearInterval(ele.timer); ele.timer = setInterval(function(){ //获取元素的现在位置 var begin = parseInt(getStyle(ele, attr)); //步长 var step = begin + speed; //判断当step>800, 让step = 800 //从左往右进行移动 --- speed>0 正值 //从右往左进行移动 --- speed<0 负值 // -10 0 10 超过800直接变成 800 if(speed<0 && step<target || speed>0 && step>target){ step = target; } //赋值元素 ele.style[attr] = step + "px"; //让元素到达目标值时停止 800px if(step == target){ clearInterval(ele.timer); //当move函数执行完毕后, 就执行它了 //当条件都满足时才执行callback回调函数 callback && callback(); } },30) } //获取元素的方式 --- 注意点:如果在IE浏览器下, 要指定默认的值, 如果不指定获取的是auto function getStyle(obj, name){ if(window.getComputedStyle){ return getComputedStyle(obj, null)[name]; }else{ return obj.currentStyle[name]; } }
要移植使用的话,新建一个move.js 将最下面的代码拷进去 放在js文件夹下。
 类似这样的目录即可。
类似这样的目录即可。
下次的博客一定会写更好的。加油。