第一步、
我创建了一个基于.net的mvc项目,创建model,写入以下代码

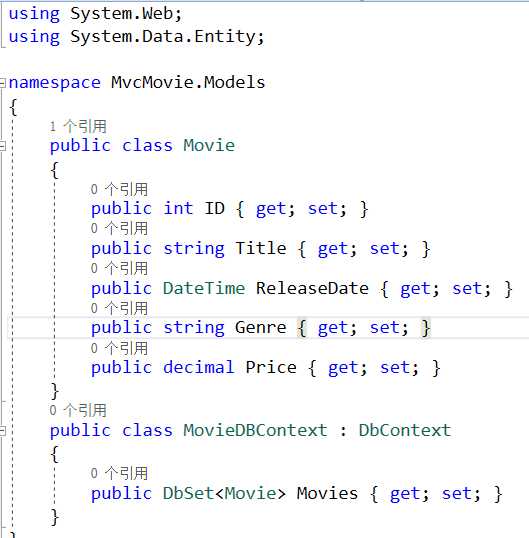
MovieDBContext类表示处理提取、 存储和更新的实体框架电影数据库上下文Movie类在数据库中的实例。 MovieDBContext派生自DbContext实体框架提供的基类。
若要引用将DbContext并DbSet,你需要添加以下using在文件顶部的语句:using System.Data.Entity;因为DbContext属于Entityframework
已添加模型 (在 MVC 中的 M)。 下一步中将使用数据库连接字符串。
第二步、

<add name=“MovieDBContext” connectionString=“Data Source=(LocalDb)\MSSQLLocalDB;Initial Catalog=aspnet-MvcMovie;Integrated Security=SSPI;AttachDBFilename=|DataDirectory|\Movies.mdf” providerName=“System.Data.SqlClient” />
第三步、
创建控制器
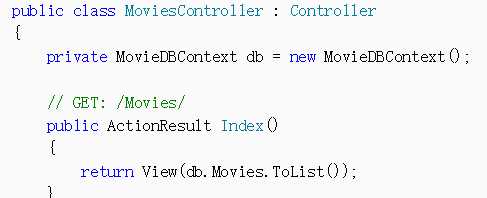
基架选择了带有视图的MVC5的控制器(用Entity Framework),——————-此控制器带有视图,并写好了CRUD
看MoviesController.cs的代码,