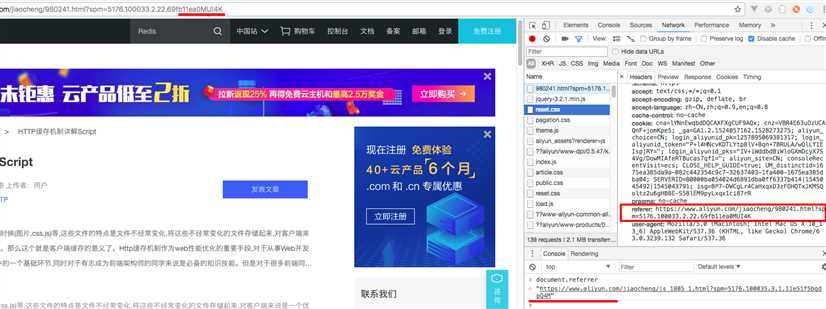
1. document.referrer 与 Request Headers的refere
Request Headers上referer当前页面的地址栏。
而当前的页面的上一个页面 document.referrer,并不一定是当前页面的url
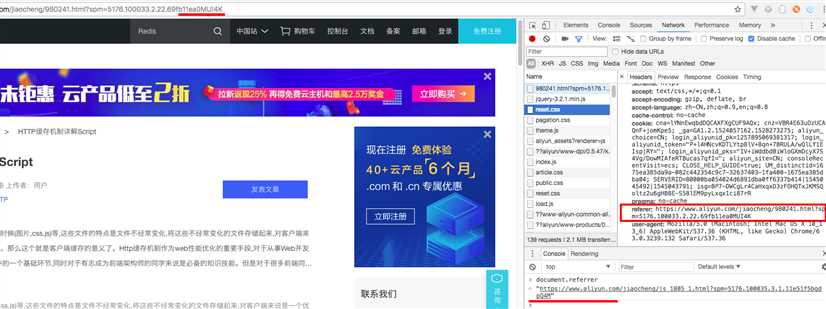
2.浏览器缓存
关于Pragma:no-cache,跟Cache-Control: no-cache相同。
Pragma: no-cache兼容http 1.0 ,Cache-Control: no-cache是http 1.1提供的。
因此,Pragma: no-cache可以应用到http 1.0 和http 1.1,而Cache-Control: no-cache只能应用于http 1.1.
浏览器缓存主要有两类:缓存协商和彻底缓存,也有称之为协商缓存和强缓存。
1.强缓存:不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的network选项中可以看到该请求返回200的状态码;
2.协商缓存:向服务器发送请求,服务器会根据这个请求的request header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的response header通知浏览器从缓存中读取资源;
两者的共同点是,都是从客户端缓存中读取资源;区别是强缓存不会发请求,协商缓存会发请求。
强制缓存
Expires:response header里的过期时间,浏览器再次加载资源时,如果在这个过期时间内,则命中强缓存。
Cache-Control:当值设为max-age=300时,则代表在这个请求正确返回时间(浏览器也会记录下来)的5分钟内再次加载资源,就会命中强缓存。
cache-control除了该字段外,还有下面几个比较常用的设置值:
-no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
-no-store:直接禁止浏览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
-public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
-private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
Cache-Control仅指定了max-age,所以默认为private,缓存时间为31536000秒(365天)也就是说,在365天内再次请求这条数据,都会直接获取缓存数据库中的数据,直接使用。
没懂的话,我们换通俗一点的话来说一遍。当客户端第一次访问资源的时候,服务端在返回资源内容的同时也返回了Expires: Sun, 16 Oct 2016 05:43:02 GMT。
服务端告诉浏览器: 你Y的先把这个文件给我缓存起来,在这个过期时间之前,这个文件都不会变化了,你下次需要这个文件的时候,你就不要过来找我要了,你就去缓存中拿就好了,又快又好。
浏览器回答说:诺。
于是在第二次html页面中又要访问这个资源的时候,并且访问的日期在Sun, 16 Oct 2016 05:43:02 GMT之前,浏览器就不去服务器那边获取文件了,自己从缓存中自食其力了。
但是呢,浏览器毕竟是在客户端的,客户端的时间可是不准确的,用户可以随着自己的喜好修改自己机器的时间,比如我把我机器的时间调成Sun, 16 Oct 2016 05:43:03 GMT,那么呢?我的浏览器就不会再使用缓存了,而每次都去服务器获取文件。于是,服务器怒了:给你个绝对时间,你由于环境被修改没法判断过期,那么我就给你相对时间吧。于是就返回了Cache-Control: max-age:600,浏览器你给我缓存个10分钟去。于是浏览器只有乖乖的缓存10分钟了。
但是问题又来了,如果有的服务器同时设置了Expires和Cache-Control怎么办呢?(不是闲的没事干,而是由于Cache-Controll是HTTP1.1中才有的)那么就是根据更先进的设置Cache-Control来为标准。
