背景
背景说起来有点复杂,公司的项目旧平台已经弃用(相关人员都离职的七七八八),但是系统却还在运行(虽说是演示系统)。
在职人让找离职的,离职让找在职的,没办法,只好自己搞。
就平台跑在k8s集群上,其中一个服务作为大数据平台,数据存储在hbase数据库。
由于平台没有人运维,一直都有挂掉起不来的可能,之前存储了很多图片在里面,需要及早把图片拷贝出来。
看了一下历史文档,结合服务器信息,发现数据存储在hbase这个数据库中。既然是数据库,那么应该支持导出才对,但是发现其中存储的数据已经以tb计算了,我的电脑吃不消,于是考虑学习一下hbase,看是否有方法只导出部分数据。
先说结论:最终也没找到好方法,改为通过写代码导出了。。。
正文
关于hadoop和hbase
hbase是hadoop生态环境中的一环,hadoop以我目前的理解,是两个功能,大数据存储和大数据处理。
大数据存储基于hdfs(hadoop distributed filesystem),也就是存储在hdfs中。而hdfs有一些缺点,例如高延迟,不支持随机访问,于是在其之上,有了hbase数据库,优化了访问方式和速度。
而hbase属于NOSQL数据库,与传统数据库区别比较大,其实在hbase之上,还有hive、impala等将hbase数据库进行抽象成支持传统SQL的数据库。
我这里暂时还是聚焦于hbase本身。而且不涉及hadoop/hbase等的安装配置,以及命令行的使用,而是从概念的角度进行叙述。
hbase的特点
RDBMS可以被很直观的想象成为一张二维表格,每一行是一条数据,每一条数据有哪些数据项是指定好的,就是表的列。而一行中某一个或几个列又有可以被指定为列的Key,唯一标识这一行。
在网上可以看到的hbase相比于RDBMS的特点,hbase基于列,而非基于行。这句话个人觉得可能并不是那么准确,或者说不能很容易被理解。我想结合hbase的基本使用来说明,可能更容易理解
表创建
hbase也是由一张张表构成,而hbase的表也有所谓的schema,但是它并非像RDBMS那样定义column,而是定义column family`。
看一下hbase中如何创建一张表(通过hbase shell执行的命令,下同):
hbase(main):004:0> create ‘test‘,‘cf1‘,‘cf2‘
这里创建了一张很简单的表叫test,它包含两个column family,分别叫cf1, cf2,就这样了。
相比传统的RDBMS,可能突然会有很多问题:column family(以下简称cf)和传统的列有什么区别?每个cf存储什么类型的数据?不需要指定Key吗?
有一个问题时可以预先得知的了,hbase的概念可能接近于redis,都是以二进制数据存储,以后命令中,操作数据,包括指定表名、列名时,也都加了引号,代表字符串。
数据存储
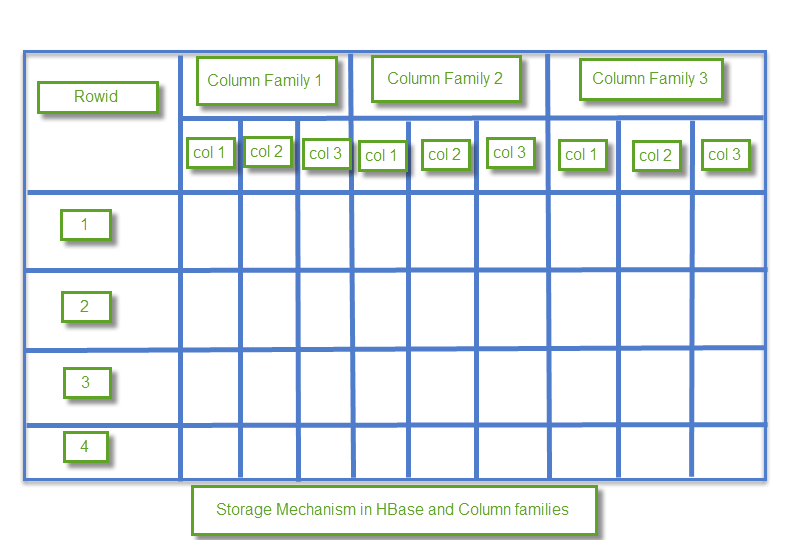
下面是来自这篇教程文章中,关于hbase表的一个概念图:
表中有一个一个的格子,每个格子代表了其中存储的一个数据项。与其说hbase基于列,可能也可以说hbase基于格子(cell)。hbase实际是通过键值对存储的,键可以认为就是格子的坐标,而值就是格子中存储的值。
格子的横坐标是row key,这个概念之前没有提到。格子的纵坐标是column family: column两个结合起来,其中column也是之前没提到的概念。
RDBMS中一行的Key是行中预定义好的某一列(或者某几列),而hbase中,row key是游离于表定义外的一个数据,是在数据插入时额外指定的一个参数。
同样,column(非column family)也是在插入时指定的,这里的column相当灵活,可以是已经存在的,可以是还不存在的,甚至可以不指定。
几个例子:
Example 1
hbase(main):007:0> put ‘test‘,‘r1‘,‘cf1:c1‘,‘data1‘
0 row(s) in 0.0600 seconds
hbase(main):008:0> scan ‘test‘
ROW COLUMN+CELL
r1 column=cf1:c1, timestamp=1570621985644, value=data1
1 row(s) in 0.0250 seconds
这里插入了一条数据,或者说一个键值对。插入的表是刚刚创建的表test,而row key是第二个参数r1。
注意第三个参数cf1:c1,:的前面代表column family是cf1,后面部分c1就是column了。创建表时,需要指定cf,而cf中具体有哪些列,插入时动态添加,只要指定添加的列属于哪个cf就行。
最后一个参数data1是插入的数据。
最后通过scan命令,查看刚刚插入的数据,该数据位于ROW r1、COLUMN cf1:c1,数值value是data1,还有一个参数timestamp后面介绍。
Example 2
再添加一条记录
hbase(main):009:0> put ‘test‘,‘r1‘,‘cf1:c1‘,‘data2‘
0 row(s) in 0.0290 seconds
hbase(main):010:0> scan ‘test‘
ROW COLUMN+CELL
r1 column=cf1:c1, timestamp=1570622432243, value=data2
