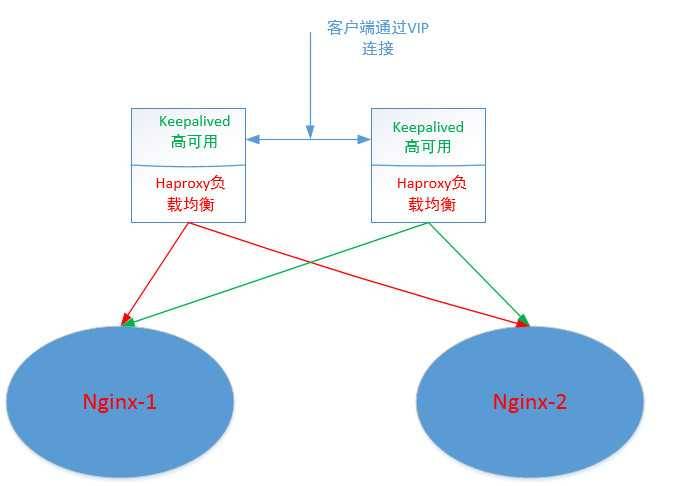
现有如下的web架构(简化之后的),需要把原来的http访问修改到https访问!

haproxy的认证有两种方式:
第一种:haproxy提供ssl证书,后面的nginx访问使用正常的http。
第二种:haproxy做正常的代理,后面的nginx提供ssl证书!
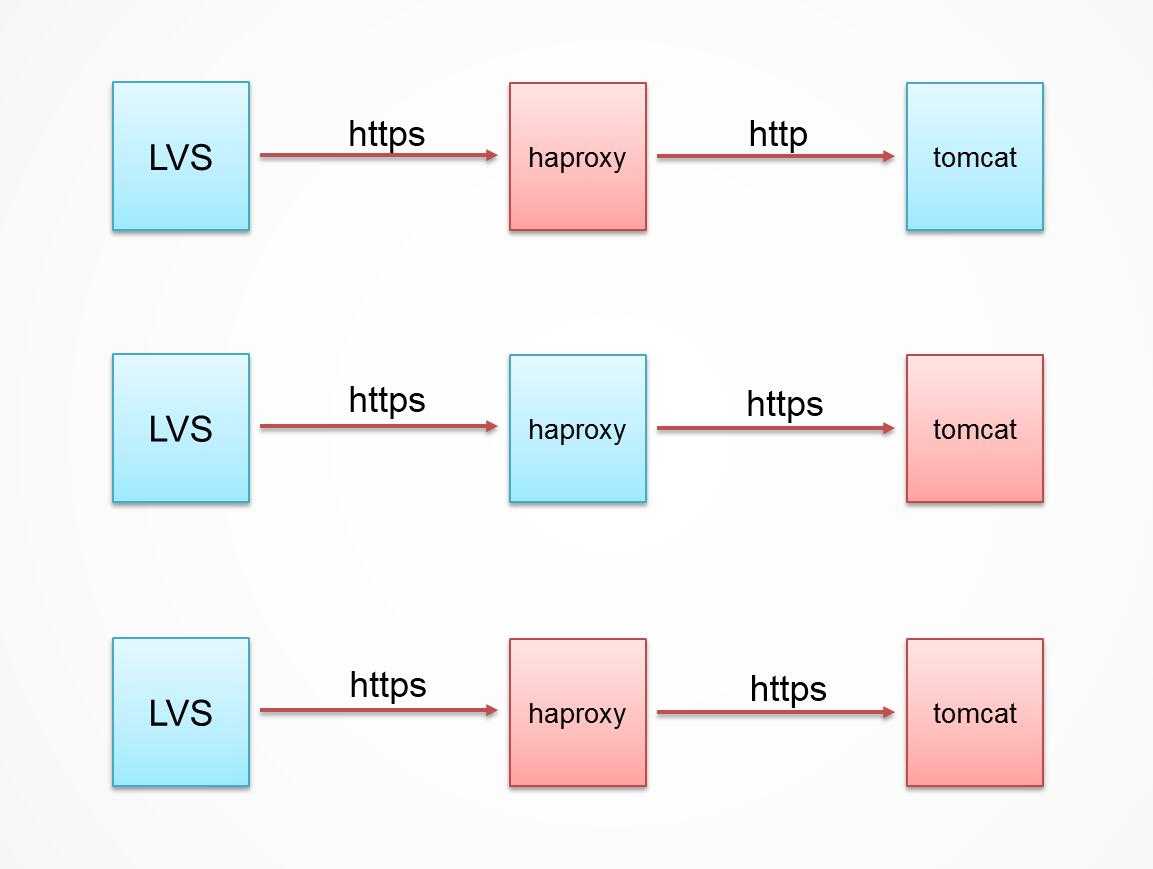
总共下面三种的组合方式:
-
第一种是我们选择的模式,在haproxy这里设定SSL,这样我们可以继续使用七层负载均衡。SSL连接终止在负载均衡器haproxy —–>解码SSL连接并发送非加密连接到后端应用tomcat,这意味着负载均衡器负责解码SSL连接,这与SSL穿透相反,它是直接向代理服务器发送SSL连接的。
-
第二种使用SSL穿透,SSL连接在每个tomcat服务器终止,将CPU负载都分散到tomcat服务器。然而,这样做会让你失去增加或修改HTTP报头的能力,因为连接只是简单地从负载均衡器路由到tomcat服务器,这意味着应用服务器会失去获取 X-Forwarded-* 报头的能力,这个报头包含了客户端IP地址、端口和使用的协议。
-
有两种策略的组合做法,那就是第三种,SSL连接在负载均衡器处终止,按需求调整,然后作为新的SSL连接代理到后台服务器。这可能会提供最大的安全性和发送客户端信息的能力。这样做的代价是更多的CPU能耗和稍复杂一点的配置。
-
