摘要
语音盲带宽扩展技术已经出现了一段时间,但到目前为止还没有出现广泛的部署,部分原因是增加的带宽伴随着附加的工件。本文提出了三代盲带宽扩展技术,从矢量量化映射到高斯混合模型,再到基于生成对抗性网络的深层神经网络的最新体系结构。这种最新的方法在质量上有了很大的提高,并证明了基于机器学习的盲带宽扩展算法在客观上和主观上都能达到与宽带编解码器相当的质量。我们相信,盲带宽扩展现在可以达到足够高的质量,以保证在现有的电信网络中部署。
关键词:盲源带宽扩展,人工带宽扩展,生成对抗性网络,客观质量评价,主观质量评价,POLQA
一、引言
直到几年前,语音通信的质量一直受到100多年前的设计选择的限制,这导致了8 kHz采样率实际频率使用范围为300-3400 Hz。这种所谓的窄带(NB)频率范围严重限制了语音质量。最近业界已开始转向“高清声音”和“超高清声音”技术,它们分别使用宽带(WB)或超宽带(SWB)编码器,使得采样率分别为16 kHz或32 kHz映射成50-7000 Hz或50-14000 Hz的频率范围[1][2]。
然而,WB和SWB部署并不普遍,因为需要大量的成本去开发、测试、和部署支持的服务。此外,端到端的WB/SWB呼叫需要在两端升级设备.要达到全面覆盖和手机普及率,可能需要数年的时间,而将固定电话网络升级到WB/SWB可能需要更长的时间。在此之前,很大一部分呼叫仍将使用遗留窄带。
盲源带宽扩展(BBE)技术就是通过将NB语音转换为WB或SWB语音来解决这个问题。在本文中为了简单我们将只关注于WB的情况。
二、背景
2.1 相关工作
已经提出了各种盲源频带扩展的统计方法,从语音0~4kHz的低频部分(LB)预测4~8kHz的高频部分(HB)。通常,使用某种形式的谱折叠或统计建模来产生具有宽带语音[3][4]一般特征的信号。虽然不能期望完美的预测,但可以获得合理的高质量的语音。
矢量量化(VQ)码本映射可以用来创建语音参数从LB到HB[5][6]的离散映射。基于高斯混合模型(GMM)的方法,通过对语音包络参数的连续建模,用来保存了LB到HB之间更加精确的转换。隐马尔可夫模型(HMM)通过利用语音时态信息来扩展GMMs[8]。基于神经网络的盲源频带扩展方法,如深神经网络,已经被提出,因为它们可以对高度非线性问题进行更好的建模[9]。
2.2 损失函数(Loss)与GANs
