Skip to content
California, TX 70240 | (1800) 456 7890
云博客
云博客
前端
windos
微信
数据库
移动开发
技术杂谈
前端
windos
微信
数据库
移动开发
技术杂谈
Home
vue+ 上传文件 可下载实例文件
前端
vue+ 上传文件 可下载实例文件
云博小周宇
2024年5月5日
2023年8月4日
1 Min Read
1. 结构:
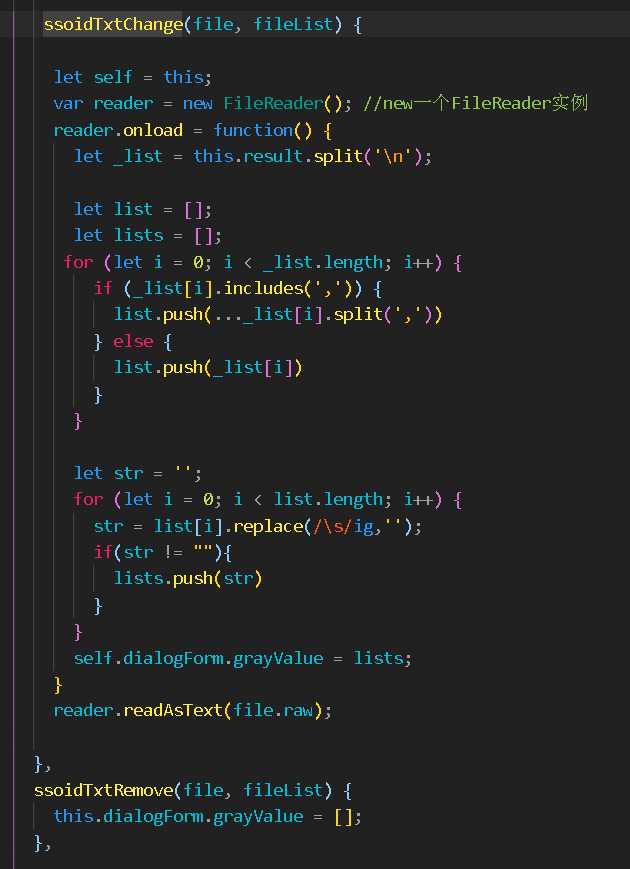
2.方法:
3.效果:
Previous Post
vue中wowjs的使用
Next Post
jstack,jmap,jstat分别的意义