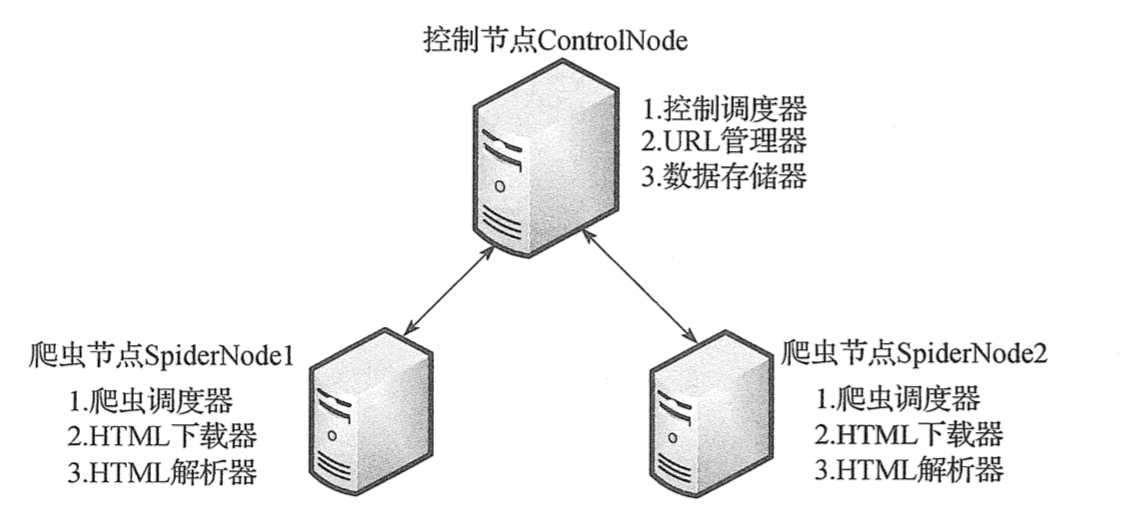
一、简单分布式爬虫架构
本次分布式爬虫采用主从模式,主从模式是指一台主机作为控制节点,负责管理所有运行网络爬虫的主机,爬虫只需要从控制节点那里接收任务,并把新生成任务提交给控制节点就可以了,在这个过程中不必与其他爬虫通信,这种方式实现简单、利于管理。而控制节点则需要与所有爬虫进行通信,因此可以看到主从模式是有缺陷的,控制节点会成为整个系统的瓶颈,容易导致整个分布式网络爬虫系统性能下降。
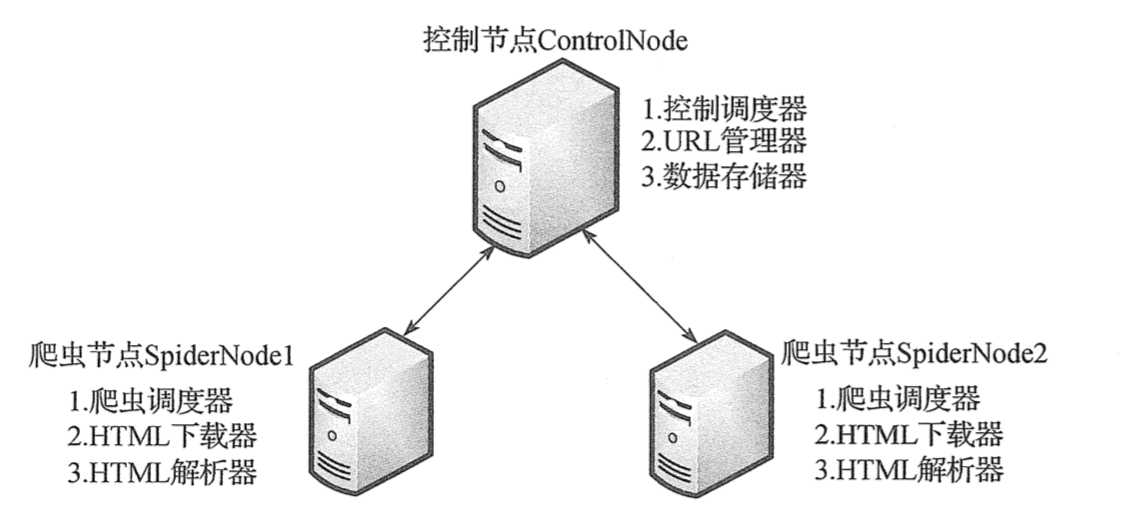
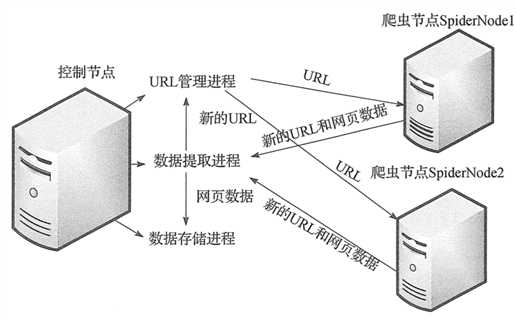
二、控制节点
控制节点主要分为 URL 管理器、数据存储器和被控制调度器。控制调度器通过三个进程来协调 URL 管理器和数据存储器的工作:一个是 URL 管理进程,负责 URL 的管理和将 URL 传递给爬虫节点;一个是数据提取进程,负责读取爬虫节点返回的数据,将返回数据中的 URL 交给 URL 管理进程,将标题和摘要等数据交给数据存储进程;最后一个是数据存储进程,负责将数据提取进程中提交的数据进行本地存储。
三、URL 管理器
对之前的 url 管理器进行优化,采用 set 内存去重的方式,如果直接存储大量的 URL 链接,尤其是 URL 链接很长的时候,很容易造成内存溢出,所以我们将爬取过的 URL 进行 MD5 处理。字符串经过 MD5 处理后的信息摘要长度为128位,将生成的 MD5 摘要存储到 set 后,可以减少好几倍的内存消耗,不过 Python 中的 MD5 算法生成的是256位,取中间的128位即可。我们同时添加了 save_progress 和 load_progress 方法进行序列化的操作,将未爬取 URL 集合和已爬取的 URL 集合序列化到本地,保存当前的进度,以便下次恢复状态。
四、代码如下
1 import pickle 2 import hashlib 3 4 5 class UrlManager: 6 def __init__(self): 7 self.new_urls = self.load_progress(‘new_urls.txt‘) # 未爬取 url 集合 8 self.old_urls = self.load_progress(‘old_urls.txt‘) # 已爬取 url 集合 9 10 def has_new_url(self): 11 """ 12 判断是否有未爬取的 url 13 :return: bool 14 """ 15 return self.new_urls_size() != 0 16 17 def get_new_url(self): 18 """ 19 返回一个未爬取的 url 20 :return: str 21 """ 22 new_url = self.new_urls.pop() 