本文所讨论的统计模型都是基于回归问题中最基本的损失函数——均方误差(MSE),它测量了HB语音包络特征在预测值和真实值之间的差异。MSE损失函数在一般意义上工作良好,但难以处理恢复缺失语音HB时固有的不确定性,如详细的频谱形状和浊音/清音能量。最小化MSE会发现看似真实的参数平均值,这就是典型的过拟合,因而具有较差的感知质量。
GANs已在[10]中引入,并已成功地应用于图像处理领域,如图像到图像的转化[11]、图像的超分辨率[12]和文本到图像的合成[13]。GAN训练阶段重建向高概率搜索空间的区域移动,高概率搜索空间包含真实HB语音参数分布,从而接近自然语音HB波形[12]。在这篇文章中,我们研究了GANs在盲源频带扩展上面是如何训练的。
三、盲源频带扩展的框架
一般情况下,盲源频带扩展框架是建立在经典的源滤波器语音产生模型的基础上的。利用该模型,窄带语音信号的宽带扩展可分为两个子任务:
- 高频谱包络的估计
- 窄带激励信号的扩展
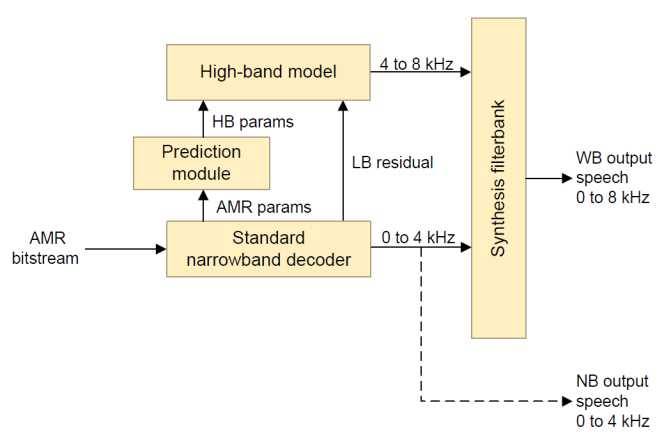
为了合成高频语音信号,我们利用EVRC-WB[14]中的高带宽模型。图一显示了我们的盲源频带扩展框架的总体图。
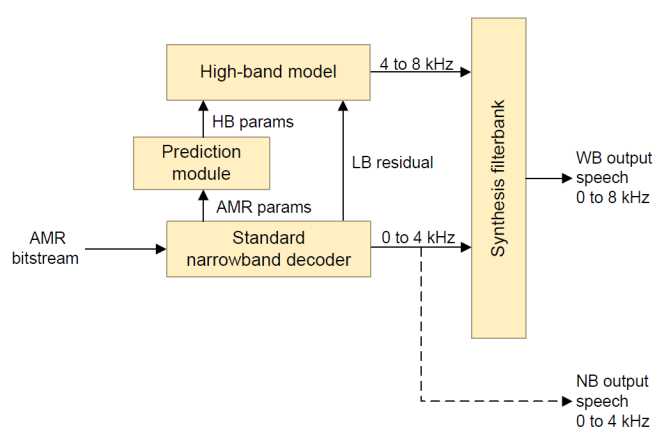
3.1 高频带激励
高频带(HB)激励是由窄带(NB)激励通过一个非线性函数产生的,该函数产生保持信号谐波结构的高频段激励[14]。
3.2 高频带谱包络
在我们的语音高频带HB扩展模型中,对于每20ms的语音帧,使用六阶线谱频率(LSF)对高频带HB进行频谱化,再加上低频带和高频带之间能量比对应的增益因子[14]。
3.3 框架验证
对该框架进行了测试,验证了从原始带宽WB语音中提取高频参数HB时所提供的质量不低于AMR-WB 12.65kbps的客观和主观性能。因为该框架性能的瓶颈,所以盲源频带扩展BBE通常达不到12.65kbps的AMR-WB 12.65kbps的质量。该框架还用于EVRC-WB和高通专有的eAMR WB编解码器[16]。
四、高频带HB参数预测
4.1 语音参数
| 输入 | 输出 |
| 10阶低频LSFs + Delta LSFs | 6阶高频的LSF |
| 4kHz语音能量 | 4-8kHz语音能量 |
表一:预测器输入输出参数
在我们的高频带HB预测实验中使用的参数列于表1。LB LSFs的后向对冲值用于改进预测,而不需要额外的延迟。
4.2.最小均方误差的统计建模
4.2.1.VQ码本映射
