1.对mvc项目安装nuget Install-Package FluentValidation.Mvc5
2.配置验证器
protected void Application_Start() { AreaRegistration.RegisterAllAreas(); RegisterGlobalFilters(GlobalFilters.Filters); RegisterRoutes(RouteTable.Routes); FluentValidationModelValidatorProvider.Configure(); }
3.添加测试验证器
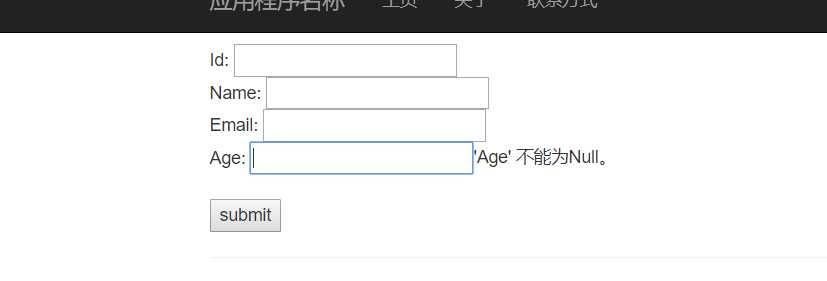
[Validator(typeof(PersonValidator))] public class Person { public int Id { get; set; } public string Name { get; set; } public string Email { get; set; } public int Age { get; set; } } public class PersonValidator : AbstractValidator<Person> { public PersonValidator() { RuleFor(x => x.Id).NotNull(); RuleFor(x => x.Name).Length(0, 10); RuleFor(x => x.Email).EmailAddress(); RuleFor(x => x.Age).InclusiveBetween(18, 60); } }

public ActionResult Create([CustomizeValidator(RuleSet = "MyRuleset")] Person person) { if (!ModelState.IsValid) { // re-render the view when validation failed. return View("Create", person); } TempData["notice"] = "Person successfully created"; return RedirectToAction("Index"); }
还可以在验证的时候指定规则集合