三种存在位置
行间式:存在于行间事件中
<body id="body" onload="body.style.backgroundColor=‘#0ff‘"> </body>
内联式:存在于页面script标签中
<body id="body"> <script type="text/javascript"> body.style.backgroundColor=‘#0ff‘ </script> </body>
外联式:存在于外部JS文件,通过script标签src属性链接
index.js文件 body.style.backgroundColor=‘#0ff‘ index.html文件 <script src="./js/index.js"></script>
解释性语言特性决定JS代码位置
出现在head标签底部:依赖型JS库
出现在body标签底部:功能型JS脚本
三种弹出框
alert:普通弹出框 confirm:确认框 prompt:输入框
四种调试方式
alert() console.log() document.write() 浏览器断点调试
变量
变量的含义
即在程序运行过程中它的值是允许改变的量。与它对应的就是常量:即在程序运行过程中它的值是不允许改变的量
四种定义变量的方式
语法: 关键词 变量名 = 变量值
num = 10; // 省略关键词, 定义的为全局变量, 在任何位置定义, 在任何位置都可以访问, 但不建议使用
var num = 10; // var关键词, 无块级作用域, 定义在块级作用域中的变量, 外界也可以访问
let num = 20; // let关键词, 有块级作用域, 定义在块级作用域中的变量, 外界无法访问
const NUM = 30; // const关键词,有块级作用域, 定义在块级作用域中的变量, 外界无法访问, 且变量的值不能再被二次修改, 所以为常量
产生块级作用域的方式
{
直接书写
}
if语句可以产生
while语句可以产生
for语句也可以产生
函数可以产生局部作用域, 除了定义在局部作用域中的全局变量(没有关键字的变量声明), 外界可以访问, 其他定义方式, 外界都不可以访问
变量的规范
可以由哪些组成: 字母, 数字, _, $, 中文(一般不考虑)
可以以什么开头: 字母, _, $, 中文
不能出现什么: 关键字, 保留字
提倡什么书写规范: 小驼峰, 支持_连接语法
严格区分大小写
命名时名称可以出现字母、数字、下划线、$ ,但是不能数字开头,也不能纯数字,不能包含关键字和保留字
关键字:var number等
除了关键字 top name 也尽量不使用。
关键词
| alert | all | anchor | anchors | area |
| assign | blur | button | checkbox | clearInterval |
| clearTimeout | clientInformation | close | closed | confirm |
| constructor | crypto | decodeURI | decodeURIComponent | defaultStatus |
| document | element | elements | embed | embeds |
| encodeURI | encodeURIComponent | escape | event | fileUpload |
| focus | form | forms | frame | innerHeight |
| innerWidth | layer | layers | link | location |
| mimeTypes | navigate | navigator | frames | frameRate |
| hidden | history | image | images | offscreenBuffering |
| open | opener | option | outerHeight | outerWidth |
| packages | pageXOffset | pageYOffset | parent | parseFloat |
| parseInt | password | pkcs11 | plugin | prompt |
| propertyIsEnum | radio | reset | screenX | screenY |
| scroll | secure | select | self | setInterval |
| setTimeout | status | submit | taint | text |
| textarea | top | unescape | untaint | window |
保留字
javascript保留关键词
javascript的保留关键字不可以用作变量,标签或者函数名,有些保留关键字是作为javascript以后扩展使用。
| abstract | arguments | boolean | break | byte |
| case | catch | char | class* | const |