最基本的方法是码本映射。从宽带语音中提取LB和HB语音包络参数,并进一步使用诸如K近邻的聚类方法来训练VQ码本。在估计阶段,将接收到的窄带参数与码本中的LB包络参数进行比较,然后选择最接近接收到的窄带包络参数的条目。所选条目对应的HB包络参数用作HB谱包络参数[5]。在实践中,最近的码本条目被内插,加权于它们的LB包络参数和接收到的窄带包络参数之间的距离[6]。
4.2.2.高斯混合模型(GMM)
与码本映射相比,GMM可以连续地对语音包络数据进行建模,从而实现软聚类。训练使用期望最大化(EM)和最大似然估计(MLE)进行[7]。该概率框架在训练过程中引入状态转移概率矩阵,灵活地融合了语音时域信息,将模型转化为GMM/HMM混合模型。增加隐马尔可夫(HMM)分量的主要好处在于它可以隐式地利用先前语音帧中的信息来提高估计精度[8]。文[7]详细讨论了LB参数到HB参数的混合均值和协方差矩阵的变形技术。
4.3.用GANs进行统计建模
4.3.1.生成对抗性网络框架
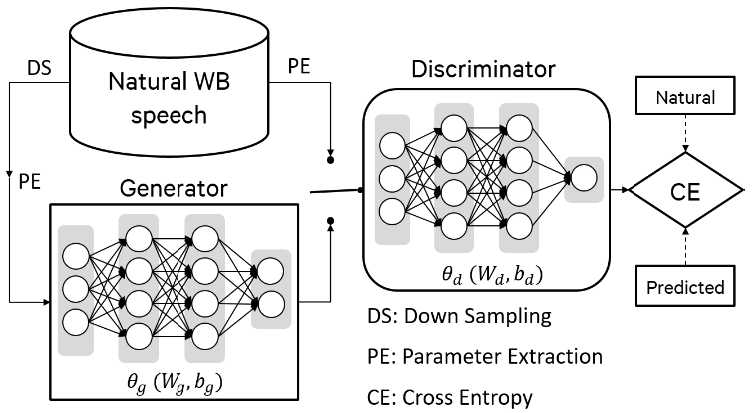
图二: BBE-GAN 框架
GAN[10]包括发生器(G)和鉴别器(D),如图2所示。这里,对于我们的BBE-GAN系统,G是一个深度神经网络,它根据LB参数预测HB参数。D是另一个用作二进制分类器的深层神经网络,它试图区分预测HB参数和自然HB语音参数。
在对抗训练中,G试图通过调整其权重和偏置项来愚弄D,从而使D相信它的输出是自然的。D和G是迭代训练的,它们都试图击败对方。这种方法导致G生成与自然数据相同分布的输出,因此可以生成更自然的语音。
4.3.2 MSE Loss的预训练
深神经网络已经被应用于BBE问题,在[9]中使用了MSE Loss。我们以这样一个模型作为起点。这里,一个四层DNN网络高频带LSFs和能量的生成器使用标准的MSE Loss进行预训练,为了使GAN训练过程有一个好的初始生成器,预训练是至关重要的,这有助于避免不稳定的问题。
4.3.3 知觉Loss函数
感知Loss函数$l$的定义对生成器网络的性能起着至关重要的作用。在SRGAN[12]中的感知Loss函数设计的启发下,我们将HB语音包络参数$l{params}$与对抗网络的Loss$l_{adv}$结合起来,将感知Loss作为加权和,如式(1)所示。
$$l = l_{params}+10^{-2}*l_{adv}$$
5. 实验
5.1 开始