选择哪个策略取决于你及应用的需求。SSL终端为我所见过最典型的策略,但SSL穿透可能会更安全。
这段说明摘自:https://www.cnblogs.com/zhanmeiliang/p/6232245.html
在说明ssl认证之前,先简单介绍一下ssl。
使用HTTP(超文本传输)协议访问互联网上的数据是没有经过加密的。也就是说,任何人都可以通过适当的工具拦截或者监听到在网络上传输的数据流。但是有时候,我们需要在网络上传输一些安全性或者私秘性的数据,譬如:包含信用卡及商品信息的电子订单。这个时候,如果仍然使用HTTP协议,势必会面临非常大的风险!相信没有人能接受自己的信用卡号在互联网上裸奔。
HTTPS(超文本传输安全)协议无疑可以有效的解决这一问题。所谓HTTPS,其实就是HTTP和SSL/TLS的组合,用以提供加密通讯及对网络服务器的身份鉴定。HTTPS的主要思想是在不安全的网络上创建一安全信道,防止黑客的窃听和攻击。
SSL(安全套接层)可以用来对Web服务器和客户端之间的数据流进行加密。
SSL利用非对称密码技术进行数据加密。加密过程中使用到两个秘钥:一个公钥和一个与之对应的私钥。使用公钥加密的数据,只能用与之对应的私钥解密;而使用私钥加密的数据,也只能用与之对应的公钥解密。因此,如果在网络上传输的消息或数据流是被服务器的私钥加密的,则只能使用与其对应的公钥解密,从而可以保证客户端与与服务器之间的数据安全。
数字证书(Certificate)
在HTTPS的传输过程中,有一个非常关键的角色——数字证书,那什么是数字证书?又有什么作用呢?
