日常工作中,很多职业者都会用到CAD文件,CAD是一种计算机辅助工具,在使用上很简单方便,但是工作上需要将CAD文件转换成PDF格式,要怎么操作呢?
针对整个问题小编收集并整理了以下2种转换方法,应该总有一种能够帮助到你。
一、极速玩转转换器
在PC端操作选择转换器的好处,除了本地转换无需上传下载外,一键批量转换也是非常省事和方便。
操作方法:
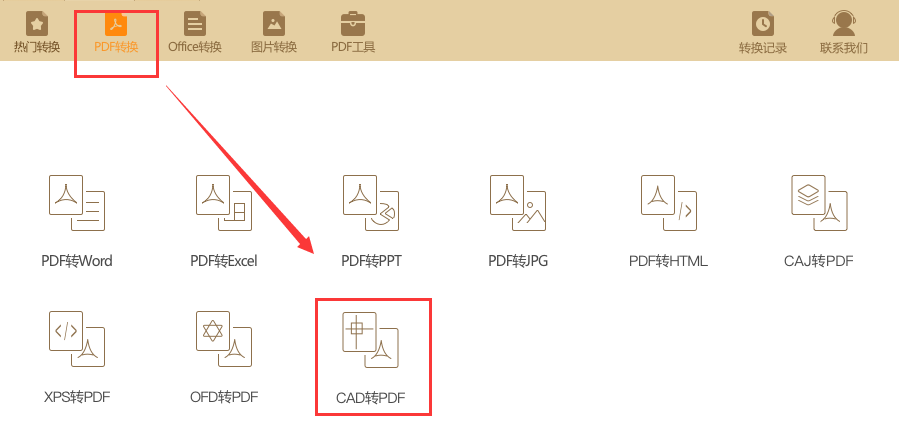
1、打开安装好的极速玩转,选择“PDF转换”中的“CAD转PDF”即可进入转换;
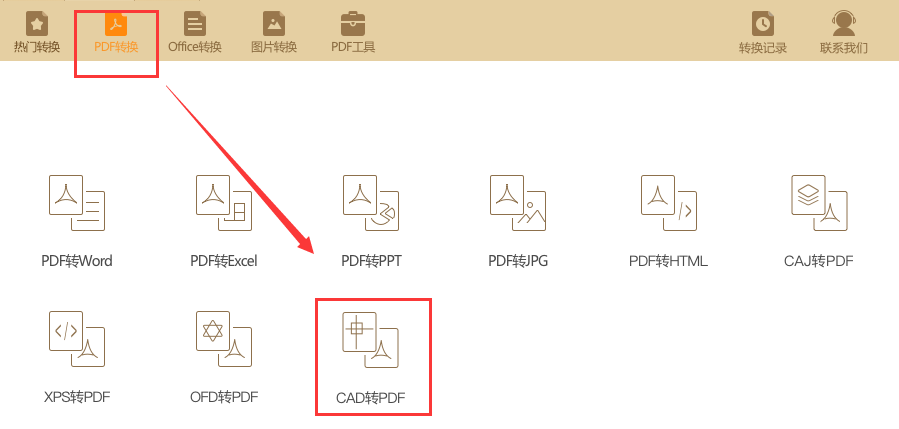
2、直接一键批量添加多个需要转换的CAD文档或直接将所有需要转换的文档全选后拖到转换页面,左下角的输出路径可以修改转换后文档的保存位置,最后点击右下角的开始转换即可一键转换。
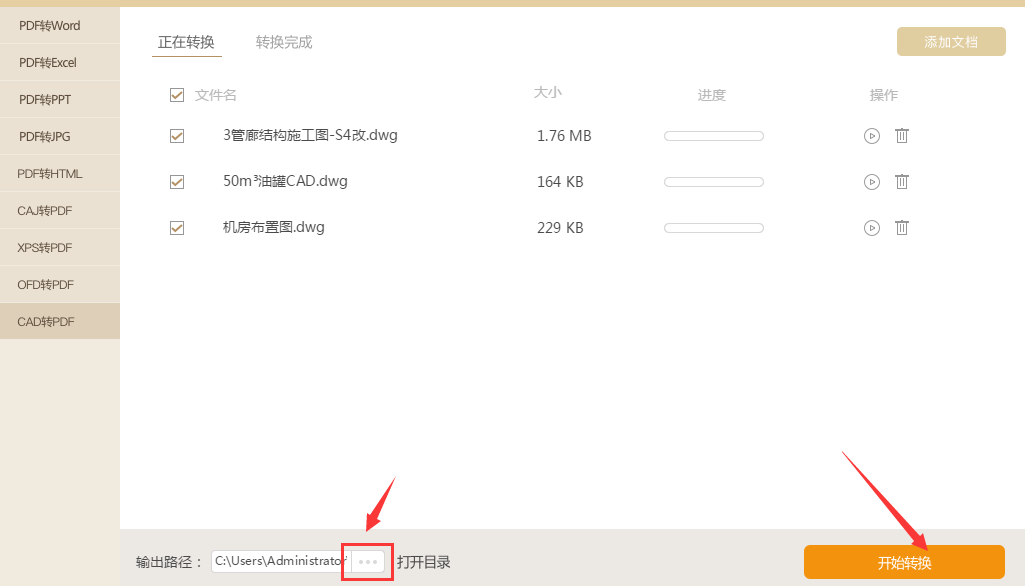
