本文的参考的github工程链接:https://github.com/laubonghaudoi/CapsNet_guide_PyTorch
之前是看过一些深度学习的代码,但是没有养成良好的阅读规范,由于最近在学习CapsNet的原理,在Github找到了一个很好的示例教程,作者甚至给出了比较好的代码阅读顺序,私以为该顺序具有较强的代码阅读迁移性,遂以此工程为例将该代码分析过程记录于此:
1、代码先看main(),main()为工程中最为顶层的设计,能够给人对于整个流程的把控。而对于深度学习而言,main一般即为加载数据、构建模型、确定优化算法、训练网络模型、保存模型参数这种很具有规范性的结构。
1 if __name__ == "__main__": 2 # Default configurations 3 opt = get_opts() 4 train_loader, test_loader = get_dataloader(opt) 5 6 # Initialize CapsNet 7 model = CapsNet(opt) 8 9 # Enable GPU usage 10 if opt.use_cuda & torch.cuda.is_available(): 11 model.cuda() 12 13 # Print the model architecture and parameters 14 print("Model architectures: ") 15 print(model) 16 17 print("\nSizes of parameters: ") 18 for name, param in model.named_parameters(): 19 print("{}: {}".format(name, list(param.size()))) 20 n_params = sum([p.nelement() for p in model.parameters()]) 21 # The coupling coefficients b_ij are not included in the parameter list, 22 # we need to add them mannually, which is 1152 * 10 = 11520. 23 print(‘\nTotal number of parameters: %d \n‘ % (n_params+11520)) 24 25 # Make model checkpoint directory 26 if not os.path.exists(‘ckpt‘): 27 os.makedirs(‘ckpt‘) 28 29 # Start training 30 train(opt, train_loader, test_loader, model, writer)
2、后面看utils.py文件里面的函数,很多比较复杂的工程中都会有这个文件,一般都是一些工程中较为基础的函数,在CapsNet这个工程中,这个文件中包含了相关的配置以及dataloarder。
def get_dataloader(opt): # MNIST Dataset ... # Data Loader (Input Pipeline) ... return train_loader, test_loader def get_opts(): parser = argparse.ArgumentParser(description=‘CapsNet‘) # .... opt = parser.parse_args() return opt
3、然后在弄明白前向传播中最为顶层的设计,一般就是顶层神经网络的__init__()以及forward()
该工程中的CapsNet主要分为四个大部分:
- Conv2d, 用了256个 9×9的卷积核,步长为1,后面跟着Relu。这样对于28*28的图片,输出为[256,20,20 ]
- PrimaryCaps: capsule层,具体构造后面再讲
- DigitCaps:capsule层,具体构造后面再讲
- Decoder:全连接层
4、在网络前向传播的顶层肯定调用了一些层级稍微低一些的module,下面就看这些module,本工程中主要是PrimaryCaps和DigitCaps。
PrimaryCaps
PrimaryCaps包含了32个 capsule units, 每个capsule unit都会接收来自于第一层卷积所输出的feature map的所有数据。首先获得32个张量u,这32个张量u是通过32个卷积运算得到的,前面输入的为第一层卷积所得[256,20,20 ]的feature maps,32个卷积每个都是(out_channels=8, kernel_size=9, stride=2),这个地方使用了Modulelist来构造重复的卷积运算module,值得学习。在forward中将每个卷积moduel计算所得的结果append到list中,这样后面使用torch.cat的时候可以直接使用了。问题在于后面对于这32个张量的维度顺序做了变换。
坐标顺序变换记录于此:
- 每个conv_module输出为[batch_size, 8 ,6,6],便变成了[batch_size, 8 ,36, 1]的形式,也就是这8个feature map中的每个6×6的feature map变成了一个向量
- 对32个conv_module输出的张量cat,保存形式为[batch_size, 8, 36, 32]
- 再次变换为[batch_size,8,36×32] ,这个地方我并没有搞懂这么做有什么意义,这和直接拿32*8个卷积核去卷积的区别在哪呢?直接拿32个卷积核卷积,然后将这32*8个卷积核再分为8组不也一样吗?
