
前言
在4月21日晚,Vue作者尤雨溪在哔哩哔哩直播分享了Vue.js 3.0 Beta最新进展。 里面尤大大所提到他最近在做的这个小工具 vite ,一个实验性的no build的vue开发服务器。(这个小工具可以支持热更新,且不用预编译)
一丶安装
命令行复制以下
mkdir vue-vite新建文件夹npm init - y初始化项目npm i vite - g全局安装vitenpm i vue@next安装vue3.0 beta版
二丶新建文件
在项目目录下新建 一下文件
index.html
<div id="app"></div> <script type="module"> import { createApp } from ‘vue‘ import Comp from ‘./Comp.vue‘ createApp(Comp).mount(‘#app‘) </script>
Comp.vue
<template> <button @click="count++">{{ count }}</button> </template> <script> export default { data: () => ({ count: 0 }) } </script> <style scoped> button { color: red } </style>
main.js
import { createApp } from ‘vue‘
import Comp from ‘./Comp.vue‘
createApp(Comp).mount(‘#app‘)
三丶启动
cd vue-vite进入目录vite启动项目
然后你就可以看到一下命令行启动提示了

ctrl+鼠标左键点击进去看到这样的页面就代表你启动成功了
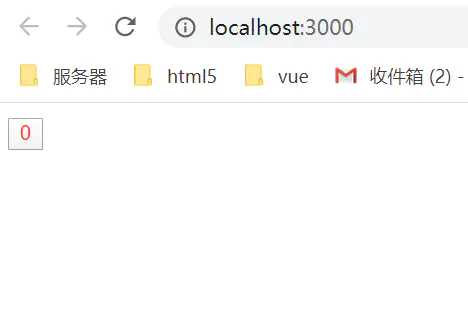
然后你可以尝试修改 Comp.vue 看看效果是不是那样神奇,不用预编译,且支持热更新
点击跳转原文