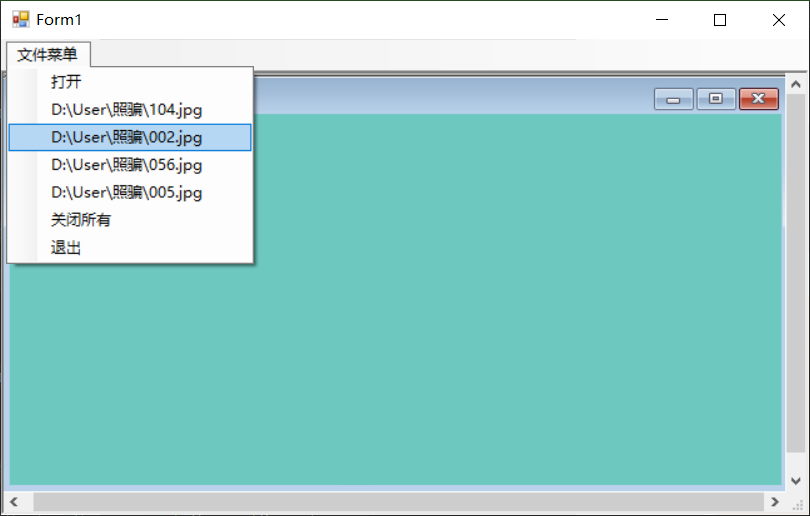
实例说明
在开发图纸管理软件时,要求在菜单上记录用户最近打开的档案或图纸,以方便下次使用。
单击“文件”菜单下的“打开文件”子菜单,打开需要查阅的图纸。下次运行该软件时,上次打开的文件名记录到“文件”菜单的历史菜单中,
选择该菜单上的历史选项,即可打开相应的图纸文件。
技术要点
要实现保存最近打开的文件,可以将在菜单中最近打开文件的文件名和路径保存到事先建立的*.ini文件中。
当系统启动或点击菜单时读取*.ini文件中的数据建立数组菜单,即可实现显示历史菜单的功能。
注意:
要建立一个带历史信息的菜单,必须首先添加一个MenuStrip菜单控件,并将主窗体的IsMdiContainer属性设为True。
实现过程
1. 创建一个项目,将其命名为Ex01_01,默认窗体为Form1。
2. 从工具箱中向Form1窗体添加MenuStrip控件,同时向窗体添加OpenFileDialog控件。
创建一个“文件”主菜单,在其下面创建打开、关闭所有、退出等菜单选项。
3. 主要程序代码。
自定义方法 ShowWiindows() 用来加载背景图片并显示窗体
1 public void ShowWindows(string fileName) 2 { 3 Image img = Image.FromFile(fileName); 4 Form f = new Form(); 5 f.MdiParent = this; 6 f.BackgroundImage = img; 7 f.Show(); 8 }
将打开的文件路径写入INI文件
1 private void 打开ToolStripMenuItem_Click(object sender, EventArgs e) 2 { 3 // 打开文件选择窗口 4 openFileDialog1.FileName = ""; 5 this.openFileDialog1.ShowDialog(); 6 // 写入INI文件 7 StreamWriter s = new StreamWriter(address + "\\Menu.ini", true); 8 s.WriteLine(openFileDialog1.FileName); 9 s.Flush(); 10 s.Close(); 11 // 调用方法显示文件(图片) 12 ShowWindows(openFileDialog1.FileName); 13 }
读取INI文件并将文件信息加入菜单
1 private void 文件菜单ToolStripMenuItem_Click(object sender, EventArgs e) 2 { 3 4 // 读取INI文件信息 5 StreamReader sr = new StreamReader(address + "\\Menu.ini"); 6 int i = this.文件菜单ToolStripMenuItem.DropDownItems.Count - 2; 7 while (sr.Peek() >= 0) 8 { 9 ToolStripMenuItem menuitem = new ToolStripMenuItem(sr.ReadLine()); 10 this.文件菜单ToolStripMenuItem.DropDownItems.Insert(i, menuitem); 11 i++; 12 menuitem.Click += new EventHandler(menuitem_Click); 13 } 14 sr.Close(); 15 }
实际操作
项目源码
1 using System; 2 using System.Drawing; 3 using System.IO; 4 using System.Windows.Forms; 5 6 namespace EX01_001 7 { 8 /// <summary> 9 /// 带历史信息的文件菜单(INI文件) 10 /// </summary> 11 public partial class Form1 : Form 12 { 13 public Form1() 14 { 15 InitializeComponent(); 16 } 17 18 /// <summary> 19 /// 用来记录当前的路径 20 /// </summary> 21 string address = System.Environment.CurrentDirectory; 22 23 private void Form1_Load(object sender, EventArgs e) 24 { 25 26 } 27 28 /// <summary> 29 /// 打开文件 30 /// </summary> 31 /// <param name="sender"></param> 32 /// <param name="e"></param> 33 private void 打开ToolStripMenuItem_Click(object sender, EventArgs e) 34 { 35 // 打开文件选择窗口 36 openFileDialog1.FileName = ""; 37 this.openFileDialog1.ShowDialog(); 38 // 写入INI文件 39 StreamWriter s = new StreamWriter(address + "\\Menu.ini", true); 40 s.WriteLine(openFileDialog1.FileName); 41 s.Flush(); 42 s.Close(); 43 // 调用方法显示文件(图片) 44 ShowWindows(openFileDialog1.FileName); 45 } 46 47 /// <summary> 48 /// 文件显示窗口 49 /// </summary> 50 /// <param name="fileName"></param> 51 public void ShowWindows(string fileName) 52 { 53 Image img = Image.FromFile(fileName); 54 Form f = new Form(); 55 f.MdiParent = this; 56 f.BackgroundImage = img; 57 f.Show(); 58 } 59 60 /// <summary> 61 /// 点击菜单时读取INI文件并将信息加入文件菜单 62 /// </summary> 63 /// <param name="sender"></param> 64 /// <param name="e"></param> 65 private void 文件菜单ToolStripMenuItem_Click(object sender, EventArgs e) 66 { 67 // 清除之前的历史信息 68 if (文件菜单ToolStripMenuItem.DropDownItems.Count > 3) 69 { 70 int j = 1; 71 while (文件菜单ToolStripMenuItem.DropDownItems.Count > 3) 72 { 73 文件菜单ToolStripMenuItem.DropDownItems.RemoveAt(j); 74 } 75 } 76 // 读取INI文件信息 77 StreamReader sr = new StreamReader(address + "\\Menu.ini"); 78 int i = this.文件菜单ToolStripMenuItem.DropDownItems.Count - 2; 79 while (sr.Peek() >= 0) 80 { 81 ToolStripMenuItem menuitem = new ToolStripMenuItem(sr.ReadLine()); 82 this.文件菜单ToolStripMenuItem.DropDownItems.Insert(i, menuitem); 83 i++; 84 menuitem.Click += new EventHandler(menuitem_Click); 85 } 86 sr.Close(); 87 } 88 89 /// <summary> 90 /// 菜单选项点击 91 /// </summary> 92 /// <param name="sender"></param> 93 /// <param name="e"></param> 94 private void menuitem_Click(object sender, EventArgs e) 95 { 96 ToolStripMenuItem Mymeun = (ToolStripMenuItem)sender; 97 ShowWindows(Mymeun.Text); 98 } 99 } 100 }
运行效果
*** | 以上内容仅为学习参考、学习笔记使用 | ***