‘‘‘
定义MySQL类:
1.对象有id、host、port三个属性
2.定义工具create_id,在实例化时为每个对象随机生成id,保证id唯一
3.提供两种实例化方式,方式一:用户传入host和port 方式二:从配置文件中读取host和port进行实例化
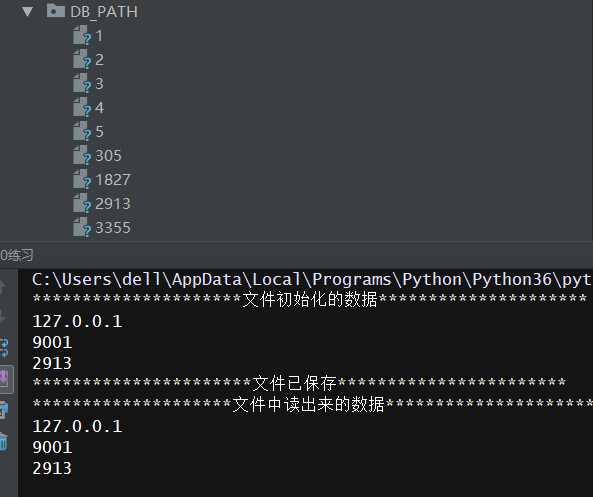
4.为对象定制方法,save和get_obj_by_id,save能自动将对象序列化到文件中,文件路径为配置文件中DB_PATH,文件名为id号,保存之前验证对象是否已经存在,若存在则抛出异常;get_obj_by_id方法用来从文件中反序列化出对象
‘‘‘
代码:
import time import hashlib import os import pickle import random import settings class MySQL: BASE_DIR = os.path.dirname(os.path.abspath(__file__)) def __init__(self,host,port): self.host = host self.port = port #注意返回的是int型的,需要转化为str类型 self.id = str(self.create_id()) def create_id(self): return random.randint(1,5555) #或者用下面的生成时间戳的MD5编码 # m = hashlib.md5(str(time.time()).encode(‘utf-8‘)) # return m.hexdigest() def save(self): file_name = os.path.join(self.BASE_DIR,‘DB_PATH‘,str(self.id)) #os.walk方法——files为文件夹下的文件名列表 for root,dirs,files in os.walk(os.path.join(self.BASE_DIR,‘DB_PATH‘)): if self.id in files: raise FileNotFoundError(‘文件已存在!‘) with open(file_name,‘wb‘) as f: pickle.dump(self,f) print(‘文件已保存‘.center(50, ‘*‘)) def get_obj_by_id(self,id): file_name = os.path.join(self.BASE_DIR, ‘DB_PATH‘,str(id)) with open(file_name,‘rb‘) as f: #pickle的load方法 data = pickle.load(f) return data if __name__ == ‘__main__‘: mysql = MySQL(settings.HOST,settings.PORT) print(‘文件初始化的数据‘.center(50, ‘*‘)) print(mysql.host) print(mysql.port) print(mysql.id) mysql.save() data = mysql.get_obj_by_id(mysql.id) print(‘文件中读出来的数据‘.center(50,‘*‘)) print(data.host) print(data.port) print(data.id)
结果: