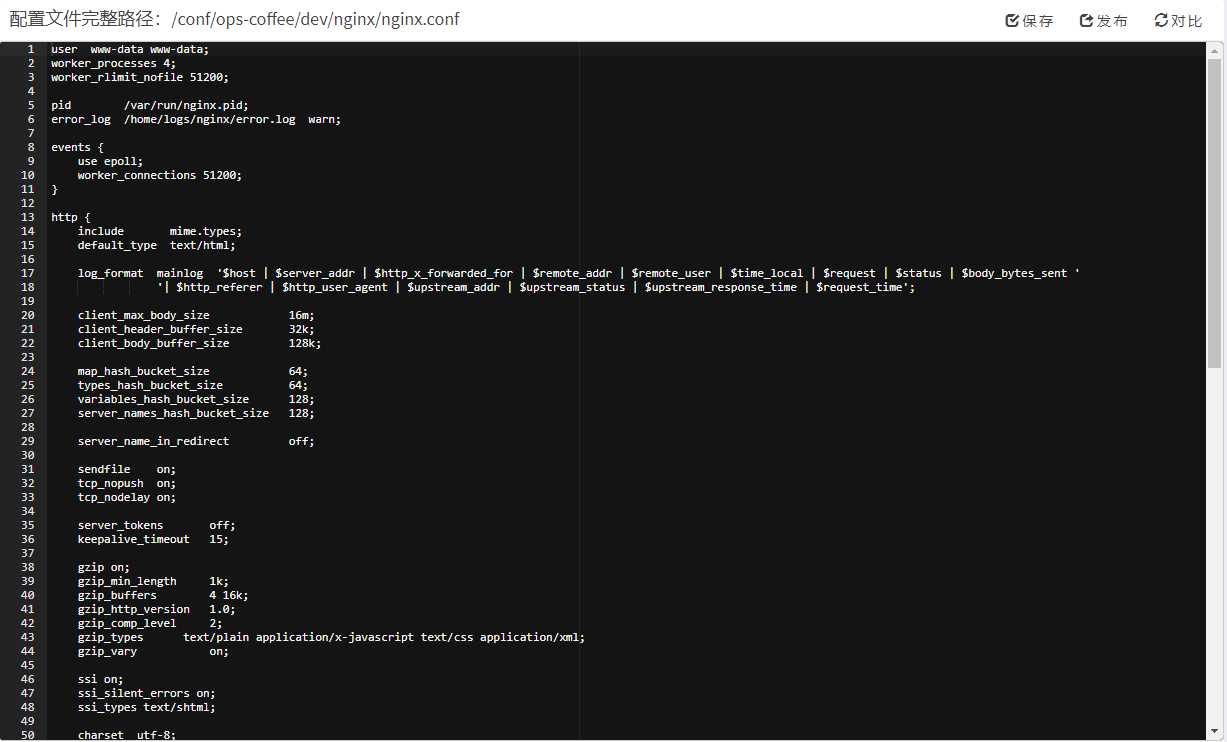
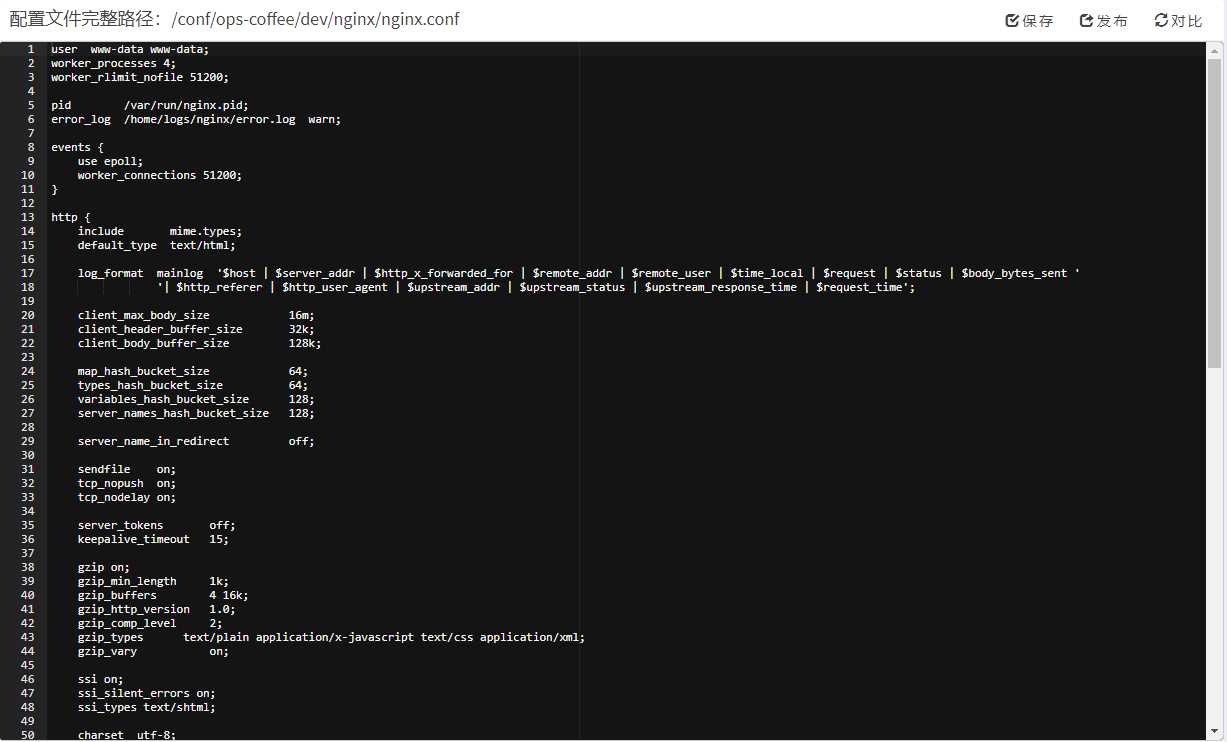
ace.js,这是一个用JavaScript编写的独立代码编辑器。支持超过120种语言的语法高亮,超过20个不同风格的主题,同时还支持实时语法检查,自定义快捷键绑定,代码折叠,搜索替换,自动缩进等等功能
项目地址为:https://ace.c9.io
我主要用它来替换表单中的textarea标签,以及实现在网页上修改文件的展示
基本使用
这个项目引入非常简单,只需要引入一个ace.js文件即可,然后实例化即可
// 引入js文件
<script src="/static/js/ace.js"></script>
<pre id="content" style="height:620px"></pre>
// 实例化编辑器
var editor = ace.edit("content");
github上除了源码文件外,ace还贴心的准备了编译好的项目文件,以方便用户使用,我们只需要将编译好的文件目录copy到我们项目的js目录下即可,编译好的仓库地址是:https://github.com/ajaxorg/ace-builds
推荐同时引入ext-searchbox.js文件,这样可以在编辑器中直接使用ctrl+F快捷键进行搜索
基本配置
ace有许多的配置项可供选择,通过这些配置项可以打造自己的个性编辑器
你可以通过setTheme来设置主题,需要注意的是主题文件要存在,并且需要与ace.js同级,命名规则为theme-主题名.js
editor.setTheme("ace/theme/twilight")
默认情况下编辑器为纯文本模式,你可以通过setMode来设置编辑器对应的语言模式,例如你想让其匹配markdown,就可以像下边这样配置,同样需要语言模式的文件存在,文件与ace.js同级,命名规则为mode-语言模式.js
editor.session.setMode("ace/mode/markdown")
通过setFontSize可以设置编辑器内文本字体的大小
editor.setFontSize(14);
