rpc原理,和httpclient
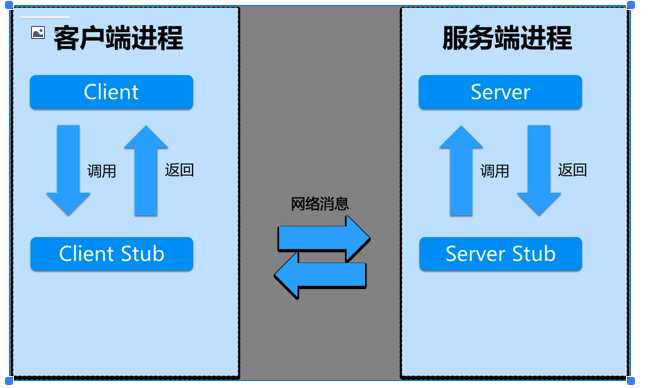
客户端(Client),服务的调用方。
- 服务端(Server),真正的服务提供者。
- 客户端存根,存放服务端的地址消息,再将客户端的请求参数打包成网络消息,然后通过网络远程发送给服务方。
- 服务端存根,接收客户端发送过来的消息,将消息解包,并调用本地的方法。
dubbo等框架做的事情 通讯问题 : 主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。 寻址问题 : A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。比如基于Web服务协议栈的RPC,就要提供一个endpoint URI,或者是从UDDI服务上查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。 序列化 与 反序列化 : 当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal),通过寻址和传输将序列化的二进制发送给B服务器。 同理,B服务器接收参数要将参数反序列化。B服务器应用调用自己的方法处理后返回的结果也要序列化给A服务器,A服务器接收也要经过反序列化的过程。 dubbo只解决了以上问题。但是没解决服务注册 服务发现 服务管理 负载均衡(专责) 所以rpc框架的好处 1解耦2负载均衡。专职专司3容错。服务发现。调用方便。像调用本地方法一样简答4适合接口多的项目。 (写一大堆 http请求 一大堆接口。难以管理。rpc是加在配置文件中。然后调用去配置文件中查。而httpclient 是用原生的请求响应模型。简单方便。) 坏处就是麻烦:代理存根。容错。需要注册中心管理 zookeeper可以作为注册中心 1负载均衡 自动选择低负载的服务2基于接口找Ip找对应的服务。外部不感知。3容错。如服务端重启了。自动回复。 1 rpc是基于自定义tcp 没有太多的垃圾数据 而httpclient 基于http协议,做请求响应,要模仿网页请求,访问服务端,报文头垃圾数据较多 简单直接快速开发 面对小企业特别好用 但是当服务特别多的时候就不那么好用 2rpc框架都是基于面向服务的,封装了服务发现和函数代理调用,并且优化了效率。