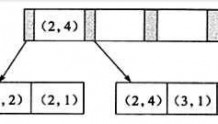
什么是表分区?
表分区分为水平表分区和垂直表分区,水平表分区就是将一个具有大量数据的表,进行拆分为具有相同表结构的若干个表;而垂直表分区就是把一个拥有多个字段的表,根据需要进行拆分列,然后根据某一个字段进行关联。
表分区分为以下五个步骤:
1、创建文件组
2、创建数据文件
3、创建分区函数
4、创建分区方案
5、创建分区表
水平表分区
创建文件组:
语法:
-- 创建文件组语法alter database <数据库名> add filegroup <文件组名>

alter database Test add filegroup GroupOnealter database Test add filegroup GroupTwoalter database Test add filegroup GroupThreealter database Test add filegroup GroupFouralter database Test add filegroup GroupFive
创建数据文件到指定文件组:
语法:
-- 创建数据文件到指定文件组语法alter database <数据库名称> add file <文件属性> to filegroup <文件组名称><文件属性>( name=文件的逻辑名称, filename=文件的物理名称, size=文件初始大小, filegrowth=文件自动增长量(数值或百分比), maxsize=文件增长的最大值)
alter database Test add file( name=N‘OneFile‘, filename=N‘D:\DataDB\OneFile.mdf‘, size=3MB, filegrowth=10%, maxsize=unlimited -- 无限大小)to filegroup GroupOnealter database Test add file( name=N‘TwoFile‘, filename=N‘D:\DataDB\TwoFile.mdf‘, size=3MB, filegrowth=10%, maxsize=unlimited -- 无限大小)to filegroup GroupTwoalter database Test add file( name=N‘ThreeFile‘, filename=N‘D:\DataDB\ThreeFile.mdf‘, size=3MB, filegrowth=10%, maxsize=unlimited -- 无限大小)to filegroup GroupThreealter database Test add file( name=N‘FourFile‘, filename=N‘D:\DataDB\FourFile.mdf‘, size=3MB, filegrowth=10%, maxsize=unlimited -- 无限大小)to filegroup GroupFouralter database Test add file( name=N‘FiveFile‘, filename=N‘D:\DataDB\FiveFile.mdf‘, size=3MB, filegrowth=10%, maxsize=unlimited -- 无限大小)to filegroup GroupFive
创建分区函数:
创建一个分区函数,创建分区函数的目的是告诉 SQL Server 以什么方式对分区表进行分区。
语法:
create partition function -- 创建分区函数Part_Fun(int) -- 分区函数名(分区列类型)as range [left/right] -- 左置/右置,即边界值的存储位置,如果设置为右置,边界值存到下一个表for values (‘1000‘,‘2000‘,‘3000‘,‘4000‘,‘5000‘) -- 设置每个分区表的边界值
create partition function Part_Fun(int) as range right for values (‘1000‘,‘2000‘,‘3000‘,‘4000‘,‘5000‘)
删除分区函数:
--删除分区函数语法drop partition function <分区函数名>--删除名为 Part_Fun 的分区函数drop partition function Part_Fun
PS:只有当分区函数没有应用到分区方案中时,指定的分区函数才能被删除。
创建分区方案:
分区方案的作用是将分区函数生成的分区映射到文件组中去。分区函数的作用是告诉SQL Server,如何将数据进行分区,而分区方案的作用则是告诉 SQL Server 将已分区的数据放在哪个文件组中。
语法:
--创建分区方案语法create partition scheme -- 创建分区方案<分区方案名称> -- 分区方案名称as partition <分区函数名称> -- 指定分区函数名称to (文件组名称,,,,) -- 指定分区函数划分出来的数据对应存放的文件组
create partition scheme -- 创建分区方案Part_Plan -- 分区方案名称as partition Part_Fun -- 分区函数名称to (‘GroupOne‘,‘GroupTwo‘,‘GroupThree‘,‘GroupFour‘,‘GroupFive‘) -- 分区文件组
一执行,结果报错了。
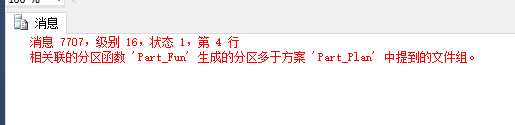
不对呀,我明明建立的是五个分区文件组,分区函数也是分为五份的啊。其实这里的意思应该就是后续数据的问题了,首先不可能保证这个表永远就 5000 条数据的,所以他在这里的意思就是后续数据存储的文件组。这里我把后续数据放在最后一个文件组里面。
create partition scheme -- 创建分区方案Part_Plan -- 分区方案名称as partition Part_Fun -- 分区函数名称to (‘GroupOne‘,‘GroupTwo‘,‘GroupThree‘,‘GroupFour‘,‘GroupFive‘,‘GroupFive‘) -- 分区文件组
删除分区方案:
--删除分区方案语法drop partition scheme<分区方案名称>--删除名为 Part_Plan 的分区方案drop partition scheme Part_Plan
PS:当没有分区表引用该分区方案时,才能对其进行删除。
创建分区表:
语法:
--创建分区表语法create table <表名> -- 表名称( column1 int not null primary key nonclustered, -- 字段名称、字段类型、是否可空、主键约束、非聚集索引 column2 int not null ) on <分区方案名>(分区列名) -- 分区方案的名称(指定要依据分区的列名)
create table US_Info( ID int not null primary key identity(1,1), Name nvarchar(32) null, CreateTime nvarchar(32) null)on Part_Plan(ID)
PS:如果在表中创建有主键、唯一索引、聚集索引,则分区依据列必须为该列之一。即分区依据列必须建立在主键、唯一索引、聚集索引之上。
创建分区索引:
语法:
--创建分区索引语法create [ unique [ clustered | nonclustered ] ] -- unique 唯一 clustered 聚集 nonclustered 非聚集index <索引名称> -- 指定索引名称on <表名>(列名) -- 指定表名(指定列名)on <分区方案名>(分区依据列名) -- 分区方案名称(分区依据列名)
create nonclustered index Part_Non_Name on US_Info(Name) on Part_Plan(ID)
在表 US_Info 中插入5000条数据:
declare @I intset @I=1while(@I<=5000)begin insert into US_Info(Name,CreateTime) values(‘名称‘+convert(nvarchar,@I),Convert(nvarchar,GETDATE(),121)) set @I=@I+1endselect * from US_Info
查询指定值位于数据表哪个分区中:
-- 查询指定值位于数据表哪个分区中select $partition.Part_Fun(‘3050‘) -- 返回 4,表示位于第四个分区中
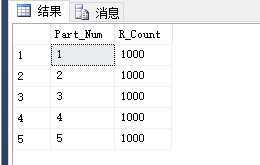
查询分区表中,每个分区存在的数据的行数:
--查看分区表中,每个分区存在的数据的行数select $partition.Part_Fun(ID) as Part_Num,count(1) as R_Countfrom US_Infogroup by $partition.Part_Fun(ID)
查询指定分区中的数据:
-- 查询指定分区中的数据select * from US_Info where $partition.Part_Fun(ID)=3
拆分分区:
在分区函数中新增一个边界值,即可将 1 个分区拆分为 2 个。
--将第 3 个分区拆分为 2 个分区alter partition function Part_Fun()split range(N‘2500‘)
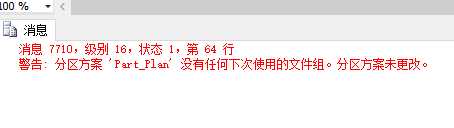
一执行,报错了,拆分不了,因为前面我们已经用分区函数指定了分区和文件组,那就要先添加一个文件组。
为分区方案指定下一个文件组:
-- 添加一个文件组 GroupSixalter database Test add filegroup GroupSix-- 添加一个数据文件 alter database Test add file( name=N‘SixFile‘, filename=N‘D:\DataDB\SixFile.mdf‘, size=3MB, filegrowth=10%, maxsize=unlimited -- 无限大小)to filegroup GroupSix-- 为分区方案指定下一个文件组alter partition scheme Part_Plan -- 分区方案名称next used GroupSix -- 下一个文件组名称
然后再来对分区进行拆分:
--将第 3 个分区拆分为 2 个分区alter partition function Part_Fun() -- 分区函数split range -- 分割界限(N‘2500‘) -- 分区界限值
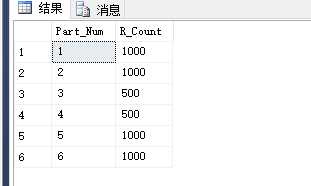
合并分区:
与拆分分区相反,去除一个边界值即可。
-- 将第 3 个分区与第 4 个分区合并alter partition function Part_Fun() -- 分区函数merge range -- 合并界限(N‘2500‘) -- 合并界限值
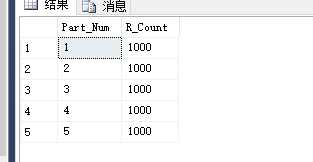
复制分区表中的数据到普通表:
复制分区表中的数据到普通表需要满足以下条件:
数据表的结构必须相同,即字段数量、字段类型等,字段与字段之间必须对应。
两个表必须位于同一文件组,所以创建普通表的时候就需要指定文件组。
create table US_Info_back -- 创建普通表的表名( ID int not null primary key identity(1,1), -- 列定义 Name nvarchar(32) null, CreateTime nvarchar(32) null)on GroupThree -- 指定文件组
将分区表中的数据复制到普通表:
-- 将分区表 US_Info 中的第 3 个分区的数据复制到普通表 US_Info_back 中alter table US_Info switch partition 3 to US_Info_backselect * from US_Info_back
将普通表中的数据复制到分区表:
--将普通表 US_Info_back 中的数据复制到分区表 US_Info 中的第 6 个分区alter table US_Info_back -- 普通表名switch to US_Info -- 分区表名partition 6 -- 指定分区
PS:将普通表中的数据复制到分区表时,需要先删除分区表的索引。
将普通表转换为分区表:
当数据库已经存在数据的时候,就不能像上面那样直接建立分区表了,只能将普通表转换为分区表,只需在该普通表上创建一个聚集索引,并在该聚集索引中使用分区方案即可。
如果是已经存在的聚集索引,那么需要删除然后重新建立,并使用分区方案。
现在我有一个现成的表 UserInfo,因为它存在一个主键,而建立主键时,系统会自动为主键列添加聚集索引,因为这个聚集索引没法删除,所以我现在要先删除这个主键,然后重新建立一个主键,并设置为非聚集索引,然后为主键创建一个聚集索引(会覆盖非聚集索引),并使用分区方案指定分区列即可。