通过setTabSize可以设置制表符的长度
editor.getSession().setTabSize(4);
同时可以通过setUseSoftTabs将制表符变成对应长度的空格
editor.session.setUseSoftTabs(true);
如果你不想编辑,可以通过setReadOnly可以将编辑器设置为只读模式
editor.setReadOnly(true)
默认情况下ace编辑器中会有一道竖线标识打印的边距,可以通过setShowPrintMargin来控制其是否显示
editor.setShowPrintMargin(false);
编辑器操作
ace可以方便的对编辑器内的数据进行获取和写入,甚至可以只获取选中的内容,同时也能实现获取行数,跳转到行等操作
通过getValue可以获取到编辑器中的全部数据
editor.getSession().getValue()
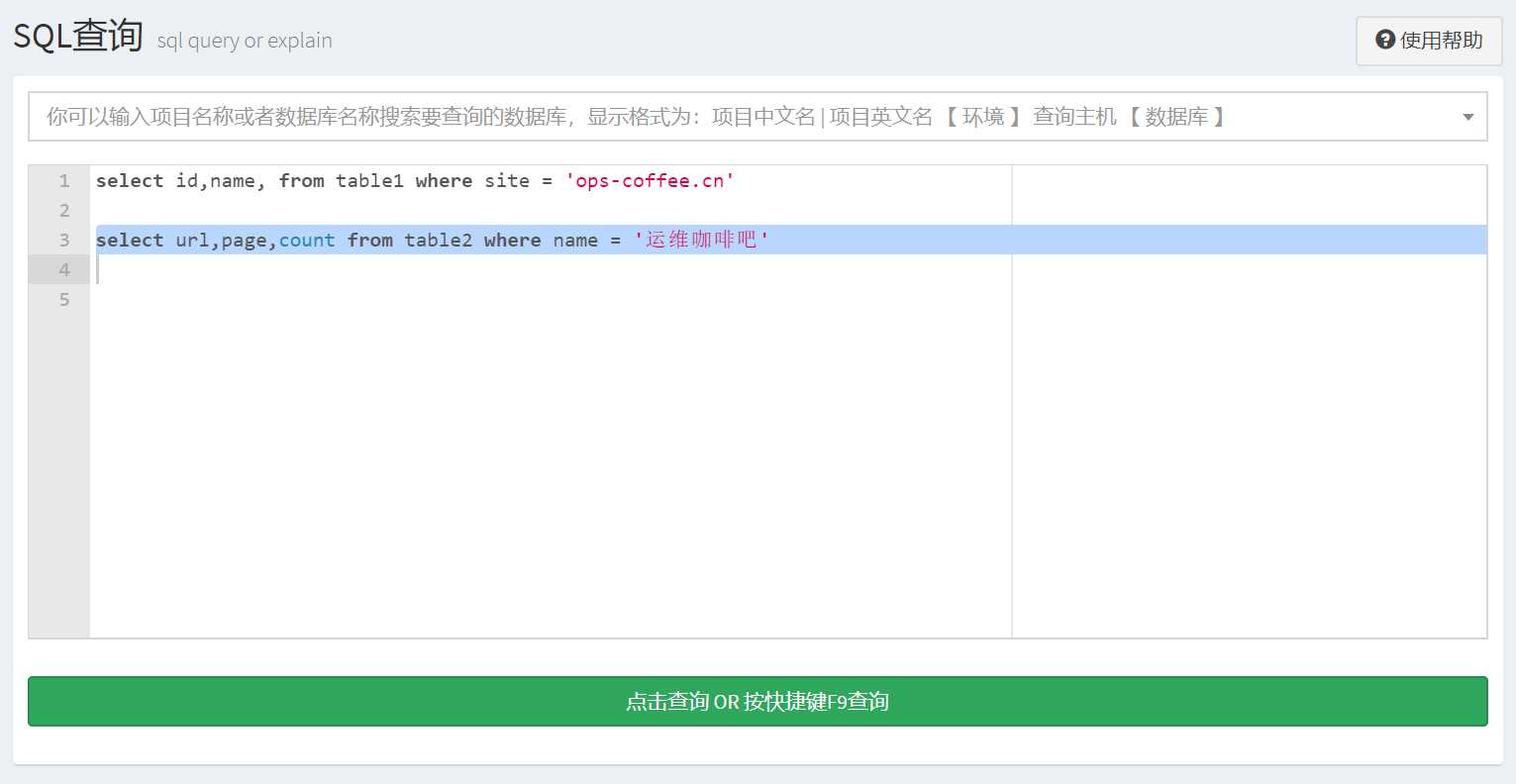
如果编辑器内有部分数据被选中,则可以通过getSelectionRange来获取选中的部分内容
editor.session.getTextRange(editor.getSelectionRange())
这在特性我实现SQL查询的功能中有用到,如果查询框内有多条SQL,可以选择其中一条SQL进行查询
通过setValue可以给编辑器初始化数据
editor.getSession().setValue("ops-coffee.cn")
当你想往编辑器插入数据时,可以通过insert在光标处插入数据
editor.insert(‘ops-coffee.cn‘)
通过getLength可以获取到编辑器内数据的总行数
editor.session.getLength()
goLine则可以跳转到指定的行
editor.gotoLine(37)
通过getCursor可以获取到编辑器内光标的位置,输出结果为一个标识行和列的字典,像这样:{row:13,column:37}
editor.selection.getCursor()
搜索与替换
ace还实现了强大的搜索和替换功能,可以单个替换也可以全部替换