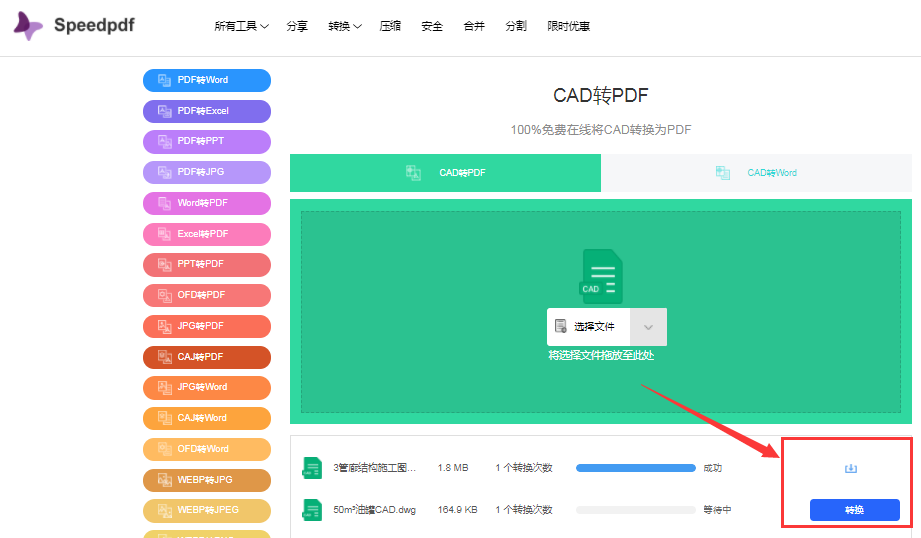
二、 speedpdf在线转换器
这是一个方便使用简单好看的PDF在线转换器,并且支持很多文件之间的互相转换,当然肯定也支持CAD转PDF。它能够打开PDF文件,上传PDF文件,快速的转换,正确的呈现文件效果。
操作方法:
1、搜索speedpdf进入后选择我们需要的CAD转PDF即可快速进行转换了。无需注册和登录也可以直接进行转换,但如果进行登录则可以在转换完成后在转换记录中查看并下载转换的文档。
2、接着就是添加并上传需要转换CAD的文档后,点击转换键开始转换,完成后直接下载就可以了。
总结:以上就是关于CAD如何转换成PDF的两个解决方法。总体来说,这些转换都是实用和简单,不仅帮我们处理了CAD转PDF格式,还可以进行其他文件的转换,有喜欢的或是对你有所帮助的可以尝试着这两种方法哦。