参考博客:
https://blog.csdn.net/weixin_44271378/article/details/107659287
解决办法:
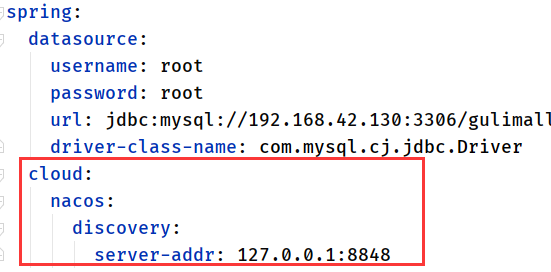
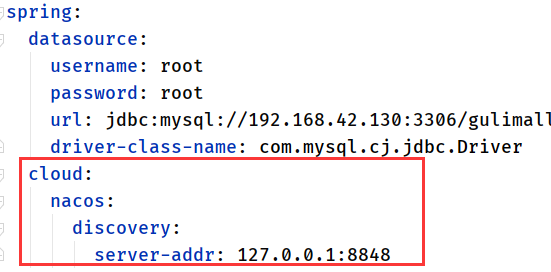
- 只是单纯的使用nacos作为服务的注册与发现, 不用来作为配置中心的话, 把config依赖删掉即可
- 既要使用nacos作为服务的注册与发现, 也要作为配置中心的话, 那么discovery配置和config配置一个都不能少
因为二者都需要,所以两者的依赖都得要,另外配置也需要(可以放在common模块里);
<!--服务注册与发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--配置中心来做配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
还需要添加如下配置
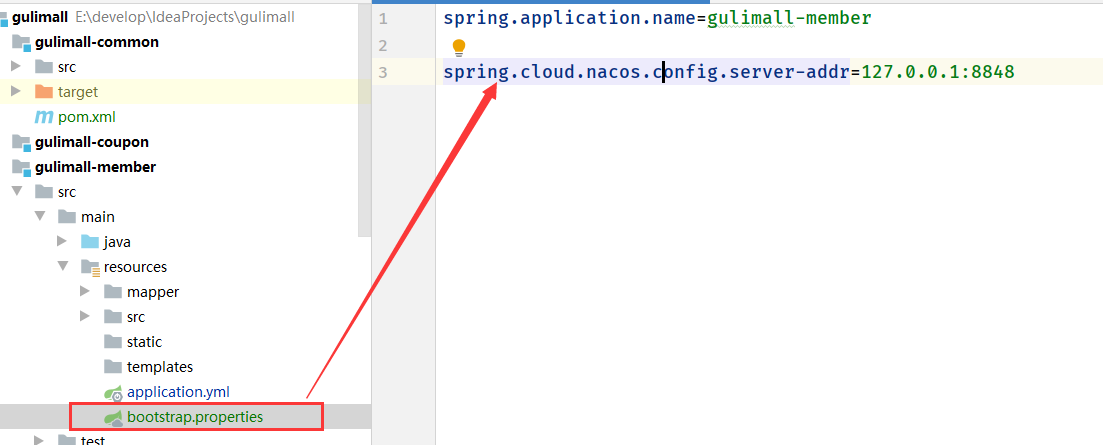
另外主启动类加上@EnableDiscoveryClient