
主机环境 centos7.2
执行 docker service create –replicas 6 –name myweb -p 80:80 nginx:latest 时
报 Error response from daemon: rpc error: code = AlreadyExists desc = name conflicts with an existing object: service myweb already exists
报错原因:项目名冲突
docker service ls 查看所有的服务

删除

再次运行
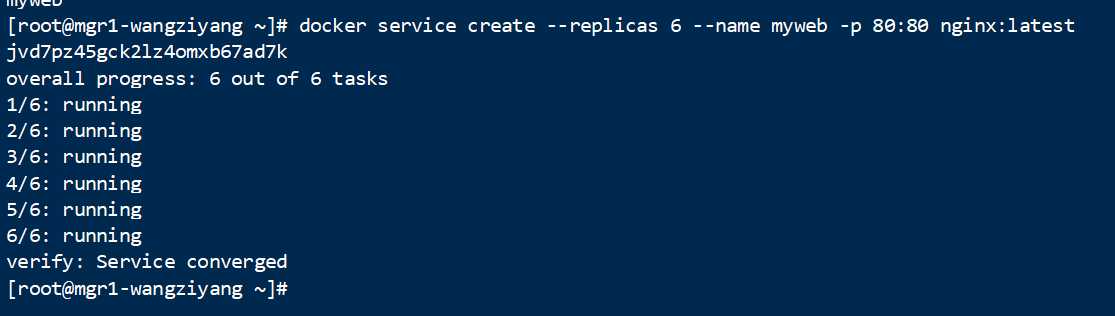
成功