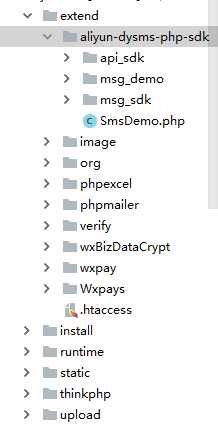
1.登录阿里云账号下载——aliyun-dysms-php-sdk(我使用的php版本)
下载地址:https://help.aliyun.com/document_detail/55359.html?spm=a2c4g.11174283.3.3.30d72c42m24zNH
2.下载的sdk包放在extend下(我用的tp5框架)

3.修改SmsDemo.php配置文件的参数改成自己的AccessKeyId 与 AccessKeySecret
4.应用实例
/** * 发送验证码 */
public function yanzheng(){ Loader::import(‘aliyun-dysms-php-sdk.SmsDemo‘);//将附件放入根目录下的/extend
$tel=input(‘post.tel‘); $num=$this->randomStr(); $request = new \SmsDemo(); $res= $request::sendSms($tel,$num); if($res->Message==‘触发天级流控Permits:10‘){ return GYReturn(‘1‘,‘发送失败‘,‘一天最多发布十条‘); } else if($res->Message==‘触发天级流控Permits:5‘){ return GYReturn(‘1‘,‘发送失败‘,‘一个小时之内只能发布五条‘); } else if($res->Message==‘触发天级流控Permits:1‘){ return GYReturn(‘1‘,‘发送失败‘,‘发送验证码时间超出一分钟才能再次发送‘); }else if($res->Message==‘OK‘){ return GYReturn(‘1‘,‘发送成功‘,$num); } }