| continue | debugger | default | delete | do |
| double | else | enum* | eval | export* |
| extends* | false | final | finally | float |
| for | function | goto | if | implements |
| import* | in | instanceof | int | interface |
| let | long | native | new | null |
| package | private | protected | public | return |
| short | static | super* | switch | synchronized |
| this | throw | throws | transient | true |
| try | typeof | var | void | volatile |
| while | with | yield |
推荐驼峰命名法:有多个有意义的单词组成名称的时候,第一个单词的首字母小写,其余的单词首字母写
匈牙利命名:就是根据数据类型单词的的首字符作为前缀
Camel 标记法
首字母是小写的,接下来的字母都以大写字符开头。例如:
var myTestValue = 0, mySecondValue = “hi”;
Pascal 标记法
首字母是大写的,接下来的字母都以大写字符开头。例如:
Var MyTestValue = 0, MySecondValue = “hi”;
匈牙利类型标记法
在以 Pascal 标记法命名的变量前附加一个小写字母(或小写字母序列),
说明该变量的类型。例如,i 表示整数,s 表示字符串,如下所示“
Var iMyTestValue = 0, sMySecondValue = “hi”;
运算符
js中的运算符跟python中的运算符有点类似,但也有不同。所谓运算,在数学上,是一种行为,通过已知量的可能的组合,获得新的量。
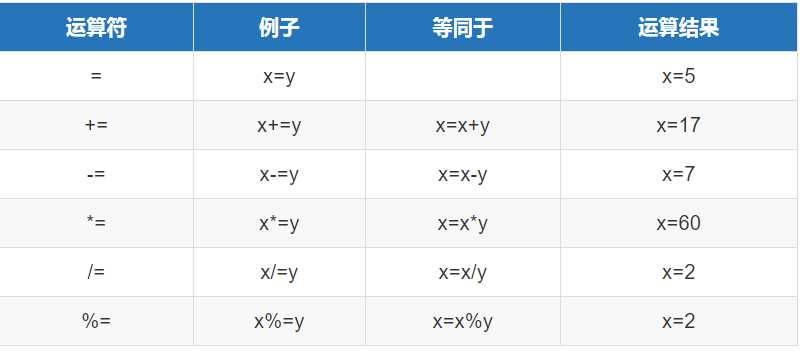
赋值运算符
以var x = 12,y=5来演示示例

算数运算符
var a = 5,b=2

比较运算符
var x = 5;

特殊情况
字符串拼接+字符串运算 特殊情况。python中有拼接字符串中更简便的办法,其实在js中也有,大家可以百度引擎搜索es6模板字符串
var firstName = ‘星‘; var lastName = ‘Li‘; var name = ‘伊拉克‘; var am = ‘美军‘;
字符串拼接
var str = “2003年3月20日,”+name+”战争爆发,
以美军为主的联合部队仅用20多天就击溃了萨达姆的军队。
这是继十多年前的海湾战争后,”+am+”又一次取得的大规模压倒性军事胜利。”
var fullStr = str; console.log(fullStr) var fullName = firstName +" "+ lastName; console.log(fullName)
不能对字符串进行+运算 只能拼接
var a1 = ‘1‘; var a2 = ‘2‘; console.log(a1-a2) //12 var b1 = ‘one‘; var b2 = ‘two‘;
NaN. ==== not a number 是number类型
console.log(typeof(b1*b2))
数据类型
数据类型包括:基本数据类型和引用数据类型
基本数据类型指的是简单的数据段,引用数据类型指的是有多个值构成的对象。
当我们把变量赋值给一个变量时,解析器首先要确认的就是这个值是基本类型值还是引用类型值
基本数据类型
var dog; dog="小虎子"; //字符串,他们总被包含在双引号(或单引号)中 var num; num=1;//数字,它们裸露的出现了 var strNum; strNum="1";//但是现在strNum所引用的是一个字符串,因为它被包含在引号中了 var badNum; badNum=3.345;//一个小数,因为它带有一个小数点 badNum=.2;//仍然是一个小数,这句代码与badNum=0.2是一样的! badNum = 0.4.5;//当然,这句代码是错的,一个非法数字
Undefined 类型
Undefined 类型只有一个值,即 undefined。当声明的变量未初始化时,
该变量的默认值是 undefined。
当函数无明确返回值时,返回的也是值 “undefined”;
Null 类型
另一种只有一个值的类型是 Null,它只有一个专用值 null,即它的字面量。
值 undefined 实际上是从值 null 派生来的,因此 ECMAScript 把它们定义为相等的。
尽管这两个值相等,但它们的含义不同。undefined 是声明了变量但未对
其初始化时赋予该变量的值,null 则用于表示尚未存在的对象(在讨论 typeof
运算符时,简单地介绍过这一点)。如果函数或方法要返回的是对象,那么找不
到该对象时,返回的通常是 null。
