当你在浏览器地址栏敲入“http://www.cnblogs.com/”,然后猛按回车,呈现在你面前的,将是博客园的首页了(这真是废话,你会认为这是理所当然的)。作为一个开发者,尤其是web开发人员,我想你有必要去了解这一系列的处理流程,在这期间,浏览器和服务器到底是如何打交道的?服务器又是如何处理的?浏览器又是如何将网页显示给用户的呢?……
疑惑和细节真是太多了。坦白讲,要想彻彻底底的弄清楚以上每个疑惑和处理细节,至少需要十本书的厚度,所谓“底层无极限”嘛,而且不同的web服务 器和服务器端编程语言的实现和处理流程不尽相同(但本质都是相通的)。本文中,我将根据http协议的有关知识,跟大家讲解一些web开发的本质。不管你 是从事.NET,还是J2EE或者php开发等等,都离不开这些本质。希望你读完本文,能有新的收获和见解。由于本人水平和经验有限,难免有误,望读者见 谅。
何为http协议(Hypertext Transfer Protocol,超文本传输协议)?
所谓协议,就是指双方遵循的规范。http协议,就是浏览器和服务器之间进行“沟通”的一种规范。我们在看空间,刷微博…都是在使用http协议,当然,远远不止这些应用。
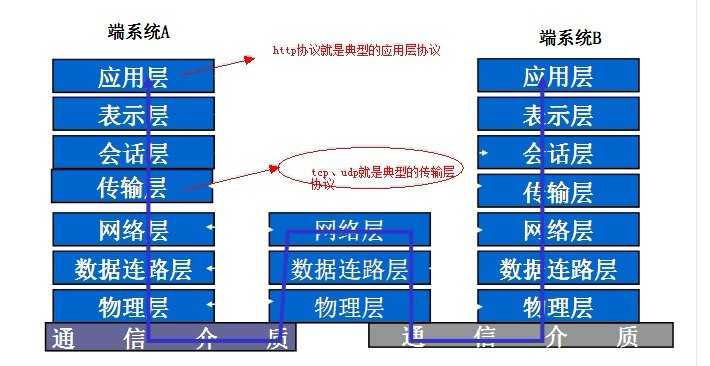
笔者一直听说http是属于“应用层的协议”,而且是基于TCP/IP协议的。这个不难理解,如果你上大学时候学过“计算机网络”的课程,就一定知 道OSI七层参考协议(我当时是死记硬背的)。如果你接触过socket网络编程,就应该明白TCP和UDP这两种使用广泛的通信协议(建立连接、三次握 手等等,当然,这不是本文讨论的重点)。如图:
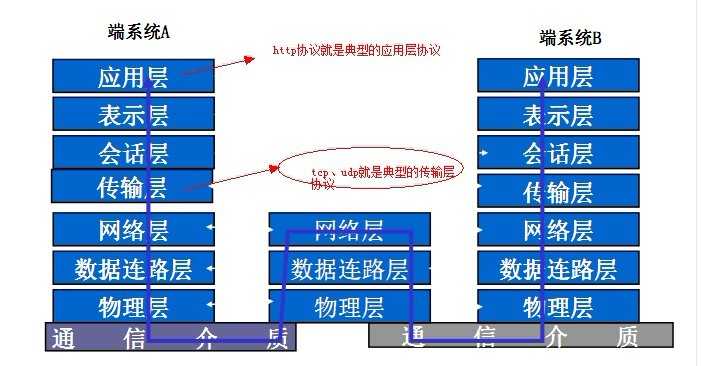
既然TCP/UDP是广泛使用的网络通信协议,那为啥有多出个http协议来呢?
笔者曾自己动手写过一个简单的web服务器处理软件,根据我的推断(不一定准确)。UDP协议具有不可靠性和不安全性,显然这很难满足web应用的需要。
而TCP协议是基于连接和三次握手的,虽然具有可靠性,但人具有一定的缺陷。但试想一下,普通的C/S架构软件,顶多上千个Client同时连接,而B/S架构的网站,十万人同时在线也是很平常的事儿。如果十万个客户端和服务器一直保持连接状态,那服务器如何满足承载呢?