所谓数字证书,是一种用于电脑的身份识别机制。由数字证书颁发机构(CA)对使用私钥创建的签名请求文件做的签名(盖章),表示CA结构对证书持有者的认可。数字证书拥有以下几个优点:
使用数字证书能够提高用户的可信度
数字证书中的公钥,能够与服务端的私钥配对使用,实现数据传输过程中的加密和解密
在证认使用者身份期间,使用者的敏感个人数据并不会被传输至证书持有者的网络系统上
X.509证书包含三个文件:key,csr,crt。
key是服务器上的私钥文件,用于对发送给客户端数据的加密,以及对从客户端接收到数据的解密
csr是证书签名请求文件,用于提交给证书颁发机构(CA)对证书签名
crt是由证书颁发机构(CA)签名后的证书,或者是开发者自签名的证书,包含证书持有人的信息,持有人的公钥,以及签署者的签名等信息
备注:在密码学中,X.509是一个标准,规范了公开秘钥认证、证书吊销列表、授权凭证、凭证路径验证算法等。
摘自:https://www.cnblogs.com/lihuang/articles/4205540.html
经典ssl认证
使用haproxy提供ssl证书的模式,因为这里是内网使用或者是测试使用,我们自己创建证书!
第一步: 生成私钥
使用openssl工具生成一个RSA私钥。
openssl genrsa -out server.key 2048
#这个过程可以指定使用的算法,并且也可以指定生成私钥的密码
第二步:生成csr
openssl req -new -key server.key -out server.csr
#这个过程需要填入一些信息,若是测试使用时,可以选择不填,直接回车即可
第三步:生成自签名证书
openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
第四步:拼接pem文件
接着,在创建了证书之后,我们需要创建pem文件。pem文件本质上只是将证书、密钥及证书认证中心证书(可有可无)拼接成一个文件。在我们的例子中,我们只是简单地将证书及密钥文件并以这个顺序拼接在一样来创建pem 文件。这是HAProxy读取SSL证书首选的方式。
cat server.crt server.key | tee server.pem
这样证书文件已经创建完毕,然后就是在需要的地方加载证书设置!
设置haproxy提供ssl证书
首先查看当前的ssl是否支持ssl认证:
[root@test1 ~]# ldd /usr/sbin/haproxy |grep ssl libssl.so.10 => /usr/lib64/libssl.so.10 (0x00007fbefd4fc000)
#若有如上显示,则说明当前的haproxy支持ssl认证
在haproxy配置文件中配置ssl支持:
listen webserver bind *:443 ssl crt /tmp/server.pem #这里配置ssl支持,pem文件的使用绝对路径 balance roundrobin server app1 10.0.102.214:80 check weight 2 server app2 10.0.102.204:80 check weight 1
然后再配置文件的global块中,加入如下配置:
global
......
tune.ssl.default-dh-param 2048
......
#若不加这个配置,会报reload错误
然后重启haproxy,即可!
然后通过vip也就是10.0.102.110访问
配置后端的服务器提供ssl证书
后端服务器使用的是nginx,这里就是对nginx配置https认证!若是源码安装,则nginx编译时需要加入如下参数:
./configure --with-http_ssl_module
#这个模块依赖openssl,因此需要提前安装对应的依赖包
yum -y install openssl openssl-devel
然后就是创建对应的认证证书,过程参考上面的,证书创建完毕之后,编写配置文件!
server { listen 443 ssl; server_name localhost; ssl_certificate cert/server.pem; ssl_certificate_key cert/server.key; ssl_session_cache shared:SSL:1m; ssl_session_timeout 5m; ssl_ciphers HIGH:!aNULL:!MD5; ssl_prefer_server_ciphers on; location / { root html; index index.html index.htm; } }
nginx配置文件中默认有如上配置,打开对应的注释,然后修改证书的路径!注意证书的路径是相对当前配置文件所在的路径的!
然后需要修改haproxy中的配置:如下
listen webserver bind *:443 mode tcp balance roundrobin server app1 10.0.102.214:443 check weight 2 server app2 10.0.102.204:443 check weight 1
注意在使用haproxy作为代理,在后端提供ssl认证时,需要把mode修改为tcp!
这里配置的权重是2:1,但是在测试的时候不是按照2:1的比例出现。先跳app1,过一段时间在跳app2,不知道为啥?