通过find可以进行搜索
editor.find(‘ops-coffee‘, {
backwards: false,
wrap: false,
caseSensitive: false,
wholeWord: false,
regExp: false
});
find后边跟了两个参数, 第一个为要搜索的内容,第二个为搜索配置的字典, 字典内可以配置如下一些参数
- backwards: 是否反向搜索,默认为false
- wrap: 搜索到文档底部是否回到顶端,默认为false
- caseSensitive: 是否匹配大小写搜索,默认为false
- wholeWord: 是否匹配整个单词搜素,默认为false
- range: 搜索范围,要搜素整个文档则设置为空
- regExp: 搜索内容是否是正则表达式,默认为false
- start: 搜索起始位置
- skipCurrent: 是否不搜索当前行,默认为false
通过findAll可以高亮显示全部搜索到的内容
editor.findAll();
findNext则可以查找下一个搜索到的内容
editor.findNext();
findPrevious查找上一个匹配的内容
editor.findPrevious();
通过replace可以对当前find查找到的字符串进行替换
editor.replace(‘ops-coffee.cn‘);
而通过replaceAll则可以对find查找到的所有内容替换
editor.replaceAll(‘ops-coffee.cn‘);
需要注意的是,无论是replace还是replaceAll都需要配合find一起使用
监听变化
ace另一个强大的地方是实现了对编辑器的监听,除了可以监听内容的变化外,还能监听选中内容的变化,甚至是光标的变化
通过change可以监听到编辑器内容的变化
editor.getSession().on(‘change‘, function(e) {
console.log(‘内容有变化‘)
});
changeSelection则可以监听到选择内容的变化