var person=new Person()
var person=null
引用类型
function:函数类型
var a = function(){};
console.log(a, typeof a)
// 判断方式
console.log(typeof a == ‘function‘)
object:对象类型
var a = {};
console.log(a, typeof a)
// 判断方式
console.log(typeof a == ‘object‘)
console.log(a instanceof Object)
具体的对象类型
- null:空对象 var a = null; console.log(a, typeof a) // 判断方式 console.log(typeof a == ‘object‘) console.log(a == null) - Array:数组对象 var a = new Array(1, 2, 3, 4, 5); console.log(a, typeof a) // 判断方式 console.log(typeof a == ‘object‘) console.log(a instanceof Object) console.log(a instanceof Array) - Date:时间对象 var a = new Date(); console.log(a, typeof a) // 判断方式 console.log(typeof a == ‘object‘) console.log(a instanceof Object) console.log(a instanceof Date) - RegExp:正则对象 var a = new RegExp(); console.log(a, typeof a) // 判断方式 console.log(typeof a == ‘object‘) console.log(a instanceof Object) console.log(a instanceof RegExp) var d1; //表示变量未定义 console.log(typeof d1) null var c1 = null;//空对象. object console.log(c1)
boolean
简介
Boolean类型仅有两个值:true和false,也代表1和0,实际运算中true=1,false=0
布尔值也可以看作on/off、yes/no、1/0对应true/false
Boolean值主要用于JavaScript的控制语句,例如
if (x==1){
y=y+1;
}else {
y=y-1;
}
var b1 = false;
console.log(typeof b1)
string
var str = ‘123‘
console.log(typeof str)
字符串
是由Unicode字符、数字、标点符号组成的序列
字符串常量首尾由单引号或双引号括起
JavaScript中没有字符类型
常用特殊字符在字符串中的表达
字符串中部分特殊字符必须加上右划线\
常用的转义字符 \n:换行 \‘:单引号 \”:双引号 \\:右划线
字符串相连
var s1="Hello,"; s1=s1+"World!"; alert(s1); s1+="!!!!"; alert(s1);
数学运算与比较
js中的运算符跟python中的运算符有点类似,但也有不同。所谓运算,在数学上,是一种行为,通过已知量的可能的组合,获得新的量。
//加法 +
//减法 –
//乘法 *
//除法 /
//自增 ++
//自减 —
var a = 12; var b = 30; var c = a+b; alert(c);//输出42 c=b-a; alert(c);//输出18 c=c*2; alert(c);//输出36 c=c/2; alert(c);//输出18 c = 12; c++;//这与c=c+1;效果是一样的 alert(c);//输出13 c--;//这与c=c-1;效果是一样的 alert(c);//输出11
自增与自减运算符出现的地方也有讲究
c=20; alert(c++);//输出20,因为++写在变量后面,这表示变量c完成运算之后,再将其值增1 alert(c);//现在将输出21,自减运算符也与些相似 //如果只是类似这样的计算 c = c+12; //可以这样写 c+= 12;//这与写c= c+12;效果是一样的
类似其它的运算也有简便的方法
c-=3;//c=c-3 c*=4;//c=c*3; c/=2;//c=c/2;
要注意的是,在JavaScript,连接字符串时也使用“+”号。当字符串与数字相遇时?——JavaScript是弱类型语言
var num=23+45;
alert("23+45等于"+num);//表达式从左往右计算,字符串之后的数字都会当成字符串然连接
alert("23+45="+(23+45));//使用括号分隔
比较操作符:<,>,<=,>=,==,!=,!;比较操作符返回布尔值
//小于 <
//大于 >
//小于或等于 <=
//大于或等于 >=
//相等 ==
//不相等 !=
