参考资料:
https://www.jianshu.com/p/279f432deb0e
https://www.pconline.com.cn/win10/1113/11135714.html
这里涉及到两个host文件的位置,1. 真正的host文件 2. ssh登录时的known_hosts
1. 真正的host文件
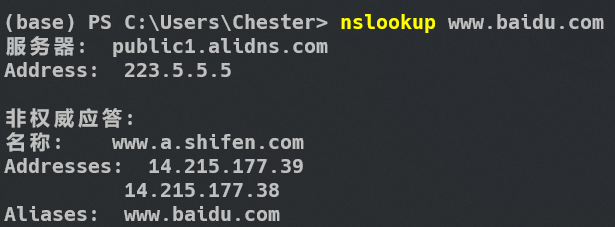
熟悉计算机网络的朋友应该会知道,DNS服务器的快慢很多时候决定了我们访问网页的速度。有些网站并不是被墙掉,而是域名被劫持,说白了就是DNS服务器不给力。此时可以通过手动在Hosts文件中添加表项的方法来直接告诉计算机,假如你想访问www.xxx.com,直接去 xxx.xxx.xxx 这个ip地址就对了比如下图所示:
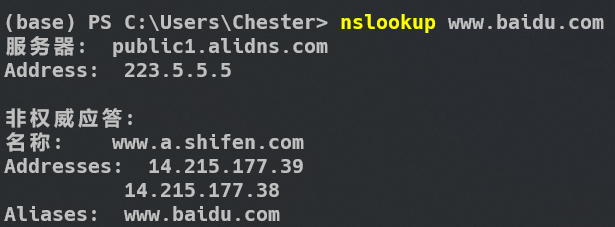
如果你想访问百度,直接去ip地址14.215.177.39是完全一样的。
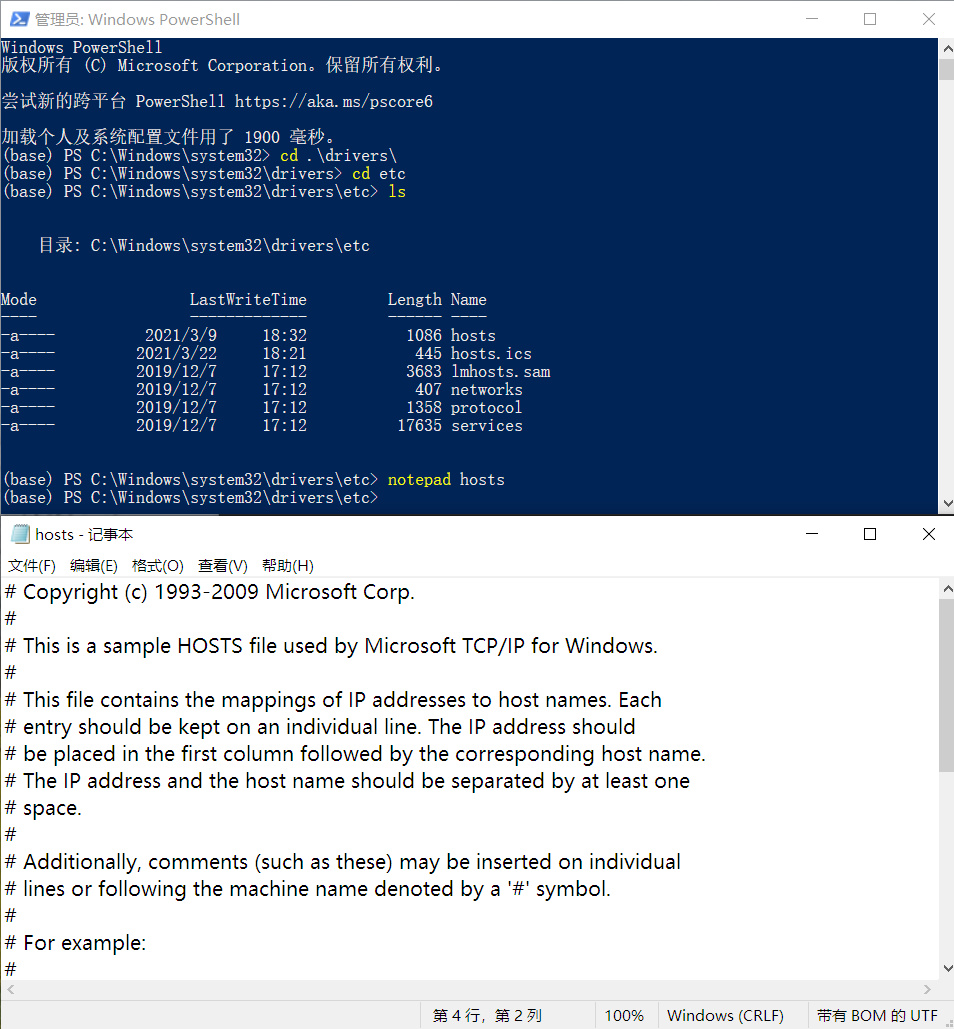
在Windows10系统中,hosts文件位于:C:\Windows\system32\drivers\etc\ 下,这个文件夹中的文件需要管理员权限才能访问。此时可以在菜单栏里面找到powershell软件,使用管理员身份打开,然后用下面的命令就可以使用记事本编辑了:
2. ssh登录时的known_hosts
要改这个文件的情况比较少见。众所周知ssh是使用数字证书的,也就是公私钥。当你使用ssh访问一个服务器后,你的电脑上就会记住他的公钥,如果在下一次访问的时候发现公钥发生了变化,电脑就会强制中断连接。这就叫做防止身份冒用。
window10中这个文件的位置就在用户的主文件夹下,当远程主机重装导致ssh识别不了时,把这个文件删除即可。
C:/用户/你的用户名/.ssh/known_hosts