在页面中引入javascript文件的方式是多种多样的,本文介绍一种。
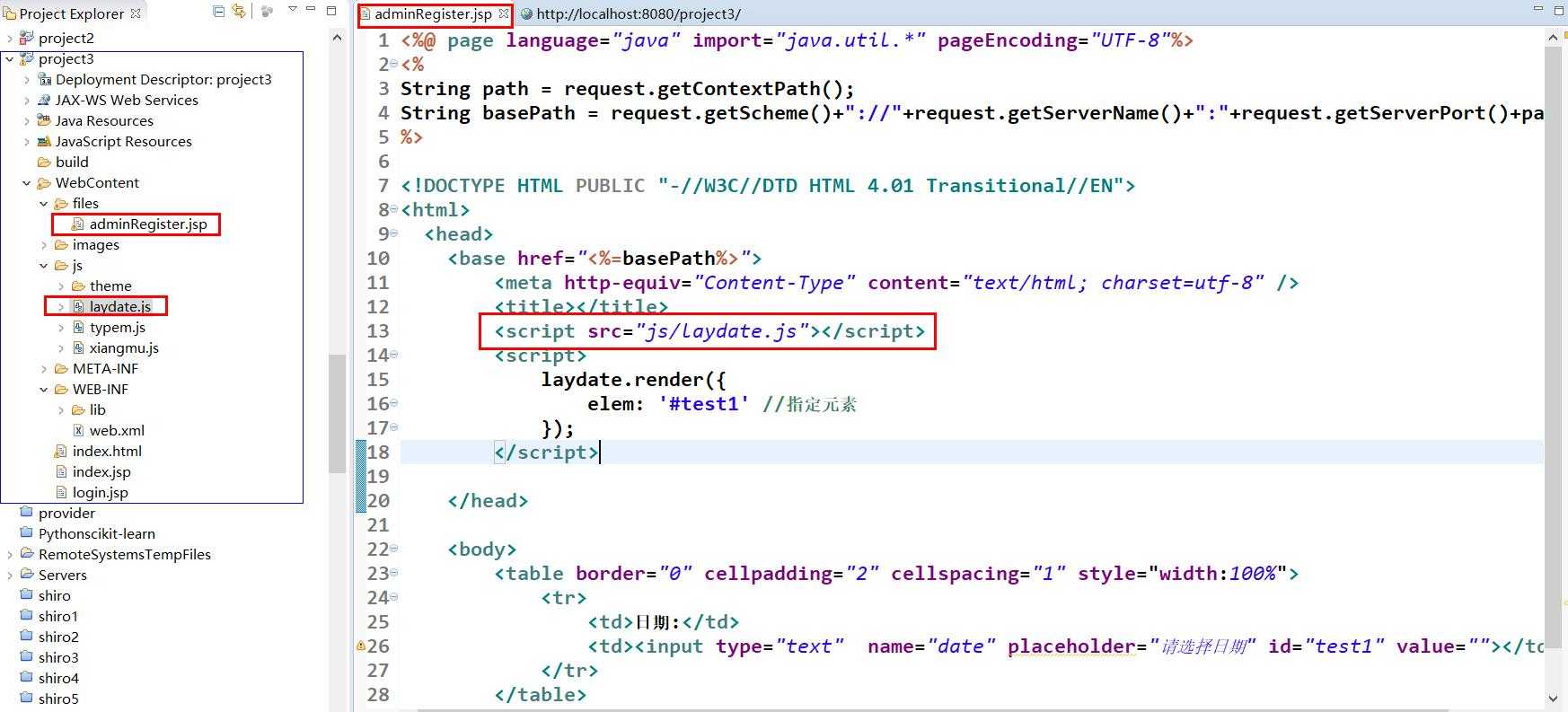
1.在eclipse中新建一个web项目(project3),目录结构如下:
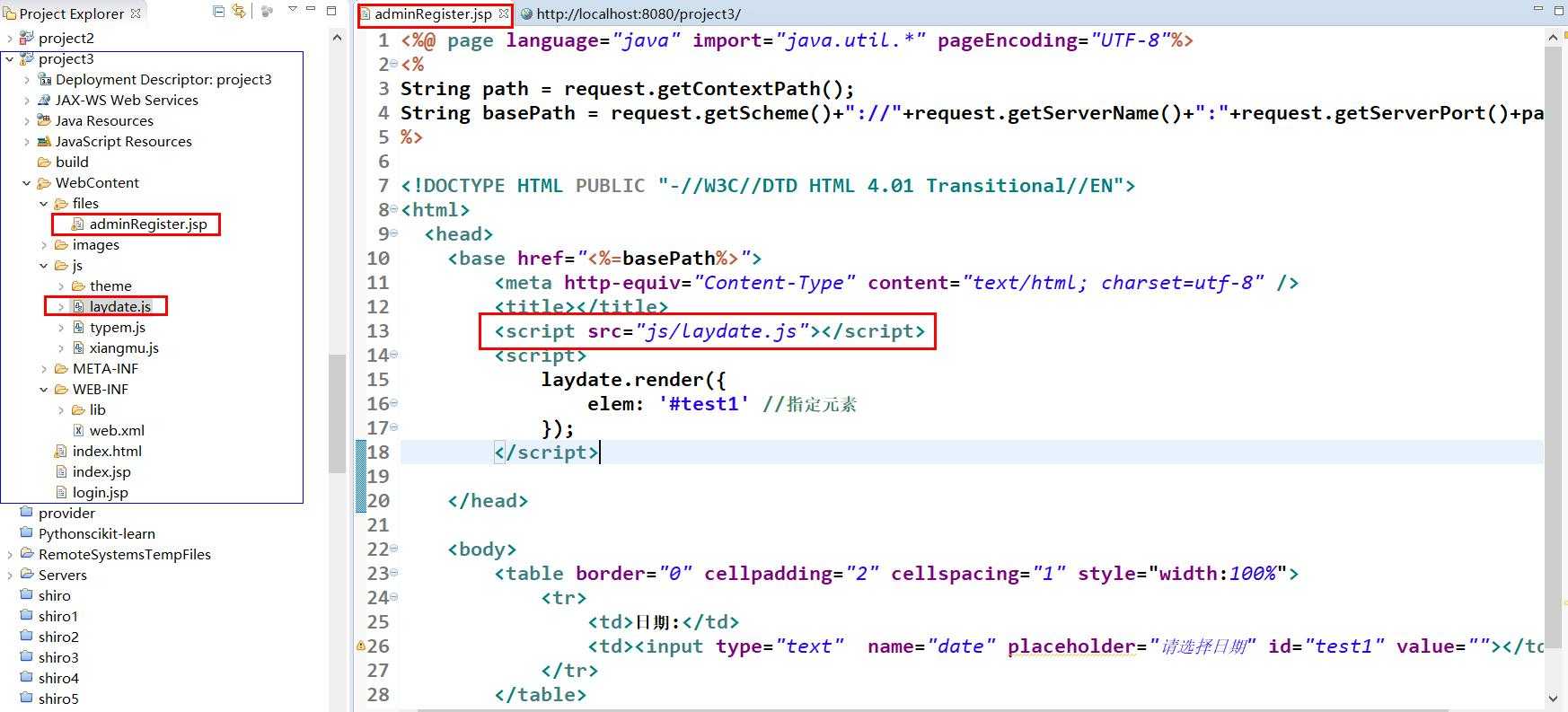
二:在jsp页面的最开始,获取项目的根路径。
<%
String path = request.getContextPath();
String basePath = request.getScheme()+”://”+request.getServerName()+”:”+request.getServerPort()+path+”/”;
%>
则:
path=project3
basePath=http://localhost:8080/project3/
三:在<head></head>中,插入下述代码:
<base href="<%=basePath%>"> //这句代码的作用是将整个页面的根路径设置为项目路径。
四:引入js文件
<script src="js/laydate.js"></script> //http://localhost:8080/project3/js/laydate.js
五:测试
<script> laydate.render({ elem: ‘#test1‘ //指定元素 }); </script>
<body>
<input type="text" name="date" placeholder="请选择日期" id="test1" value="">
</body>
六:结果