-- 根据 指定表名 查询 表的约束exec sp_helpconstraint UserInfo -- UserInfo 表名-- 根据指定主键约束名删除指定表的主键约束alter table UserInfo drop constraint PK__UserInfo__5A2040BBA6D6767A -- 添加主键约束,但设置为非聚集索引alter table UserInfo add constraint PK__UserInfo__5A2040BBA6D6767A primary key nonclustered (U_Id)-- 添加一个聚集索引,并使用分区方案指定分区的列create clustered index CLU_StuNo -- 索引名称on UserInfo(U_Id) -- 指定添加索引的表(添加索引的列)on Part_Plan(U_Id) -- 分区方案名称(分区依据的列)
为这个表也插入5000条数据,看看效果:
declare @I intselect @I=U_Id from UserInfo order by U_Id descwhile(@I<=5000)begin insert into UserInfo(U_No,U_Name,U_Pwd) values(‘demo‘+convert(nvarchar,@I),‘demo‘+convert(nvarchar,@I),‘40D1C69C7B86064EA140C13CE8ED0E15‘) set @I=@I+1endselect * from UserInfogo
查看分区表中,每个分区存在的数据的行数:
--查看分区表中,每个分区存在的数据的行数select $partition.Part_Fun(U_Id) as Part_Num,count(1) as R_Countfrom UserInfo group by $partition.Part_Fun(U_Id)order by Part_Num
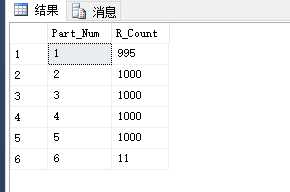
查看数据库分区信息 SQL(复制来的):
SELECT OBJECT_NAME(p.object_id) AS ObjectName, i.name AS IndexName, p.index_id AS IndexID, ds.name AS PartitionScheme, p.partition_number AS PartitionNumber, fg.name AS FileGroupName, prv_left.value AS LowerBoundaryValue, prv_right.value AS UpperBoundaryValue, CASE pf.boundary_value_on_right WHEN 1 THEN ‘RIGHT‘ ELSE ‘LEFT‘ END AS Range, p.rows AS RowsFROM sys.partitions AS pJOIN sys.indexes AS i ON i.object_id = p.object_id AND i.index_id = p.index_idJOIN sys.data_spaces AS ds ON ds.data_space_id = i.data_space_idJOIN sys.partition_schemes AS ps ON ps.data_space_id = ds.data_space_idJOIN sys.partition_functions AS pf ON pf.function_id = ps.function_idJOIN sys.destination_data_spaces AS dds2 ON dds2.partition_scheme_id = ps.data_space_id AND dds2.destination_id = p.partition_numberJOIN sys.filegroups AS fg ON fg.data_space_id = dds2.data_space_idLEFT JOIN sys.partition_range_values AS prv_left ON ps.function_id = prv_left.function_id AND prv_left.boundary_id = p.partition_number - 1LEFT JOIN sys.partition_range_values AS prv_right ON ps.function_id = prv_right.function_id AND prv_right.boundary_id = p.partition_number WHERE OBJECTPROPERTY(p.object_id, ‘ISMSShipped‘) = 0UNION ALLSELECT OBJECT_NAME(p.object_id) AS ObjectName, i.name AS IndexName, p.index_id AS IndexID, NULL AS PartitionScheme, p.partition_number AS PartitionNumber, fg.name AS FileGroupName, NULL AS LowerBoundaryValue, NULL AS UpperBoundaryValue, NULL AS Boundary, p.rows AS RowsFROM sys.partitions AS pJOIN sys.indexes AS i ON i.object_id = p.object_id AND i.index_id = p.index_idJOIN sys.data_spaces AS ds ON ds.data_space_id = i.data_space_idJOIN sys.filegroups AS fg ON fg.data_space_id = i.data_space_idWHERE OBJECTPROPERTY(p.object_id, ‘ISMSShipped‘) = 0ORDER BY ObjectName,IndexID,PartitionNumber
参考:
http://www.cnblogs.com/knowledgesea/p/3696912.html
http://blog.csdn.net/lgb934/article/details/8662956