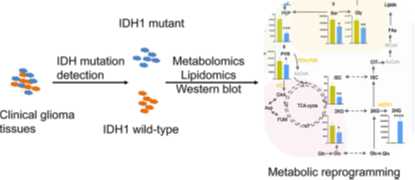
题目:Integrated Metabolomics and Lipidomics Analyses Reveal Metabolic Reprogramming in Human Glioma with IDH1 Mutation
期刊:Journal of Proteome Research
发表时间:December 31, 2018
DOI:10.1021/acs.jproteome.8b00663
作者单位:
中科院大连化物所
中国科学院大学
郑州大学附属第一医院
分享人:黄旭蕾
采用技术:代谢组学和脂质组学
参照组和实验组:IDH1野生型神经胶质瘤和IDH1突变型神经胶质瘤
概述:
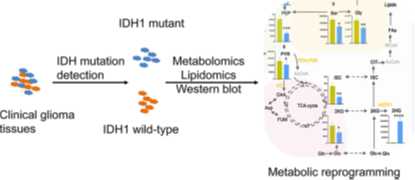
异柠檬酸脱氢酶(IDH1)的突变与低级别胶质瘤和继发性胶质母细胞瘤密切相关。本研究对郑州大学第一附属医院41名胶质瘤患者的脑肿瘤组织样本进行代谢组学和脂质组学分析,使用的检测工具是GC-MS和LC-MS。总共有鉴定出619种代谢物。结果显示,与IDH1野生型胶质瘤相比,在IDH1突变体胶质瘤组织中从糖酵解到糖尿病的大量代谢改变。
具体代谢物通路变化
(1)胶质瘤组织中发现了18种氨基酸,10种有机酸和268种脂类发生变化。大多数氨基酸,短链酰基肉碱(C2-C5),乙酰肉碱(CN-C2)与游离肉毒碱的比例,以及丙酰肉碱(CN-C3)与游离肉碱的比例显着升高。脂质合成前体甘油-3-磷酸在胶质瘤组织中也升高,而其他如甘油和肌醇磷酸盐显着降低(图S2a和表S2)。同样,在神经胶质瘤组织中,总脂肪酸和总磷脂酰脂质包括磷脂酰胆碱(PC),磷脂酰乙醇胺(PE),神经酰胺(Cer)和心磷脂(CL)显着降低(图S2a)。此外,对不同代谢物的途径分析证实了氨基酸代谢的深刻破坏(包括甘氨酸,丝氨酸和苏氨酸代谢;精氨酸和脯氨酸代谢;以及丙氨酸,天冬氨酸和谷氨酸代谢),氨酰基-tRNA生物合成和甘油磷脂代谢。神经胶质瘤组织(图S2b)与野生型胶质瘤组织相比,在IDH1突变体胶质瘤组织中检测到248种代谢物和脂质显着改变,63种代谢物升高,185种降低。
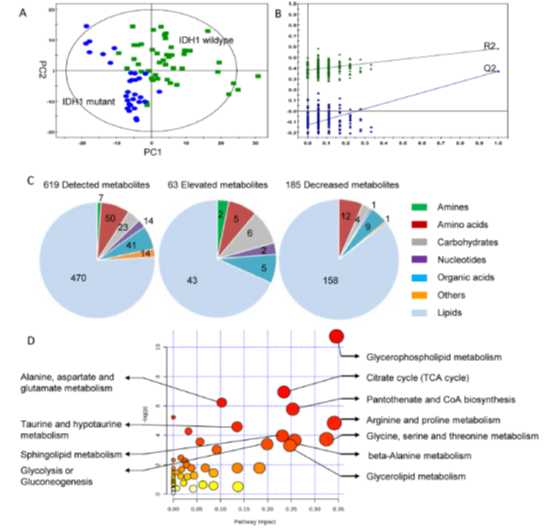
(2)此外,对这些不同代谢物的通路分析证实了TCA循环,糖酵解和糖异生,氨基酸代谢(包括甘氨酸,丝氨酸和苏氨酸代谢;精氨酸和脯氨酸代谢;丙氨酸,天冬氨酸和谷氨酸代谢;牛磺酸和牛磺酸代谢)的严重破坏。并且具有IDH1突变的胶质瘤组织中的脂质代谢(包括甘油脂代谢,甘油磷脂代谢和鞘脂代谢)和泛酸和辅酶A生物合成;和β丙氨酸代谢),脂质代谢(包括甘油脂代谢,甘油磷脂代谢和鞘脂代谢),以及泛酸和辅酶A在具有IDH1突变的神经胶质瘤组织中的生物合成。进行了临床IDH1突变胶质瘤标本的综合代谢调查,以探索其在真实微环境中的特定代谢重编程。