- 做了一次维度变换,变为[batch_size, 36×32,8]的形式
上步计算完成后,后面计算squash,这步计算类似于Relu,相当于向量的Relu操作。这个地方可以看出一个很重要的一点,就是向量v是几维的,一个基本的v包含几个数,从代码中看是8个数,也就是说PrimaryCaps开始时的每个卷积module输出的channels数为8,是这个维度组成了向量。
DigitCaps
这一层和上一层都是由capsule组成的,中间的连接是类似于全连接但又有很多的不同。
下面的表示均忽略batch_size:
上一层的输入[36*32,8], 也就是有36*32个输入向量u。计算步骤如下:
- 首先计算u_hat,将输入变换为[36*32,1,1,8]的形式,中间权重为[36*32, 10, 8, 16],这样矩阵相乘的结果为[36*32, 10, 1, 16], 此处的16应该就是输出向量的维度
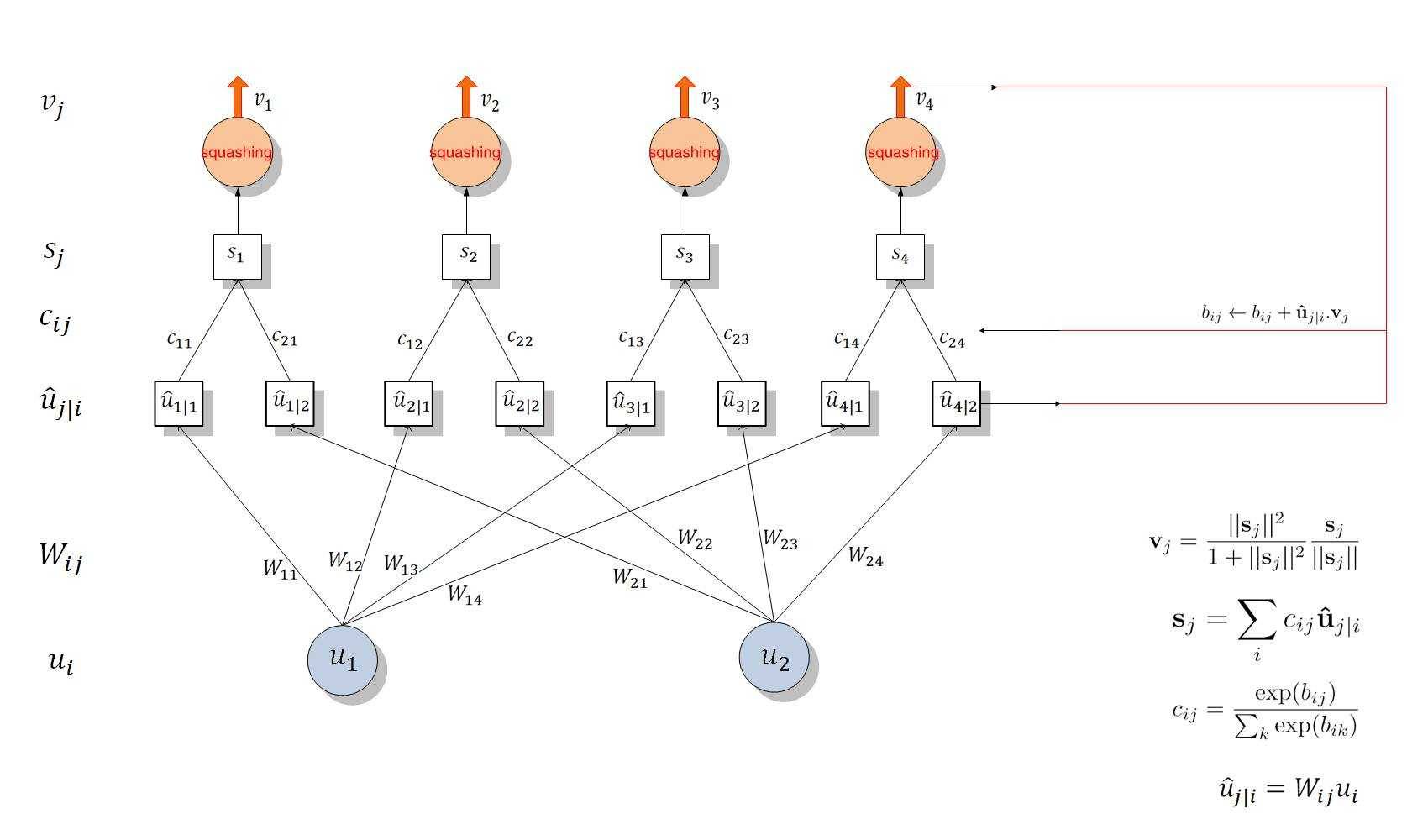
