主题Topic
通常,主题是指某些特定的相互关联的概念的特定标题或名称。 在Kafka中,主题一词是指用于存储和发布特定数据流的类别或通用名称。 基本上,Kafka中的主题类似于数据库中的表table,但不包含所有约束。 在Kafka中,我们可以根据需要创建n个主题。 它由其名称标识,这取决于用户的选择。 生产者将数据发布到主题,而消费者则通过订阅从主题中读取数据。
分区Partitions
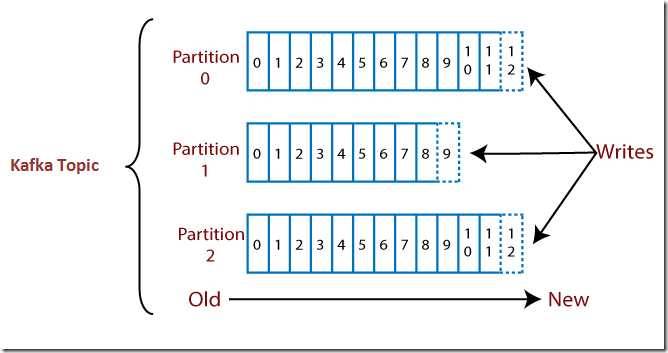
主题分为几个部分,这些部分称为主题的分区。 这些分区按顺序分开。 数据内容存储在主题内的分区中。 因此,在创建主题时,我们需要指定分区数(该数是任意的,以后可以更改)。 每条消息都以增量ID(称为偏移值)存储在分区中。 偏移值的顺序仅在分区内而不超出分区内得到保证。 分区的偏移量是无限的。
注意:一旦写入分区,数据将永远无法更改。 这是一成不变的。 偏移值始终保持递增状态,永远不会返回空白空间。 同样,数据仅在有限的时间内保留在分区中。
下面图解主题和分区:
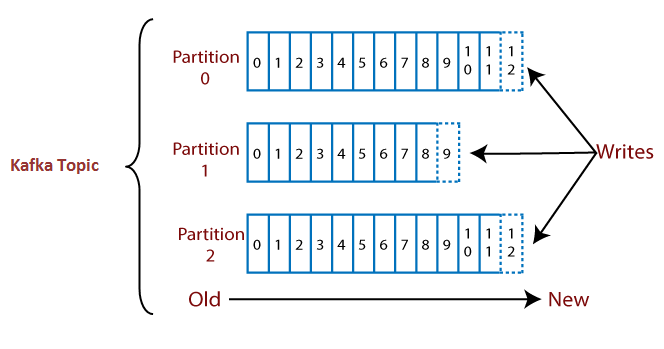
假设一个主题包含三个分区0,1和2。每个分区都有不同的偏移号。 数据分布在每个分区的每个偏移量中,分区0的偏移量1中的数据与分区1的偏移量1中的数据没有任何关系。 但是,分区0的偏移量1中的数据与分区0的偏移量2中包含的数据相互关联。
代理Brokers
Kafka群集由一台或多台称为代理或Kafka代理的服务器组成。 代理是一个包含多个主题及其多个分区的容器。 集群中的代理仅由整数ID标识。 Kafka代理也称为Bootstrap代理,因为与任何一个代理的连接都意味着与整个集群的连接。 尽管代理不包含全部数据,但是群集中的每个代理都知道所有其他代理,分区以及主题。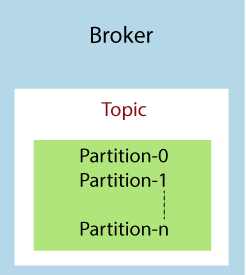
例子:代理和主题
假设一个由三个代理组成的Kafka集群,即Broker 1, Broker 2, and Broker 3。
每个代理都拥有一个主题,即带有三个分区0,1和2的Topic-x。请记住,所有分区都不仅仅属于一个代理,它总是分布在每个代理中(取决于数量)。 代理1和代理2包含另一个主题y,它具有两个分区0和1。因此,代理3不保存来自主题y的任何数据。 还可以得出结论,代理号和分区号之间不存在任何关系。