我们以NTT 1994多语言语料库[17]为训练和验证数据,采用10倍交叉验证方案,进行了语音带宽扩展实验。数据以16 kHz采样率采样,数字化为16位分辨率,采用ITU-TP.341兼容滤波器模拟典型的TX手机响应。我们使用itu-t p.501英国英语[18]作为评估数据集。
对于BBE-VQ,我们使用单独的256元素VQ码本来处理Hb lsfs和增益.三个最近的候选人的加权组合用于预测。
对于BBE-GMM,我们使用了一个GMM HMM混合模型,该混合模型有64个状态,每个状态有4个混合状态,并且具有完全的协方差矩阵。该算法采用Viterbi译码算法的前向路径,不需要前瞻时延。
对于BBE-GAN,发生器和鉴别器都是四层前馈(1层输入层、1层输出层、2层隐层),每个隐层有1024个神经元.ADAM优化器在培训期间使用。
图3和图4显示了在迭代0、100和200的对抗训练过程中典型有声段和无声段的频谱包络。我们可以清楚地看到,随着损失函数的远离MSE,BBE-GAN输出正朝着参考WB语音的频谱移动。GAN培训过程是提高无声段的能量,同时清除无声段期间不需要的HB噪声。这导致语音质量显著提高,具有较少的可听伪影和更高的自然度。
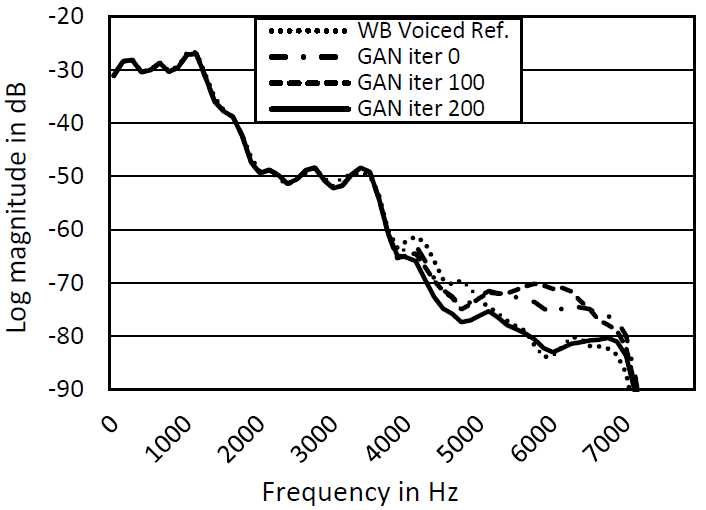
图3:语音输出与GAN迭代
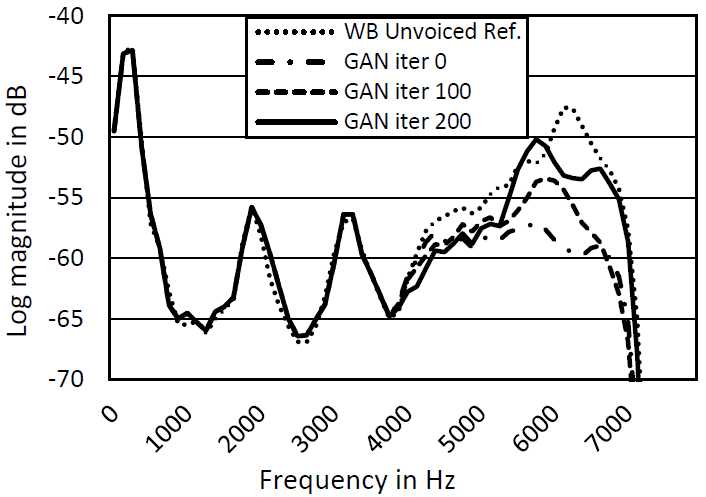
图4:无声语音输出与GAN迭代
5.2 客观表现
对于客观评价,我们遵循了[19]中描述的方法,并在ITU-tp补编中进行了定义。27[20]。为了满足带宽需求,我们以ITU-T-501英国英语语音材料为输入,分别测量了3 GPP RX掩码[21]的RX频率响应。在语音质量方面,我们用P.501英式英语测试POLQA[22]的输出分数,用Amr 12.2kbps编码。
我们为BBE算法绘制了POLQA分数以上讨论。AMR-NB的评分为12.2kbps,和AMR-WB在8.85kbps和12.65kbps时显示为参考文献。结果如图5所示,其中0dB指示响应遵循掩码的下限。从BBE-VQ到BBE-GMM都有明显的改进BBE-GAN,显示了所使用的统计模型的不断增强的建模能力。在迭代0处的GAN与GAN之间在迭代200(完全训练)处,最大POLQA值类似的,但是BBE-GAN在200次迭代时也是这样以更高的数量更好地保持其POLQA得分带宽。这是预测质量的良好指示,并且通过减少来自完全训练的GAN的预测伪影。