好了,现在有个问题,我有个文件可能时不时会更新,服务端非常希望客户端能时不时过来问一下这个文件是否过期,如果没有过期,服务端不返回数据给你,只告诉浏览器你的缓存还没有过期(304)。然后浏览器使用自己存储的缓存来做显示。这个就叫做条件请求。
协商缓存
Last-Modify/If-Modify-Since:浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间;当浏览器再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存
Etag:web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。
If-None-Match:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Etage声明,则再次向web服务器请求时带上头If-None-Match (Etag的值)。web服务器收到请求后发现有头If-None-Match 则与被请求资源的相应校验串进行比对,决定是否命中协商缓存;
ETag和Last-Modified的作用和用法,他们的区别:
1.Etag要优于Last-Modified。Last-Modified的时间单位是秒,如果某个文件在1秒内改变了多次,那么他们的Last-Modified其实并没有体现出来修改,但是Etag每次都会改变确保了精度;
2.在性能上,Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值;
3.在优先级上,服务器校验优先考虑Etag。
浏览器缓存过程
1.浏览器第一次加载资源,服务器返回200,浏览器将资源文件从服务器上请求下载下来,并把response header及该请求的返回时间一并缓存;
2.下一次加载资源时,先比较当前时间和上一次返回200时的时间差,如果没有超过cache-control设置的max-age,则没有过期,命中强缓存,不发请求直接从本地缓存读取该文件(如果浏览器不支持HTTP1.1,则用expires判断是否过期);如果时间过期,则向服务器发送header带有If-None-Match和If-Modified-Since的请求
3.服务器收到请求后,优先根据Etag的值判断被请求的文件有没有做修改,Etag值一致则没有修改,命中协商缓存,返回304;如果不一致则有改动,直接返回新的资源文件带上新的Etag值并返回200;;
4.如果服务器收到的请求没有Etag值,则将If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回304;不一致则返回新的last-modified和文件并返回200;
浏览器中写地址,回车
F5
Ctrl+F5
假设对一个资源:
浏览器第一次访问,获取资源内容和cache-control: max-age:600,Last_Modify: Wed, 10 Aug 2013 15:32:18 GMT于是浏览器把资源文件放到缓存中,并且决定下次使用的时候直接去缓存中取了。
浏览器url回车
浏览器发现缓存中有这个文件了,好了,就不发送任何请求了,直接去缓存中获取展现。(最快)
下面我按下了F5刷新
F5就是告诉浏览器,别偷懒,好歹去服务器看看这个文件是否有过期了。于是浏览器就胆胆襟襟的发送一个请求带上If-Modify-since:Wed, 10 Aug 2013 15:32:18 GMT
然后服务器发现:诶,这个文件我在这个时间后还没修改过,不需要给你任何信息了,返回304就行了。于是浏览器获取到304后就去缓存中欢欢喜喜获取资源了。
按下了Ctrl+F5
这个可是要命了,告诉浏览器,你先把你缓存中的这个文件给我删了,然后再去服务器请求个完整的资源文件下来。于是客户端就完成了强行更新的操作…

参考自:
https://www.aliyun.com/jiaocheng/980241.html?spm=5176.100033.2.22.69fb11ea0MUI4K
https://www.aliyun.com/jiaocheng/980412.html?spm=5176.100033.2.23.69fb11eaDVwhXr