- 后面的处理与10这个维度有关系,在图中就是c_ij,需要构造的c_ij的数量为[36*32, 10,1],在一次整个网路的前向传播过程中,c_ij的初始值为0,会在一次前向传播过程中内部迭代几次,叫做动态路由算法。如下图所示:
- u_hat的维度为 [ 36*32, 10, 16],s的维度为[10, 16],v的维度为[10,16],这中间有将36*32个数相加的过程,更新c_ij是这样的:先将v变为[1,10,16],再计算u_hat*v得到[36*32, 10, 16],将里层维度相加,急求的是向量相乘,就会有方向的信息。由此更新c_ij
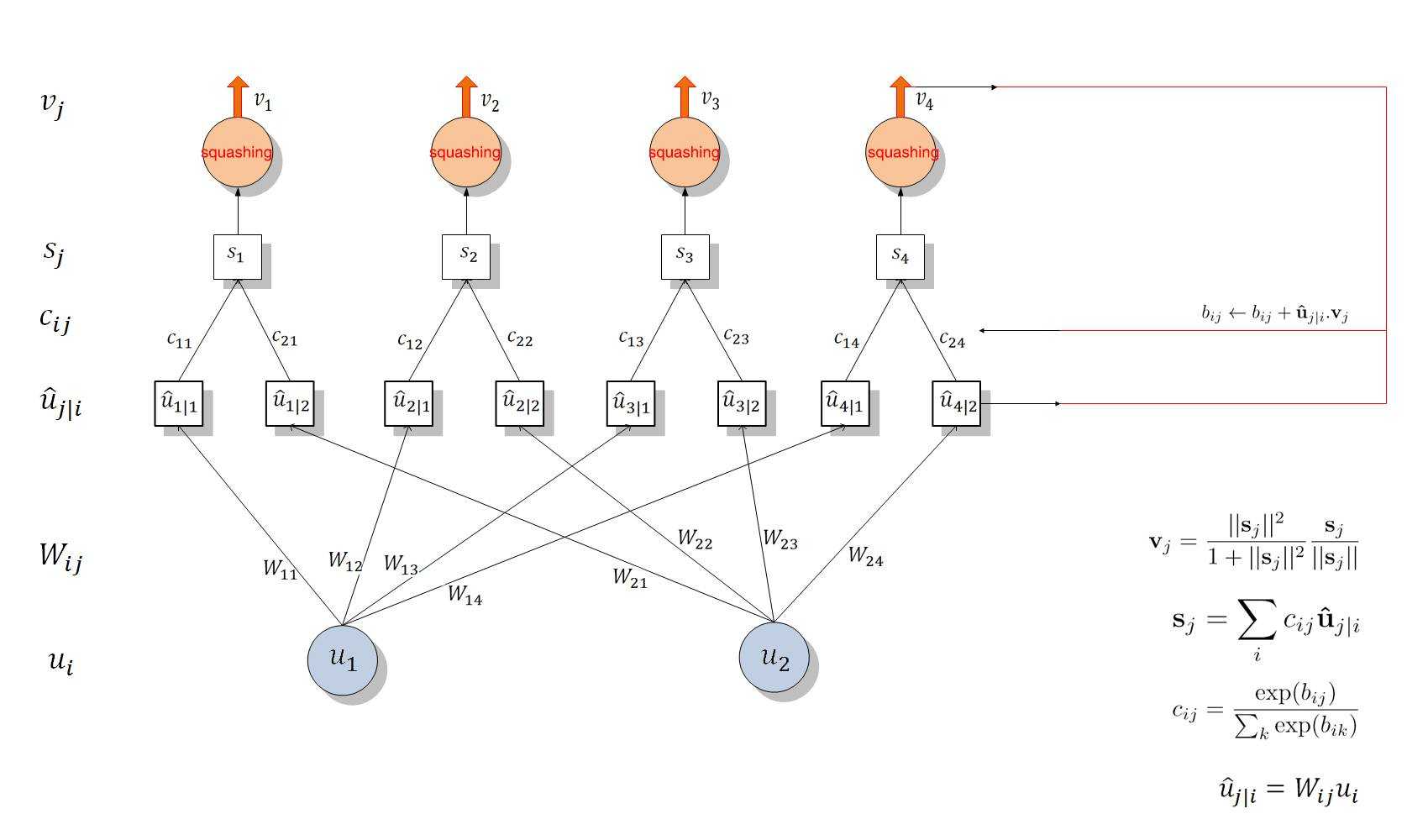
(注:该图来自于https://blog.csdn.net/wc781708249/article/details/80015997)
Decoder:
Decoder 部分是由三层全连接层组成的。
下面的维度忽略batch_size。
前面输出的是[10,16]
5、损失函数
对于CapsNet的基本原理,该博客给出了比较好的解释:http://www.cnblogs.com/CZiFan/p/9803067.html