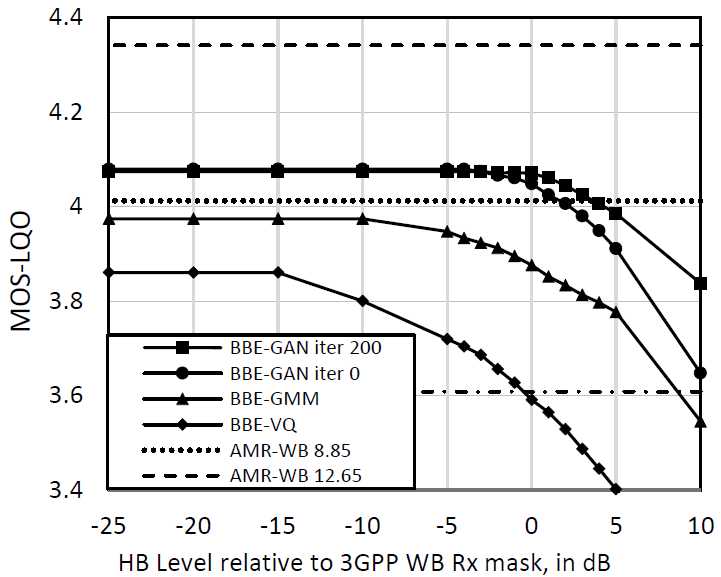
图5:POLQA mos-lqo vs带宽
5.3.主观表现
采用ITU-T-P.800方法对本文提出的各种算法的主观性能进行了评价.一个退化等级(DCR)[23]测试是在一个独立的测试实验室进行的。测试使用了32个侦听器、42个条件和每个条件下192张选票。DCR测试的结果如图6所示,误差条表示95%的置信区间。分数与图5所示的客观结果一致。

图6:3 GPP掩模水平的P.800 DCR MOS-LQS
在8.85kbps时BBE-GAN与AMR-WB在统计上等价。在[19]中可以找到更多关于BBE-VQ和BBE-GMM的测试结果(其中它们分别对应于算法BBE3和BBE4)
5.4 Hb衰减与主观品质
我们应用了几个滤波器对培-GaN,以调整Hb水平从5db到-10 dB相对于3 GPP WB RX掩膜。图7显示了这些条件的p.800DCR分数。注意,如图5所示,该级别相对于下掩码限制,因此-5db表示低于掩码下限的响应,而5db表示掩码的上限和下限之间的响应。
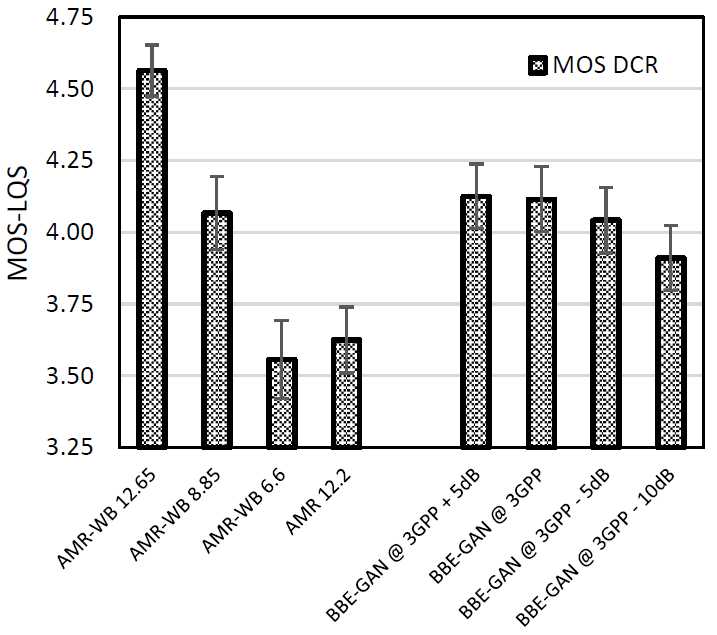
图7:DCR MOS vs bandwidth
我们观察到,如图5所示的客观度量结果所预测的那样,培-GaN即使在更高的带宽水平上也能保持性能。这也说明了在带宽和质量上与WB编解码器完全相当,并再次证实了客观评价与主观结果的一致性[19][20]。
六、结论
本文提出了三代盲带宽扩展技术,从VQ到GMM到GaN。我们发现,与经典的统计建模技术相比,像GaN这样的机器学习技术在质量上有了显著的提高。基于GaN的预测可以使其质量与WB编解码器相类似,在客观上和主观上都达到了相当于Amr-WB 8.85kbps质量的性能。虽然培技术已经研究了很多年,但由于它不能提供与宽带编解码器类似的质量,所以还没有得到广泛的应用。我们已经表明,使用GaN等机器学习技术可以达到这一质量水平,这有可能加快电信网络中广泛采用培的速度。
七、参考文献
[1] 3GPP TS 26.190, “Adaptive multi-rate wideband (AMR-WB) speech codec; Transcoding functions,” 3rd Generation Partnership Project, Sept. 2012, version 11.0.0.
