
Deformable conv赋予了CNN位置变换的能力,与普通卷积的对比如下。可以看到,在每个特征点上,会产生一个偏移,变成
不规则的卷积(感觉本质上,就是让CNN自己去学习感受野)。

思想来源于STN(Spatial Transform Network),但它们有着巨大的差别:
STN得到的是全局(global)的变换,也就是说所得的的变换(旋转、缩放等)都是对整幅图片有效的,因而一幅图片只有一个变换。但许多图片是复杂的,
有多个目标,不同目标的变换方式不同,一个变换包打天下不成。因而出现了Recurrent STN,由递归产生不同的变换,作用在图中不同的目标。这种思想的效率不高,只能用于简单的情况。
Deform-conv则不同,它产生的是稠密的(dense)偏移,每一个输入特征点(Feature_map point)均会得到一个偏移
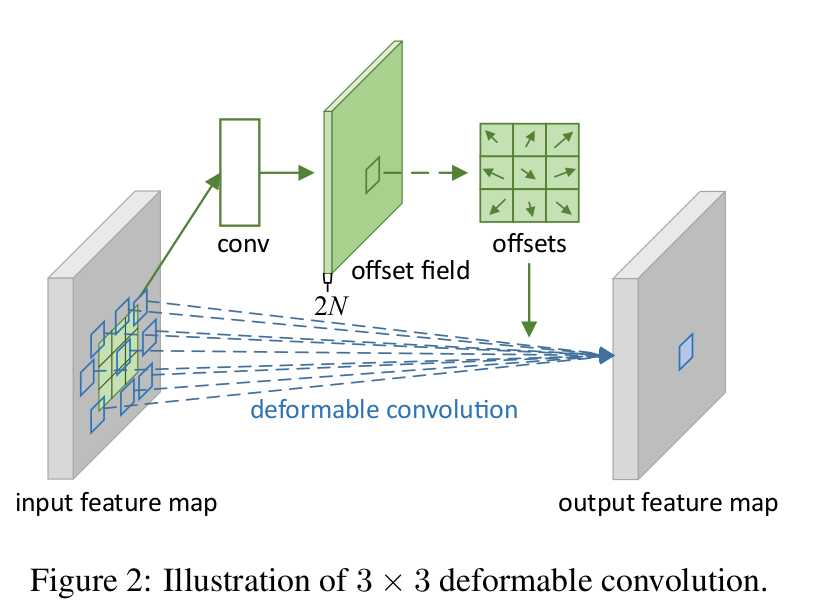
由图中conv得到的就是偏移(offset),根据偏移,将原本规则的特征区域映射为不规则区域,进一步,因为偏移可能为小数,通过使用根据双线性插值,来抽取特征点。
参考:https://blog.csdn.net/StreamRock/article/details/80921550