23 m = hashlib.md5() 24 m.update(new_url.encode(‘utf-8‘)) 25 self.old_urls.add(m.hexdigest()[8:-8]) 26 27 return new_url 28 29 def add_new_url(self, url): 30 """ 31 添加一个新的 url 32 :param url: 单个 url 33 :return: None 34 """ 35 if url is None: 36 return None 37 m = hashlib.md5() 38 m.update(url.encode(‘utf-8‘)) 39 url_md5 = m.hexdigest()[8:-8] 40 if (url not in self.new_urls) and (url_md5 not in self.old_urls): 41 self.new_urls.add(url) 42 43 def add_new_urls(self, urls): 44 """ 45 添加多个新的url 46 :param urls: 多个 url 47 :return: None 48 """ 49 if urls is None: 50 return None 51 for url in urls: 52 self.add_new_url(url) 53 54 def new_urls_size(self): 55 """ 56 返回未爬过的 url 集合的大小 57 :return: int 58 """ 59 return len(self.new_urls) 60 61 def old_urls_size(self): 62 """ 63 返回已爬过的 url 集合的大小 64 :return: int 65 """ 66 return len(self.old_urls) 67 68 def save_progress(self, path, data): 69 """ 70 保存进度 71 :param path: 路径 72 :return: None 73 """ 74 with open(path, ‘wb‘) as file: 75 pickle.dump(data, file) 76 77 def load_progress(self, path): 78 """ 79 从本地文件加载进度 80 :param path: 路径 81 :return: set 82 """ 83 print(‘[+] 从文件加载进度{}‘.format(path)) 84 try: 85 with open(path, ‘rb‘) as file: 86 return pickle.load(file) 87 except: 88 print(‘[!] 无进度文件‘) 89 90 return set()