[2] 3GPP TS 26.441, “Codec for Enhanced Voice Services (EVS); General overview,” 3rd Generation Partnership Project, Dec. 2015, version 13.0.0.
[3] H. Carl and U. Heute, “Bandwidth enhancement of narrowband speech signals,” in Proc. EUSIPCO, vol. 2, Edinburgh, UK, Sept. 1994, pp. 1178–1181.
[4] H. Pulakka and P. Alku, “Bandwidth extension of telephone speech using a neural network and a filter bank implementation for highband mel spectrum,” IEEE Trans. Audio, Speech, Language Process., vol. 19, no. 7, pp. 2170–2183, Sept. 2011.
[5] Y. Qian and P. Kabal, “Wideband speech recovery from narrowband speech using Classified codebook mapping”, Proceedings of the 9th Australian International Conference on Speech Science & Technology Melbourne, Dec. 2002.
[6] J. Epps and W. H. Holmes, “A new technique for wideband enhancement of coded narrowband speech,” in Proc. IEEE Speech Coding Workshop, 1999, pp. 174–176.
[7] K.-Y. Park and H. S. Kim, “Narrowband to wideband conversion of speech using GMM based transformation,” in Proc. ICASSP 2000, pp.1843–1846.
[8] P. Jax and P. Vary, “Artificial bandwidth extension of speech signals using MMSE estimation based on a Hidden Markov model,” in Proc. ICASSP 2003, pp. 680-683.
[9] Y. Wang, S. Zhao, W. Liu, M. Li, J. Kuang, “Speech bandwidth expansion based on Deep Neural Networks,” in Proc. INTERSPEECH 2015, pp. 2593-2597.
[10] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y. Bengio. “Generative adversarial nets,” in Advances in Neural Information Processing Systems (NIPS), pages 2672–2680, 2014.
[11] P. Isola, J. Zhu, T. Zhou, A. A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” arXiv:1611.07004.
[12] C. Ledig, et al. “Photo-Realistic Single Image Super- Resolution Using a Generative Adversarial Network,” arXiv:1609.04802.
[13] H. Zhang, et al. “StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks,” arXiv:1616.03242.
[14] 3GPP2 C.S0014-C v1.0 “Enhanced Variable Rate Codec, Speech Service Option 3, 68 and 70 for Wideband Spread Spectrum Digital Systems”.
[15] 3GPP TS 26.090, “Adaptive multi-rate (AMR) speech codec; Transcoding functions,” 3rd Generation Partnership Project, Sept. 2012, version 11.0.0.
[16] S. Villette, S. Li, P. Ramadas, D. Sinder, “eAMR: Wideband speech over legacy narrowband networks,” in Proc. ICASSP 2017, pp. 5110-5114.
[17] N. A. T. Corporation, “Multi-lingual speech database for telephonometry,” http://www.nttat. com/products e/speech, 1994.
[18] ITU-T P.501, “Test signals for use in telephonometry,” Int. Telecommunication. Union, Jan. 2012.
[19] S.Villette, S. Li, P. Ramadas, D. Sinder, “An Objective Evaluation Methodology for Blind Bandwidth Extension,” in Proc. INTERSPEECH 2016, pp 2548-2552.
[20] ITU-T P Suppl. 27, “Application of ITU-T P.863 and ITU-T P.863.1 for speech processed by blind bandwidth extension approaches,” Int. Telecomm. Union, Geneva, 2017.
[21] 3GPP TS 26.131, “Terminal acoustic characteristics for telephony; Requirements,” 3rd Generation Partnership Project, Dec. 2015, version 13.2.0.
[22] ITU-T Rec. P.863, “Perceptual Objective Listening Quality Assessment,” Int. Telecomm. Union, Geneva, 2011.
[23] ITU-T P.800, “Methods for subjective determination of transmission quality,” Int. Telecommunication Union, Aug. 1996.