1 row(s) in 0.0140 seconds
这里,我们仍然向r1, cf1:c1中添加数据,然后查询,发现只能查到新添加的数据data2,之前的data1看不到了。
SQL数据库中,添加数据时使用insert,而更改数据时,需要用update。而hbase在同一个行列代表的格子中存储数据,都是通过put指令来操作的。后加入的数据,会覆盖``先加入的数据。
不过这里的先、后、覆盖都要打上引号。
Example 3
还是接着上面的操作,这里增加一些选项进行查询
hbase(main):011:0> scan ‘test‘,{RAW=>true,VERSIONS=>2}
ROW COLUMN+CELL
r1 column=cf1:c1, timestamp=1570622432243, value=data2
r1 column=cf1:c1, timestamp=1570621985644, value=data1
1 row(s) in 0.0170 seconds
这次又能查询出来两个数据了?
其实数据并没有真的被覆盖,而是查询时,默认只查询出最后一个加入在这个坐标的数据。不过可以通过VERSION=>2,来设置查询历史最近的两个记录(这里记录和键值对都是指一个意思)。
而记录的远近,是通过记录插入时生成的timestamp来确定的,这个timestamp默认是数据写入hbase时根据服务器时间生成的,不过我们也可以在插入时自己指定:
hbase(main):013:0> put ‘test‘,‘r1‘,‘cf1:c1‘,‘data3‘,20
0 row(s) in 0.0220 seconds
hbase(main):014:0> scan ‘test‘
ROW COLUMN+CELL
r1 column=cf1:c1, timestamp=1570622432243, value=data2
1 row(s) in 0.0130 seconds
hbase(main):015:0> scan ‘test‘,{RAW=>true,VERSIONS=>3}
ROW COLUMN+CELL
r1 column=cf1:c1, timestamp=1570622432243, value=data2
r1 column=cf1:c1, timestamp=1570621985644, value=data1
r1 column=cf1:c1, timestamp=20, value=data3
1 row(s) in 0.0370 seconds
第一条命令,最后增加了一个数字参数20,就代表了我们手动指定timestamp,而不是使用系统默认。
于是接下来一条普通的scan命令,不能查询到我们新插入的data3了。
但是如果指定VERSIONS=>3查询最近的3条,那么就可以看到新插入的数据可以被查出来,只是timestamp太小,放在了最后。
Example 4
hbase(main):016:0> put ‘test‘,‘r2‘,‘cf2‘,‘data4‘
0 row(s) in 0.0340 seconds
hbase(main):017:0> scan ‘test‘
ROW COLUMN+CELL
r1 column=cf1:c1, timestamp=1570622432243, value=data2
r2 column=cf2:, timestamp=1570623180768, value=data4
2 row(s) in 0.0200 seconds
这里终于使用了不同的row key=>r2了,而且这次也没有指定column,可以看到scan的结果,新添加的数据,默认的column为空,这就是系统默认的column。
数据读取
hbase我没有看到比较方便的、类似SQL的查询语句,简单的通过row key来查询。这里之前预先插入了以下数据
hbase(main):020:0> scan ‘test‘
ROW COLUMN+CELL
r1 column=cf1:, timestamp=1570623351436, value=data5
r1 column=cf1:c1, timestamp=1570622432243, value=data2
r2 column=cf2:, timestamp=1570623180768, value=data4
r2 column=cf2:c2, timestamp=1570623364613, value=data6
2 row(s) in 0.0220 seconds
hbase(main):021:0> get ‘test‘,‘r2‘
COLUMN CELL
cf2: timestamp=1570623180768, value=data4
cf2:c2 timestamp=1570623364613, value=data6
1 row(s) in 0.0210 seconds
首先是通过scan扫描全表看看有哪些数据。然后通过get,只查询r2这一个row key所包含的数据。
这里也能看出hbase的键值对存储特性,每行数据显示的并非一行(一个row key对应的数据),而是row key结合column对应的数据。
虽说如此,但是查询的时候,似乎不能不指定row key,而只指定column,这样来说这也不像传统意义的坐标,因为横坐标row key和纵坐标column地位并非对等的。。。