参考《centos7 cannot find a valid baseurl for repo》
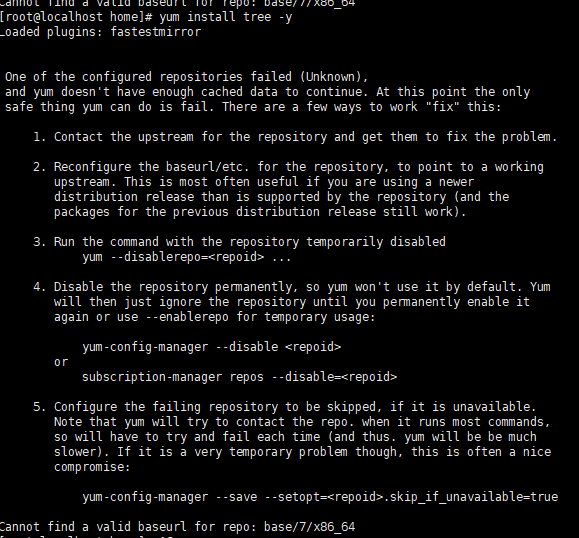
出现这个问题是因为yum在安装包的过程中,虽然已经联网,但是没法解析远程包管理库对应的域名,所以我们只需要在网络配置中添加上DNS对应的ip地址即可。
操作
1.打开网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-eth0
2.在文件末尾追加DNS
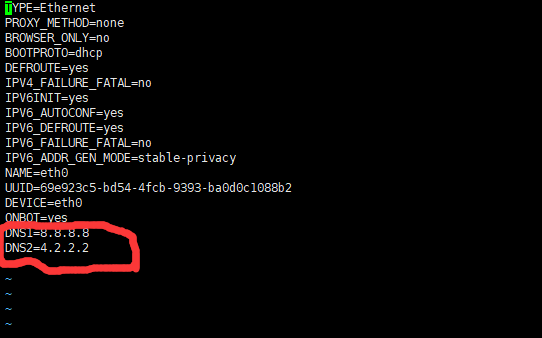
DNS1=8.8.8.8
DNS2=4.2.2.2
esc退出编辑模式,命令”:wq”保存并退出
3.重启网络

ifup eth0
4.成功!
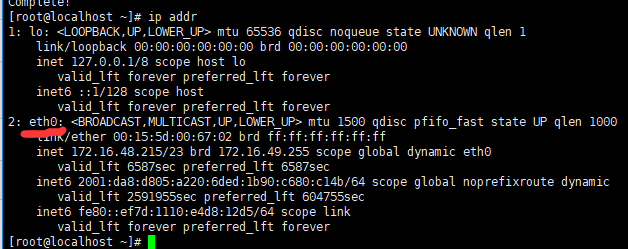
注意:我的网卡是eth0,你可能不是,填写你的网卡名字就行,命令ip addr