一、Flume是什么
Flume是一个数据,日志收集的一个组件,可以用于对程序,nginx等日志的收集,而且非常简单,省时的做完收集的工作。Flume是一个分布式、可靠、和高可用的海量日志采集聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集日志,同时Flume对日志做简单的处理。
Flume作为一个非常受欢迎的日志收集工具,有如下几个特点:
1. flume的可靠性
flume的某个节点出现故障时,数据不会丢失。flume提供了三种级别的可靠保障,级别从强到弱分别是
- end-to-end,收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送
- Store on failure 这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送
- Besteffort 数据发送到接收方后,不会进行确认
2. flume的可恢复性
将数据持久化到磁盘不会丢失,因为存储到了文件中,可以后续重新恢复。
二、Flume能够做什么
1.作为日志收集的工具,其目的用于日志的收集。web程序的日志收集和nginx写入程序的日志收集的操作:我接触到的日志收集,web程序的日志会在打印的时候被拦截,然后输入到kafka中,但是也有一部分的操作就是将日志直接打印到文件中,然后统一传入到ftp服务,在有程序统一处理。nginx日志分析也是日志打印到一个文件中,后续将其放入到统一位置处理。消息中间件都有日志收集的jar包,例如rocketmq的rocketmq-logappender包,kafka中有类可以直接调用。
kafka是分布式消息中间件,自带存储,提供push和pull存取数据功能,有Replication功能,能够实现高容错性,kafka收集日志,kafka有一个更小的生产消费者生态系统,但是整个社区对日志收集支持不太友好。kafka是一个消息中间件,多处理不同系统之间的数据生成 / 消费的速率不同。
flume专门设计成为日志收集的工具,封装了非常多的接口可供使用,使用简单,flume的agent(数据采集器),collector(数据简单处理和写入),storage(存储器)三部分,每一个都可以定制。并提供了简单的数据处理的能力。
使用建议:
1.如果有很多下游的Consumer,用kafka,而需简要存储大Hadoop,hive时,用flume
2.kafka做为一个做为一个日志缓存系统更合适,flume数据采集更优秀,在考虑场景是,需要给hadoop存储数据时,可以使用kafka+flume模式,如果有多个数据源,可以使用flume+kafka的内容
3. Kafka 是一个通用型系统。你可以有许多的生产者和消费者分享多个主题。相反地,Flume 被设计成特定用途的工作,特定地向 HDFS 和 HBase 发送出去。Flume 为了更好地为 HDFS 服务而做了特定的优化,并且与 Hadoop 的安全体系整合在了一起。基于这样的结论,Hadoop 开发商 Cloudera 推荐如果数据需要被多个应用程序消费的话,推荐使用 Kafka,如果数据只是面向 Hadoop 的,可以使用 Flume。
4. Flume 拥有许多配置的来源 (sources) 和存储池 (sinks)。然后,Kafka 拥有的是非常小的生产者和消费者环境体系,Kafka 社区并不是非常支持这样。如果你的数据来源已经确定,不需要额外的编码,那你可以使用 Flume 提供的 sources 和 sinks,反之,如果你需要准备自己的生产者和消费者,那你需要使用 Kafka。
5. Flume 可以在拦截器里面实时处理数据。这个特性对于过滤数据非常有用。Kafka 需要一个外部系统帮助处理数据。
6. 无论是 Kafka 或是 Flume,两个系统都可以保证不丢失数据。然后,Flume 不会复制事件。相应地,即使我们正在使用一个可以信赖的文件通道,如果 Flume agent 所在的这个节点宕机了,你会失去所有的事件访问能力直到你修复这个受损的节点。使用 Kafka 的管道特性不会有这样的问题。
7. lume 和 Kafka 可以一起工作的。如果你需要把流式数据从 Kafka 转移到 Hadoop,可以使用 Flume 代理 (agent),将 kafka 当作一个来源 (source),这样可以从 Kafka 读取数据到 Hadoop。你不需要去开发自己的消费者,你可以使用 Flume 与 Hadoop、HBase 相结合的特性,使用 Cloudera Manager 平台监控消费者,并且通过增加过滤器的方式处理数据。
Flume的核心
1.核心概念
- Client:client生成数据,运行在一个独立的线程
- Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
- Flow: Event从源点到达目的点的迁移的抽象。
- Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。)
- Source: 数据收集组件。(source从Client收集数据,传递给Channel)
- Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
- Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
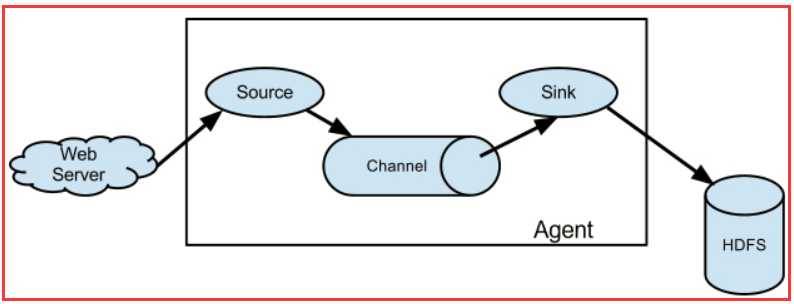
2. Agent详解
Flume运行核心是Agent,一个Agent就是一个JVM,它是一个完整的数据收集工具。Agent包含组件Source、Channel、Sink,通过这些组件 Event 可以从一个地方流向另一个地方,如下图所示。
