1.概述
GBDT基于GB算法。GB算法的主要思想是,每次建立模型是在之前建立模型损失函数的梯度下降方向。损失函数是评价模型性能(一般为拟合程度+正则项),认为损失函数越小,性能越好。而让损失函数持续下降,就能使得模型不断调整提升性能,其最好的方法就是使损失函数沿着梯度方向下降。GBDT再此基础上,基于负梯度(当损失函数为均方误差的时候,可以看作是残差)做学习。
2.原理
类似于随机森林回归,随机森林使用的bagging,gdbt使用的是boosting方式,
通过不断迭代真实值与预测值的残差来产生新的回归树,
公式:
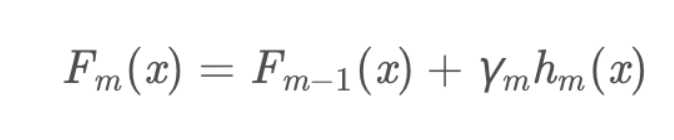
vm表示权重,这里是固定超参数,预测时只要做反运算即可,公式:
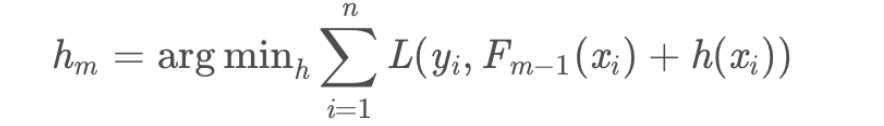
过程:
(1).对于样本{X,Y},首先生成截距b(可以是Y均值),对所有样本Y0=Y-b
(2).以Y0为预测值生成回归树t0,Y1 = Y0 – learningRate*tree0.predict(X),以Y1为预测值生成下一棵树,得出以下迭代公式:
Yi+1 = Yi – learningRate*treei.predict(X)
(3).重复步骤二,直至树的数目足够多为止