与IDH1野生型胶质瘤相比,在IDH1突变体胶质瘤组织中鉴定了从糖酵解到脂质代谢的大量代谢改变。值得注意的是,两组中三羧酸(TCA)循环中间体的水平相似,发现更多的丙酮酸进入IDH1突变体胶质瘤的TCA循环。尽管膜磷脂酰脂质没有改变,但脂肪酰链的数量也减少了,表现甘油三酯和鞘脂为降低的。低级脂肪酰基库可以由IDH1突变体神经胶质瘤中长链酰基辅酶A合成酶1(ACSL1),ACSL4和非常长链酰基辅酶A合成酶3(ACSVL3)的较低蛋白质表达水平介导。基于癌症基因组图谱(TCGA)RNA测序数据,进一步发现较低的ACSL1有助于IDH1突变体神经胶质瘤患者更好的存活。我们的研究为人类IDH1突变型胶质瘤的组织代谢提供了有价值的见解,并揭示了新的脂质相关靶点。
从284个显着变化的变量(包括检测到的代谢物,检测到的脂质和计算的指数)中,158在进一步的SAM分析后保留,以研究不同变量的重要性。与IDH1野生型相比,2-羟基戊二酸(2-HG)是IDH1突变体胶质瘤中最显着升高的代谢物,并且与其配对的邻近组织相比,野生型中没有2-HG升高。所有检测到的甘油三酯(TG)在IDH1突变体胶质瘤中均显着降低,这也是显着的。

黄色柱子代表野生型,蓝色柱子代表IDH1突变体胶质瘤
具体脂质通路变化
游离脂肪酸的总量没有显著变化,脂肪酸总量没有显着变化。在IDH1突变型胶质瘤中, FA 18:0,FA 20:3,FA 22:5和FA 20:5含量升高,饱和的极长链脂肪酸(SVLFA)含量减少,磷脂酰丝氨酸(PS)含量增加,鞘脂途径中TG及其中间体的大量减少,表明存储在TG中的总脂肪酸含量减少。脂质合成前体(包括甘油,甘油-3-磷酸,乙醇胺和肌醇)增加,甘油磷酸胆碱(GPC)和甘油基磷酸乙醇胺(GPE)显着升高。脂质合成前体,GPC和GPE含量升高表明脂肪酰链不足。肿瘤的脂肪酰基链通常新生合成而不是胞外摄取脂肪酸,因此,癌细胞合成脂肪酸的速率提高。此外,脂肪酸合成酶(FASN),磷酸化乙酰辅酶A羧化酶(pACC)和ACC的组织蛋白水平可用于测量脂肪酸新生合成的酶活性。在IDH1突变型胶质瘤中, FASN水平没有变化,但pACC与ACC的比例显着降低,表明脂肪酸合成的酶活性增加。单不饱和脂肪酸与饱和脂肪酸(MUFA / SFA)和FA(18:1 + 16:1)/ FA(18:0 + 16:0)的比例,反映了硬脂酰辅酶A去饱和酶(IDD)酶活性升高。TG降低可能是新生合成减少或着TG裂解。

酰基辅酶A合成酶与不同脂类的相关性分析
酰基辅酶A合成酶负责脂肪酸的脂质合成和β-氧化,与不同脂类的丰度相关,作者因此做了酰基辅酶A合成酶与不同脂类的相关性分析。网络相关分析显示,与野生型相比,在IDH1突变体胶质瘤中ACSL与总脂质之间、以及ACSL与一些蛋白质如PCE,pACC和CPT1c之间的相关性更强。,
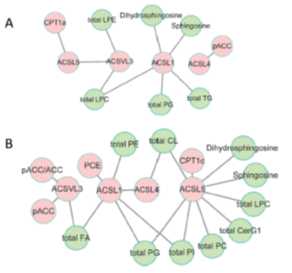
(A)野生型(B)IDH1突变体胶质瘤