Skip to content
California, TX 70240 | (1800) 456 7890
云博客
云博客
前端
windos
微信
数据库
移动开发
技术杂谈
前端
windos
微信
数据库
移动开发
技术杂谈
Home
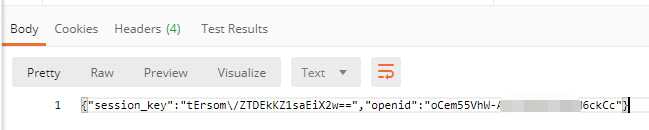
微信小程序session_key解析中反斜杠问题处理 Java解析
4500e58565275d79c6cacf80dd7bbd40.jpg
4500e58565275d79c6cacf80dd7bbd40.jpg
发表回复
要发表评论,您必须先
登录
。