这就衍生出了http协议。基于TCP的可靠性连接。通俗点说,就是在请求之后,服务器端立即关闭连接、释放资源。这样既保证了资源可用,也吸取了TCP的可靠性的优点。
正因为这点,所以大家通常说http协议是“无状态”的,也就是“服务器不知道你客户端干了啥”,其实很大程度上是基于性能考虑的。以至于后来有了session之类的玩意。
实战准备工作:
在监视网络方面,windows平台上有一款叫做Sniffer的优秀软件,这也是很多“黑客”经常使用的嗅探工具。 在研究http协议时,推荐大家使用一款
叫作httpwatch的工具。(遗憾的是,该工具是收费的。该咋办就咋办,你懂的)。安装完成后,可以在IE浏览器的tools中直接打开(目前也支持firefox)。如图所示:
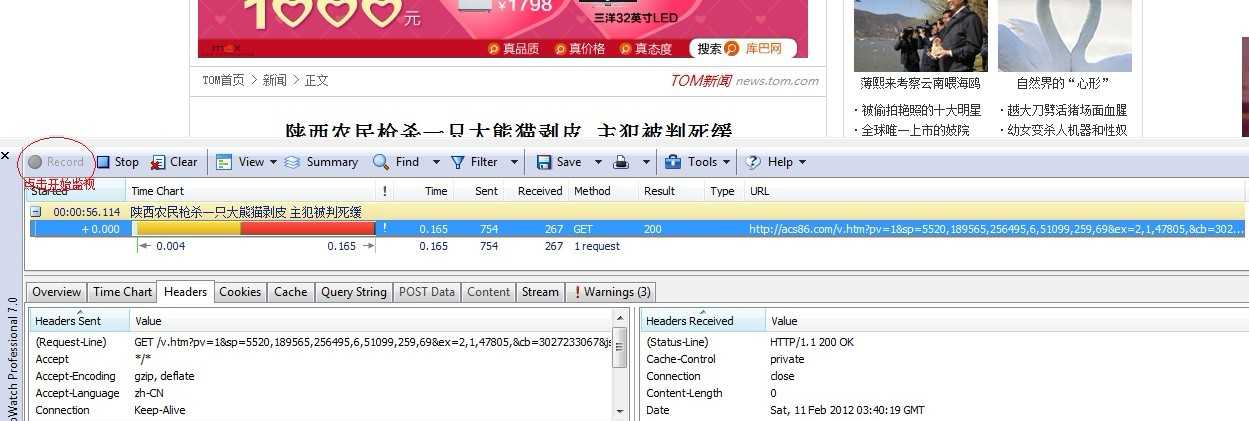
点击Record,就可以开始监视并记录http消息了。stop、Clear等等按钮的功能,这里就不一一介绍了。拿实例来说话,下面就是我记录访问main.aspx页面的时候记录的,能够清晰的看到http报文消息的详细信息,如图:

学习http协议,主要需要了解http的请求和响应(当然,还有get、post等请求方式,状态码、URI、MIME等)
首先看看http请求消息(就是浏览器丢给服务器的):
一个http请求代表客户端浏览器向服务器发送的数据。一个完整的http请求消息,包含一个请求行,若干个消息头(请求头),换行,实体内容
请求行:描述客户端的请求方式、请求资源的名称、http协议的版本号。 例如: GET/BOOK/JAVA.HTML HTTP/1.1
请求头(消息头)包含(客户机请求的服务器主机名,客户机的环境信息等):
Accept:用于告诉服务器,客户机支持的数据类型 (例如:Accept:text/html,image/*)
Accept-Charset:用于告诉服务器,客户机采用的编码格式
Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式
Accept-Language:客户机语言环境
Host:客户机通过这个服务器,想访问的主机名
If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间
Referer:客户机通过这个头告诉服务器,它(客户端)是从哪个资源来访问服务器的(防盗链)
User-Agent:客户机通过这个头告诉服务器,客户机的软件环境(操作系统,浏览器版本等)
Cookie:客户机通过这个头,将Coockie信息带给服务器
Connection:告诉服务器,请求完成后,是否保持连接
Date:告诉服务器,当前请求的时间
(换行)
实体内容:
就是指浏览器端通过http协议发送给服务器的实体数据。例如:name=dylan&id=110
(get请求时,通过url传给服务器的值。post请求时,通过表单发送给服务器的值)
再看看HTTP响应消息(服务器返回给浏览器的):
一个http响应代表服务器端向客户端回送的数据,它包括:
一个状态行,若干个消息头,以及实体内容
响应头(消息头)包含:
Location:这个头配合302状态吗,用于告诉客户端找谁
Server:服务器通过这个头,告诉浏览器服务器的类型
Content-Encoding:告诉浏览器,服务器的数据压缩格式
Content-Length:告诉浏览器,回送数据的长度
Content-Type:告诉浏览器,回送数据的类型
Last-Modified:告诉浏览器当前资源缓存时间
Refresh:告诉浏览器,隔多长时间刷新
Content-Disposition:告诉浏览器以下载的方式打开数据。例如: context.Response.AddHeader(“Content-Disposition”,”attachment:filename=aa.jpg”); context.Response.WriteFile(“aa.jpg”);
Transfer-Encoding:告诉浏览器,传送数据的编码格式
ETag:缓存相关的头(可以做到实时更新)
Expries:告诉浏览器回送的资源缓存多长时间。如果是-1或者0,表示不缓存
Cache-Control:控制浏览器不要缓存数据 no-cache
Pragma:控制浏览器不要缓存数据 no-cache
Connection:响应完成后,是否断开连接。 close/Keep-Alive
Date:告诉浏览器,服务器响应时间
状态行: 例如: HTTP/1.1 200 OK (协议的版本号是1.1 响应状态码为200 响应结果为 OK)
实体内容(实体头):响应包含浏览器能够解析的静态内容,例如:html,纯文本,图片等等信息
理解了以上的http请求消息和响应消息,相信你对于http协议已经理解得足够深刻了。关于http协议的更多具体细节,可以参照http RFC文档。
大致步骤就是:浏览器先向服务器发送请求,服务器接收到请求后,做相应的处理,然后封装好响应报文,再回送给浏览器。浏览器拿到响应报文后,再通过 浏览器引擎去渲染网页,解析DOM树,javascript引擎解析并执行脚本操作,插件去干插件该干的事儿…关于浏览器渲染、解析的原理,可以参考http://kb.cnblogs.com/page/129756/
说白了,所谓web的本质,无非是:请求/处理/响应 ,任何的web服务器,任何的服务端编程语言,都没法脱离这个本质。 而浏览器端解析html、图片等静态内容,呈现给用户,脚本引擎执行脚本代码,完成脚本代码要做的事儿(例如dom操作,css属性更改,发送ajax请 求等等)。