editor.getSession().selection.on(‘changeSelection‘, function(e) {
console.log(‘选择内容有变化‘)
});
连光标的变化都可以通过changeCursor监听到
editor.getSession().selection.on(‘changeCursor‘, function(e) {
console.log(‘监听光标的变化‘)
});
替换textarea
html中的textarea比较鸡肋,连最基本的换行都无法实现,所以我通常都会用ace来代替form表单中的textarea,但默认情况下submit无法自动获取pre标签的数据做提交,这该如何处理呢?
一种简单的方式就是将textarea隐藏,同时创建一个ace编辑器来取代他,然后检测编辑器内数据的变化自动给填充到textarea内,完整的例子就像下边这样
<form class="form-horizontal" id="modalForm_Content" method="post" action="">{% csrf_token %}
<div class="form-group">
<label class="col-md-2 control-label"> 内容</label>
<div class="col-md-9">
<textarea class="form-control" id="form_content" name="content" rows="20"></textarea>
<pre id="content" style="height:415px"></pre>
</div>
</div>
</form>
// 加载ace editor
var editor = ace.edit("content");
var textarea = $(‘textarea[name="content"]‘).hide();
editor.getSession().on(‘change‘, function(){
textarea.val(editor.getSession().getValue());
});
非常完美的弥补了textarea的不足,简单好用且足够强大