alert(2<4);//返回true alert(2>4);//返回false alert(2<=4);//返回true alert(2>=2);//返回true alert(2==2);//返回true alert(2!=2);//返回true
表达式的组合
alert( (2<4)==(5>3)==(3<=3)==(2>=2)==(2!=2)==(2==2)==true );
逻辑运算符
&&逻辑与,当两边的值都为true时返回true,否则返回false
|| 逻辑或,当两边值都为false时返回false,否则返回true
! 逻辑非
alert(true && false);//输出false alert(true && true);//输出true alert(true || false);//输出true alert(false || false);//输出false alert(!true);//输出false
数据类型转换
JavaScript属于松散类型的程序语言,变量在声明的时候并不需要指定数据类型,变量只有在赋值的时候才会确定数据类型,表达式中包含不同类型数据则在计算过程中会强制进行类别转换
数字 + 字符串:数字转换为字符串 数字 + 布尔值:true转换为1,false转换为0 字符串 + 布尔值:布尔值转换为字符串true或false
由于JavaScript是弱类型语言,所以我们安全可以将字符串和数字(两个不同类型的变量)进行相加,这个我们在前面已经演示过了,当然,不仅仅可以将字符串和数据相加,还可以将字符串与数据相乘而不会出现脚本错误!
var str ="some string here!"; var num = 123; alert(str*num);//将输出NaN,因为乘法运算符只能针对数字,
所以进行运算时计算机会将字段串转换成数字
而这里的字符串转换成数字将会是NaN
NaN是一个特殊的值,含义是”Not A Number”-不是一个数字,
当将其它值转换成数字失败时会得到这个值
str ="2"; alert(str*num);//将输出246,因为str可以解析成数字2 var bool = true; alert(bool*1);//输出1 ,布尔值true转换成数字为1,事实上将其它值转换在数字最简单的方法就是将其乘以1 bool = false; alert(bool*1);//输出0 alert(bool+"");//输出"flase",将其它类型转换成字符串的最简单的方法就是将其写一个空字符串相连 alert(123+"");//数字总能转换成字符串 var str = "some string"; alert(!!str);//true,因为非运算符是针对布尔值进行运算的,所以将其它类型转换成布尔值只须将其连续非两次 str =""; alert(!!str);//输出false,只有空字符串转换成布尔值时会是false,非空字符串转换成布尔值都会返回true var num =0; alert(!!num);//false num=-123.345; alert(!!num);//true,除0以外的任何数字转换成布尔值都会是true
//还有一个非常重要的是,空字符串转换成数字将会是0
alert(""*1);//输出0
获取变量类型 typeof 运算符
var bool = true; alert(typeof bool);//输出boolean var num =123; alert(typeof num);//输出number var str = "some string here"; alert(typeof str);//输出string var strNum = "123"; alert(typeof strNum);//输出string strNum *= 1; alert(typeof strNum);//输出number
将数值类型转化成字符串类型
var n1 = 123; var n2 = ‘123‘; var n3 = n1+n2;
隐式转换
console.log(typeof n3);
强制类型转换String(),toString()
var str1 = String(n1); console.log(typeof str1); var num = 234; console.log(num.toString())
将字符串类型转化成数值类型
var stringNum = ‘789.123wadjhkd‘; var num2 = Number(stringNum); console.log(num2) // parseInt()可以解析一个字符串 并且返回一个整数 console.log(parseInt(stringNum)) console.log(parseFloat(stringNum));
任何数据类型都可以转换成boolean类型
var b1 = ‘123‘; var b2 = 0; var b3 = -123 var b4 = Infinity; var b5 = NaN; var b6; //undefined var b7 = null;
非0既真
console.log(Boolean(b7))