Skip to content
California, TX 70240 | (1800) 456 7890
云博客
云博客
前端
windos
微信
数据库
移动开发
技术杂谈
前端
windos
微信
数据库
移动开发
技术杂谈
Home
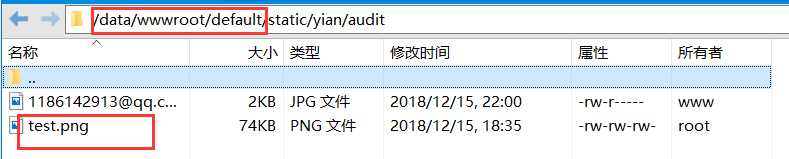
nginx+tomcat环境下,web项目文件上传问题(未完待续)
1aa98b8cd029f68880511d6bbbb16dba.jpg
1aa98b8cd029f68880511d6bbbb16dba.jpg
发表回复
要发表评论,您必须先
登录
。