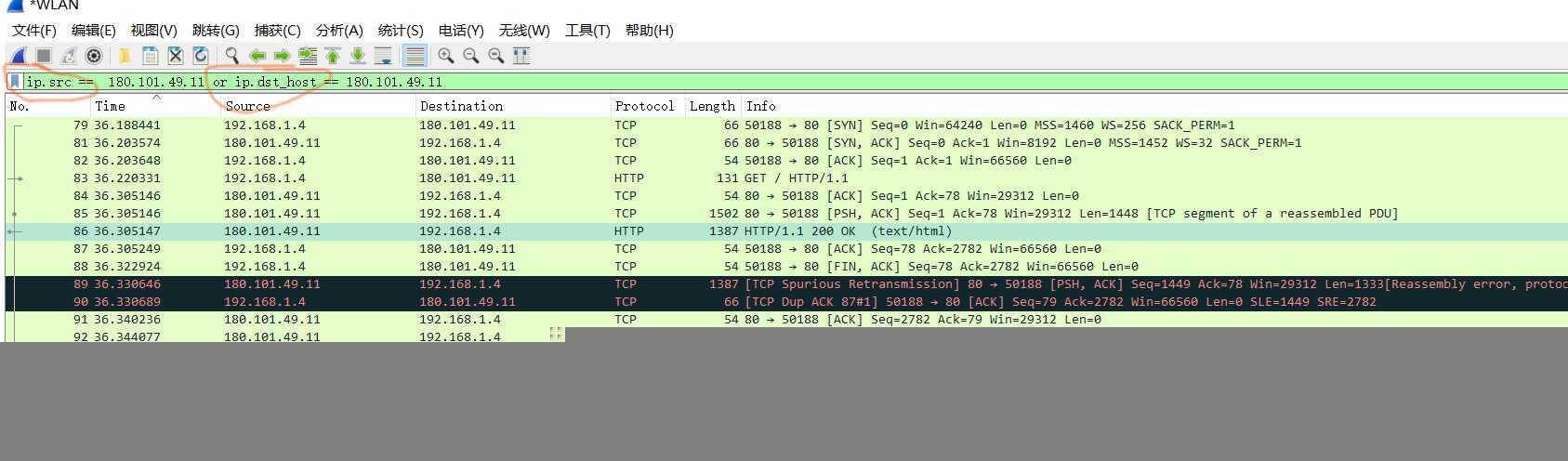
使用curl -v www.baidu.com发送一个请求
使用wareshark的过滤器表达式显示这个完整请求 TCP HTTP协议 , 其中192.168.1.4是本地ip
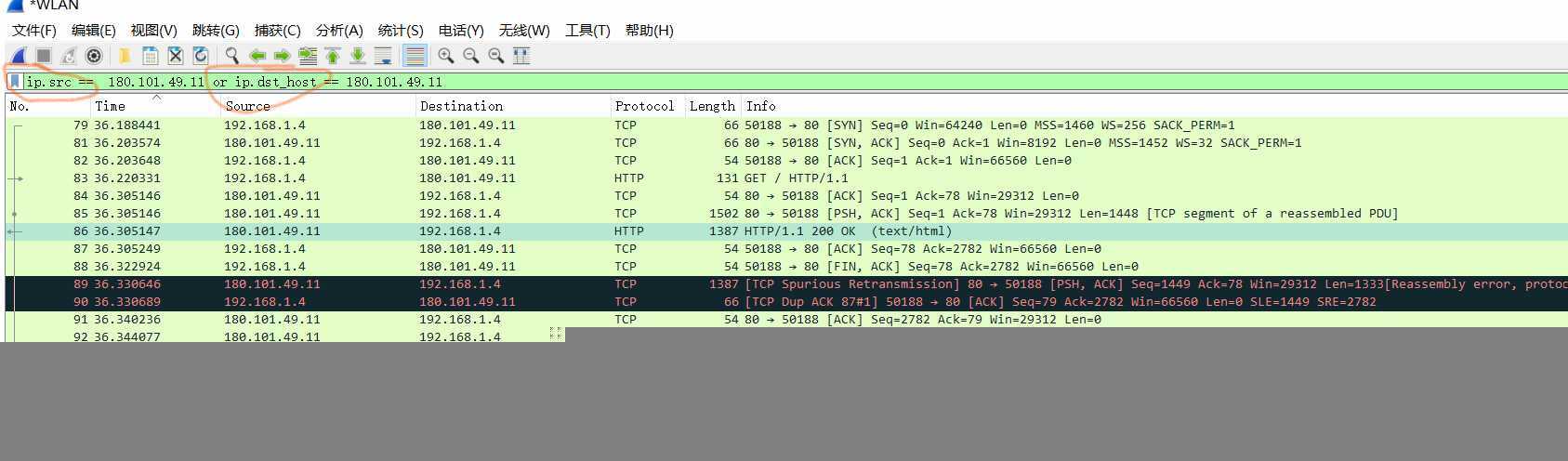
可以看到84 85两个tcp帧合成一个http报文86
89 服务器端发生了数据帧重传,90 客户端重复确认了一下
最后服务器端发送了RST断开连接
wareshark和fiddler charles对比
wareshark分析的是网络数据, 监听本地interface时要另外安装插件
fiddler是在本地java服务端口和客户端之间搭了一个代理服务器, 要求客户端的流量(设置http代理)先经过fiddler的监听端口,
而本地java服务端口和fiddler监听端口不能相同, 如果客户端不设置代理,fiddler就不能监听到本地服务的所有请求参数