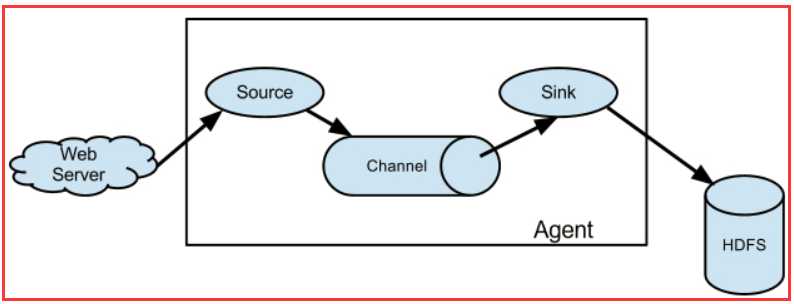
- webServer产生日志的源
- Source收集日志工具,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。
- Channel管道,是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。介绍两个较为常用的Channel, MemoryChannel和FileChannel,推荐使用FileChannel。
- Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
四、Flume的日志收集
一个简单的例子,nginx产生的日志,flume收集之后,放置到hadoop中,在服务器中部署nginx,flume,hadoop
1.nginx在配置中,需要打开日志输出,并标识出日志输出的路径.
http {
# 配置日志格式
log_format lf ‘$remote_addr $msec $http_host
server { listen 80; server_name localhost; location ~*\.(html|js|css|jpg|jpeg|gif|png|swf|ico|json|apk)$ {
# 日志输出路径 access_log /opt/nginx/log/access.log lf; root html; #root /usr/local/extra/nginx-1.9.6/html/; #root /usr/local/extra/nginx-1.9.6/html2/; } }
flume的配置:flume-conf.properties
# 配置Agent
agent.sources = r1 agent.sinks = k1 agent.channels = c1 # 配置Source agent.sources.r1.type = exec agent.sources.r1.channels = c1 agent.sources.r1.deserializer.outputCharset = UTF-8 # 配置需要监控的日志输出目录 agent.sources.r1.command = tail -f /usr/local/nginx/log/access.log # 配置Sink agent.sinks.k1.type = hdfs agent.sinks.k1.channel = c1 agent.sinks.k1.hdfs.useLocalTimeStamp = true agent.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/events/%Y-%m agent.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H agent.sinks.k1.hdfs.fileSuffix = .log agent.sinks.k1.hdfs.minBlockReplicas = 1 agent.sinks.k1.hdfs.fileType = DataStream agent.sinks.k1.hdfs.writeFormat = Text agent.sinks.k1.hdfs.rollInterval = 86400 agent.sinks.k1.hdfs.rollSize = 1000000 agent.sinks.k1.hdfs.rollCount = 10000 agent.sinks.k1.hdfs.idleTimeout = 0 # 配置Channel agent.channels.c1.type = memory agent.channels.c1.capacity = 1000 agent.channels.c1.transactionCapacity = 100 # 将三者连接 agent.sources.r1.channel = c1 agent.sinks.k1.channel = c1
这些配置之后,启动时会出现错误,原因是,需要一些jar包,flume下的lib是没有这些包,需要如下包(这些包从hadoop中复制过来):
{HADOOP_HOME}/share/hadoop/common/lib/commons-configuration2-2.1.1.jar
{HADOOP_HOME}/share/hadoop/common/lib/hadoop-auth-3.1.1.jar {HADOOP_HOME}/share/hadoop/common/hadoop-common-3.1.1.jar {HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-3.1.1.jar {HADOOP_HOME}/share/hadoop/common/lib/woodstox-core-5.2.0.jar {HADOOP_HOME}/share/hadoop/common/lib/ stax2-api-3.1.4.jar {HADOOP_HOME}/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar
然后运行如下命令:
bin/flume-ng agent --conf conf/ --name agent --conf-file conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
在访问ip:80时,服务器日志将写入到hadoop的flume/event/目录下